

From time to time, and for whatever reasons, we all experience it: duplicate values appear in a table for a field that should be unique. For me, this issue recurs because of an application that tries to simultaneously insert records into tables in 2 separate databases that are supposed to contain identical data, but don't always. If the items (pharmaceuticals and over-the-counter pharmacy items) get out of sync between my two databases, the said application's insert routine fails because one of the tables may already contain the item_no value that it is attempting to insert (the table has a unique index on that field). My quick resolution in this situation is to:
- Remove the unique index temporarily;
- Run the application, allowing it to insert duplicate item(s); then
- find the duplicate(s) and remove them.
Of course, these steps are preceded by performing a good backup of the database and possibly putting the database in single user mode to prevent unexpected query results during my work. As simple as the task of removing a record with a duplicate value sounds, it can get confusing, and I need to proceed with care. To be safe, I follow this rule of thumb: first I perform a SELECT of the record(s) that will be removed, then I convert it to a DELETE statement after I'm sure it will affect only record(s) that I want it to.
My table, named item_store, has an id field and an item_no field. I suspect that it contains duplicated data in the item_no field when I run the application. A simple GROUP BY statement can give me an immediate count of duplicated items (items with the same item_no value):
SELECT item_no FROM item_store GROUP BY item_no HAVING COUNT(item_no)>1 GO
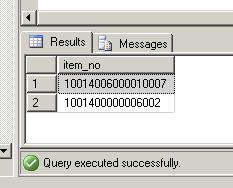
This lets me know that there are 2 items that have duplicated item_no field values. However, this doesn't tell me how many records contain duplicated values, and it certainly doesn't remove the records. The table contains an auto-incremented primary key (id), so my job is easy. Now I'll run a SELECT statement to see which item_no values don't fall into a result set when I query the MIN (or MAX) value for each group of item_no values (there should only be one per group!):
SELECT * FROM item_store WHERE id NOT IN ( SELECT MIN(id) FROM item_store GROUP BY item_no ) GO
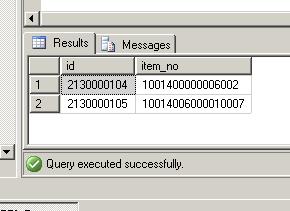
And there I see the actual duplicated record ids. I can now remove them by id or simply run a modification of the previous script:
DELETE item_store WHERE id NOT IN ( SELECT MIN(id) FROM item_store GROUP BY item_no ) GO
What if the duplicated records are pre-existing before the auto-increment functionality was put in place, and the entire record (every field) is duplicated? In this case, my script that finds MIN values is useless. One method to fix this without having to rename and delete whole tables is to:
- copy the duplicate records into a temporary table
- remove all records that are duplicated (no trace of those ids left) from the original table
- copy them back (now single instances of each record) from the temporary table
SELECT id, item_no INTO #tmp FROM item_store GROUP BY item_no, id HAVING COUNT(*) > 1 GO
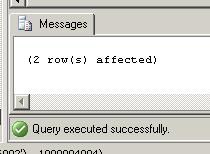
DELETE item_store WHERE id IN ( SELECT id FROM #tmp ) GO
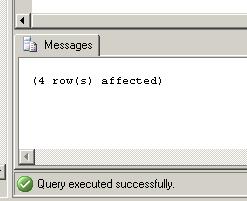
INSERT INTO item_store SELECT * FROM #tmp GO
DROP TABLE #tmp GO
Now I check one last time to make sure that no duplicates appear:
SELECT item_no FROM item_store GROUP BY item_no HAVING COUNT(item_no)>1 GO
Keep in mind that when using the last method, every column name has to be listed in the statement that copies the duplicates into the temporary table (SELECT id, item_no INTO #tmp FROM...). This can be painful if there are 10+ fields in the table. If you have a table with 100 fields, you'll want to rename the table, select all DISTINCT records from the renamed table into the original table name (a table is automatically created using SELECT...INTO...FROM...), then drop the temporary table. Bill Graziano gives a great example on this in his article at http://www.sqlteam.com/article/deleting-duplicate-records. I've customized his script below for my scenario:
sp_rename 'item_store', 'temp_item_store' GO
SELECT DISTINCT * INTO item_store FROM temp_item_store GO
DROP TABLE temp_item_store GO
Be aware that when using the above method, any constraints and indexes will be lost. If you are careful to save the index and constraint CREATE statements beforehand, you can re-create them.
Now you can confidently remove duplicate records from your tables!
