

Introduction:
Before you take exception to the title, I agree... there are no true arrays in SQL Server.
It seems like there's been a flurry of recent articles about how to pass "arrays" and "tables" of information to SQL Server as well as a bunch of "How do I split this?" posts. Some folks use While loops and, if they have SQL Server 2005, some use XML for the task. I thought I'd throw my hat into the ring, as well.
Using my old friend, the "Tally" table, we'll build "splits" for 1, 2, and 3 Dimensional "arrays". Most of the examples will work in SQL Server 2000 and, of course, some will only work in SQL Server 2005. I'll flag things when they are 2k5 only. We'll even make these "arrays" in a "generic" fashion based on the different delimiters of the passed parameter so you don't actually have to know the size of the array ahead of time... it'll just figure it out based on the delimiters in the parameter. We'll also "refactor" 2 Dimensional parameters back into actual table structures.
I was going to do some performance tests between the XML and the Tally table methods but a relative "new comer" to SQL Server Central by the name of Antonio Collins has produced an outstanding set of tests that rival even what the old salts do. Those tests can be see at the following URL...
http://www.sqlservercentral.com/Forums/Topic478799-338-1.aspx#bm478799
Basically, the tests show that the Tally table will usually beat the XML split method even on a fairly complicated split. None of our splits are going to be "complicated", though. Beyond that testing, one recent shocker for me while I was writing this article is that a "Tally CTE" used during a split is actually faster that a Tally Table by about a 10th of a second for the larger splits (8001 elements in a single parameter).
One final note... I used the 1 dimensional split found in this article in the previous article titled "The "Numbers" or "Tally" Table: What it is and how it replaces a loop." It was a very good way to explain how the Tally table worked. I cover almost the same thing in this article because it is an article about splitting parameters and the like. Although I did try to put a slightly different slant on it, I apologize for the necessary duplication in some areas.
How to Make a Tally Table (SQL Server 2000 or 2005)
I have a script to make a Tally table at the following URL...
http://www.sqlservercentral.com/scripts/Advanced+SQL/62486/
... but the Tally table is so important to the splitting process, that I figured I'd post it here, as well.
--Create a Tally Table --===== Create and populate the Tally table on the fly
SELECT TOP 11000 --equates to more than 30 years of dates
IDENTITY(INT,1,1) AS N
INTO dbo.Tally
FROM Master.dbo.SysColumns sc1,
Master.dbo.SysColumns sc2 --===== Add a Primary Key to maximize performance
ALTER TABLE dbo.Tally
ADD CONSTRAINT PK_Tally_N
PRIMARY KEY CLUSTERED (N) WITH FILLFACTOR = 100 --===== Allow the general public to use it
GRANT SELECT ON dbo.Tally TO PUBLIC
For those who aren't familiar with a Tally table (some folks call it a "Numbers" table), it contains nothing more than a single column of well indexed numbers usually starting at "1" (some start at "0") and going up to some maximum number. The maximum number is not arbitrary... I keep an 11,000 row table not only because it's larger than VARCHAR(8000) (where splits normally occur in SQL Server 2000), but because I also use it to generate dates. There are almost 11,000 days in 30 years worth of dates.
With the advent of VARCHAR(MAX) in SQL Server 2005, some folks keep a million row Tally table. That seems a bit much, especially if you want it to cache in memory. Besides, there's a neat trick you can use to replace the Tally table in 2k5. The work-around to maintaining such a "large" Tally table is in the form of a CTE that is created based on the number of characters in the parameter to be split. For example...
--Use a CTE as a Tally table for a Split --===== Simulate a large CSV parameter of unknown length
DECLARE @SomeCSVParameter VARCHAR(MAX)
-- This will make a parameter of 28,000 characters for test
SET @SomeCSVParameter = REPLICATE(CAST('123456,' AS VARCHAR(MAX)),4000) ;WITH
cteTally AS
(--==== Create a Tally CTE from 1 to whatever the length
-- of the parameter is
SELECT TOP (LEN(@SomeCSVParameter))
ROW_NUMBER() OVER (ORDER BY t1.Object_ID) AS N
FROM Master.sys.All_Columns t1
CROSS JOIN Master.sys.All_Columns t2
)
SELECT * -- this will be replaced by "split" code
FROM cteTally
Believe it or not, even though it doesn't have an index, I've found lately that this method frequently beats the Tally table for performance on "Monster Splits" that use VARCHAR(MAX). The Tally table method still wins on splits that are done on VARCHAR(8000).
Anatomy of a "Simple" or 1 Dimensional Split
There are several steps to splitting a parameter... you have to "normalize" the parameter to make the split code simpler and faster, do the split, and then return the split result as a single result set to be useful...
"Normalizing" the Elements in the Parameter (SQL Server 2000 or 2005)
A 1 Dimensional parameter is what most people end up needing to split. Further, 2 and 3 Dimensional splits actually start out with a 1 Dimensional split so, "Normalizing" a parameter is appropriate and necessary for all the methods in this article.
A parameter is normally passed as some length of VARCHAR and each "element" is frequently separated from the others by commas. There can be almost any number of elements from 0 to as many as are needed. The trouble is, the first and last element look differently than the ones in the middle. Consider the following graphic...
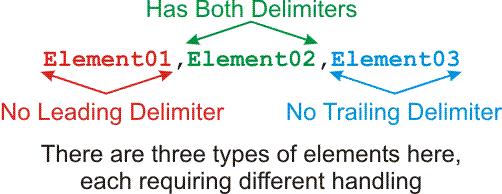
Element01 has no leading delimiter and Element03 has no trailing delimiter. All three elements look differently. All three elements must be handled differently. That's going to require extra code not only to handle them differently, but also to detect if the current element being split is the first element, the last element, or a "middle" element like Element02. And, what if we only have 1 element? It's typically passed with no delimiters at all...

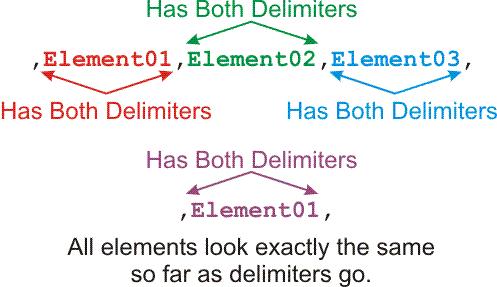
And, to top it off, a single element can also be just a blank. What can be done to make ALL elements look identical so they can all be processed the same way without writing a bunch of special code to handle each element type? The answer is simple... add a single delimiter to the very beginning and another to the very end of the parameter string. Then, all elements, regardless of position in the parameter string, will look identical as in the following graphic...
The Principle of Splitting (Doing the Split - SQL Server 2000 or 2005)
Once the elements are "normalized", splitting becomes child's play. All you have to do is find the first comma (always at character position #1), use CHARINDEX to find the first comma after that (trailing comma), and everything in between is the element you want to split out. Then, use the trailing comma as the leading comma for the next element and repeat the process. This "leapfrogging" continues until you run out of elements to process as identified when the leading comma of the current element to be split is the last comma in the string (ie. you run out of elements to process).
Here's one very fast method of doing that with a WHILE loop (I used a WHILE loop here just to explain the process more simply, no hate mail, please)...
--Split a 1 Dimensional Parameter Using a WHILE Loop --===== Simulate a passed parameter
DECLARE @Parameter VARCHAR(8000)
SET @Parameter = 'Element01,Element02,Element03' --===== Declare a variable to remember the position of the current
-- leading comma
DECLARE @N INT --===== Add start and end commas to the Parameter so we can handle
-- all elements the same
SET @Parameter = ','+@Parameter +',' --===== Pre-assign the current comma as the first character
SET @N = 1 --===== Loop through and find each comma, then select the string value
-- found between the current comma and the next comma. @N is
-- the position of the current comma.
WHILE @N < LEN(@Parameter) --Don't include the last comma
BEGIN
--==== Select the value between the commas
SELECT (SUBSTRING(@Parameter,@N+1,CHARINDEX(',',@Parameter,@N+1)-@N-1))
--==== Find the next comma
SELECT @N = CHARINDEX(',',@Parameter,@N+1)
END
Go ahead... run it. Heh... see what happened? Multiple result sets. Not good. Let's fix that...
Returning the Split in a Single Result Set (SQL Server 2000 or 2005)
Sure, the While loop worked just fine. But, the previous example is RBAR on steroids! It executes 1 SELECT for every element! It doesn't return 1 result set containing the split... it returns 3! The only way we can get this to return a single result set is to INSERT into either a Temp Table or a Table Variable and then SELECT from that temporary storage. Like this...
--Returning a Split as a Single Result Set Using a While Loop --===== Simulate a passed parameter
DECLARE @Parameter VARCHAR(8000)
SET @Parameter = 'Element01,Element02,Element03' --===== Create a table to store the results in
DECLARE @Elements TABLE
(
Number INT IDENTITY(1,1), --Order it appears in original string
Value VARCHAR(8000) --The string value of the element
) --===== Declare a variable to remember the position of the current
-- leading comma
DECLARE @N INT --===== Suppress the auto-display of rowcounts to keep them from being
-- mistaken as part of the result set.
SET NOCOUNT ON --===== Add start and end commas to the Parameter so we can handle
-- all elements the same
SET @Parameter = ','+@Parameter +',' --===== Preassign the current comma as the first character
SET @N = 1 --===== Loop through and find each comma, then insert the string value
-- found between the current comma and the next comma. @N is
-- the position of the current comma.
WHILE @N < LEN(@Parameter) --Don't include the last comma
BEGIN
--==== Do the insert using the value between the commas
INSERT INTO @Elements
VALUES (SUBSTRING(@Parameter,@N+1,CHARINDEX(',',@Parameter,@N+1)-@N-1))
--==== Find the next comma
SELECT @N = CHARINDEX(',',@Parameter,@N+1)
END --===== Display the split as a single result set
SELECT * FROM @Elements
THAT gives us the following as a single result set...
| Number | Value |
|---|---|
| 1 | Element01 |
| 2 | Element02 |
| 3 | Element03 |
... and for what it does, it's still RBAR on steroids because it still does one INSERT for every element in the parameter. It's also getting to be some fairly lengthy code!
Using the Tally Table to do the Split (SQL Server 2000 or 2005)
If you haven't used a Tally table before, check my previous article on how a Tally table actually works to replace counter loops, like in the example above, at the following URL. This is where some of the duplication of information I spoke of in the introduction comes into play.
http://www.sqlservercentral.com/articles/TSQL/62867/
So, let's use a Tally table to do the split. We're going to use the exact same principle that the WHILE loop used... Find the first comma (always at character position #1), use CHARINDEX to find the first comma after that (trailing comma), and everything in between is the element you want to split out. Then, use the trailing comma as the leading comma for the next element and repeat the process. This "leap frogging" continues until you run out of elements to process as identified when the leading comma of the current element to be split is the last comma in the string. The difference with the Tally table is that we're going to find every leading comma (except the last one) instead of remembering what the trailing comma was. Here's the code...
--Use a Tally Table to Replace the While Loop in a Split --===== Simulate a passed parameter
DECLARE @Parameter VARCHAR(8000)
SET @Parameter = 'Element01,Element02,Element03' --===== Suppress the auto-display of rowcounts to keep them from being
-- mistaken as part of the result set.
SET NOCOUNT ON --===== Add start and end commas to the Parameter so we can handle
-- single elements
SET @Parameter = ','+@Parameter +',' --===== Join the Tally table to the string at the character level and
-- when we find a comma, select what's between that comma and
-- the next comma into the Elements table
SELECT SUBSTRING(@Parameter,N+1,CHARINDEX(',',@Parameter,N+1)-N-1)
FROM dbo.Tally
WHERE N < LEN(@Parameter) --Don't include the last comma
AND SUBSTRING(@Parameter,N,1) = ',' --Notice how we find the comma
Notice that the formula for finding the string between commas is almost identical to the way we did it in the loop. The only thing that changed is that we're using the "N" column from the Tally table instead of the "@N" variable that we used in the WHILE loop. Notice the WHERE clause... we still don't include the last comma. Using the SUBSTRING, we're actually joining the Tally table to the parameter string at the single character level to find the commas. It all runs very fast and the code is a heck of a lot shorter.
If we also want to get the element number, like the WHILE loop example did, in SQL Server 2000, we still need to insert into temporary storage, but instead of separate inserts, it now uses only one regardless of how many elements there are in the parameter. Like this...
--Add Element Numbers to the Tally Table Split --===== Simulate a passed parameter
DECLARE @Parameter VARCHAR(8000)
SET @Parameter = 'Element01,Element02,Element03' --===== Create a table to store the results in
DECLARE @Elements TABLE
(
Number INT IDENTITY(1,1), --Order it appears in original string
Value VARCHAR(8000) --The string value of the element
) --===== Suppress the auto-display of rowcounts to keep them from being
-- mistaken as part of the result set.
SET NOCOUNT ON --===== Add start and end commas to the Parameter so we can handle
-- single elements
SET @Parameter = ','+@Parameter +',' --===== Join the Tally table to the string at the character level and
-- when we find a comma, insert what's between that comma and
-- the next comma into the Elements table
INSERT INTO @Elements (Value)
SELECT SUBSTRING(@Parameter,N+1,CHARINDEX(',',@Parameter,N+1)-N-1)
FROM dbo.Tally
WHERE N < LEN(@Parameter)
AND SUBSTRING(@Parameter,N,1) = ',' --Notice how we find the comma --===== Display the split as a single result set
SELECT * FROM @Elements
By the way... notice that when I use the Tally table, I don't use an ORDER BY N anywhere. The reason for that is that N has a clustered index on it. Since the Tally table is never modified, it guarantees the correct order of 1 to whatever. However, if it makes you more comfortable because you follow the rule that "only ORDER BY can guarantee the order", then go ahead and add it to the code. It won't slow anything down because, it won't actually be used by the optimizer. No kidding! It won't change a thing in the execution plan. It'll be there just for the warm fuzzy feeling that you used an ORDER BY.
Single Dimension "Monster" Splits (SQL Server 2005 only)
We already saw some code on this subject earlier in the article. And, like I said earlier, this method will usually beat the Tally table method for these "Monster" splits (Tally table still wins on VARCHAR(8000)).
Every once in a while, there's the requirement for a split of more than what a VARCHAR can hold. If you have an understanding DBA, perhaps (s)he'll let you have a much larger Tally table of a million rows or so waiting in the wings. If (s)he's not so understanding, you're either out of luck, or you can make one on the fly using a CTE. Let me say it again... a properly written Tally CTE will usually beat a Tally Table on "Monster" splits. There's really no need to maintain super-sized Tally tables any more (heavy sigh/sob).
Challenge if you like, I've seen a lot of different ways to make a "Tally CTE" including many "internally generated numeric cross joins", but I've never found a faster one nor an easier one to remember than the method that follows (don't even think of using recursion for this... it's way too slow!). If you have one, I'm all for learning new things... please post it. Thanks.
This method uses a Cross-Join on a table that's guaranteed to have at least 4k rows in it even on a brand new installation. 4k cross-joined with 4k makes a minimum of 16 MILLION rows... if you need more than that, you can just add another cross-join to the same table for a total of at least 64 BILLION rows. Yeah... we'll all wait for that 😉
Ok, enough of that... like I said, using the same exact split formulas we used with the Tally table, here's how to do the "monster"split (or any other split) using a "Tally CTE" instead of a Tally table...
--"Monster" Split in SQL Server 2005 --===== Simulate a large CSV parameter of unknown length
DECLARE @Parameter VARCHAR(MAX)
-- This will make a parameter of 56,000 characters for test
-- Note that this will actually make a return of 8001 splits
-- because of the left over trailing comma that I didn't take
-- the time to fix in the example parameter.
SET @Parameter = REPLICATE(CAST('123456,' AS VARCHAR(MAX)),8000) --===== Add start and end commas to the Parameter so we can handle
-- all the elements the same way
SET @Parameter = ','+@Parameter +',' SET STATISTICS TIME ON --Measure the time, just for fun ;WITH
cteTally AS
(--==== Create a Tally CTE from 1 to whatever the length
-- of the parameter is
SELECT TOP (LEN(@Parameter))
ROW_NUMBER() OVER (ORDER BY t1.Object_ID) AS N
FROM Master.sys.All_Columns t1
CROSS JOIN Master.sys.All_Columns t2
)
SELECT ROW_NUMBER() OVER (ORDER BY N) AS Number,
SUBSTRING(@Parameter,N+1,CHARINDEX(',',@Parameter,N+1)-N-1) AS Value
FROM cteTally
WHERE N < LEN(@Parameter)
AND SUBSTRING(@Parameter,N,1) = ',' --Notice how we find the comma SET STATISTICS TIME OFF
That split a parameter of 8001 elements and returned them all to the grid in less than a second... CPU time was right at a quarter second. Using a 64k Tally table took about a 10th of a second longer for both times.
Notice that the cteTally only contains enough rows to split whatever parameter we throw at it because of the TOP (LEN(@Parameter)). Also notice, no explicit temporary storage... Because of ROW_NUMBER() in the final SELECT, we can get the element number without ever going near a declared Temp Table or Table Variable. That doesn't help TempDB because the CTE is still grown there just like a derived table may be, but it sure does make the code a lot simpler.
Once again, I've not used an ORDER BY N here. The ROW_NUMBER() OVER in the CTE takes care of that. And, once again, if it makes you feel better to see it in the code, you can add it with no impact.
Multi-Dimensional Splits
Like Bill Cosby once said while telling the great story about "Fat Albert", I've gotta say, "Ok... I told you that story so I could tell you this one"...
In no way will I promise you "N" Dimensional Splits... but I can show you how to do 2 and 3 dimensional splits. I'll even show you how to how to "refactor" a 2 dimensional split into a table. I leave how you want to handle a 3 dimensional split, after the split, up to you.
Introduction to "Arrays"
Rather than write something myself about what an array is, here's a quote from WikiPedia (ref URL included)...
(from http://en.wikipedia.org/wiki/Array )
"In computer science, an array is a data structure consisting of a group of elements that are accessed by indexing. In most programming languages each element has the same data type and the array occupies a contiguous area of storage. Most programming languages have a built-in array data type. Some older languages referred to arrays as tables."
About the closest thing to an "array" data-type in SQL Server is a Table. Still, we sometimes need to pass multi-dimensional parameters from a GUI to SQL Server. Splitting them is a piece of cake. Reassembling them into a table or using them with "indexing" (think by row number, column number, and, in the case of 3 dimensional arrays, by "page" number) is something else altogether. But, with a little help from some very simple math, we can build those indices (not to be confused with indexes in SQL Server that are made with CREATE INDEX) without much trouble at all. We just have to follow a couple of rules derived from the definition above as to what an array is. Like any good table, that means that each row must have the same number of columns and each column must be of the same datatype.
In many programming languages (even Excel VBA), you can "talk to" a single element of an array just by listing the "row" and "column" of the array. For example, you might say LET A = B(r,c) for a 2 dimensional array or, in the case of a 3 dimensional array, LET A = B(r,c,p) where "r" stands for "row", "c" stands for column, and "p" stands for page. (Note that Mathematicians refer to rows and columns simply as "i" and "j".)
Let's see how to split multi-dimensional parameters and give them such an addressing system.
2 Dimensional Splits.
Let's just say that we have a parameter that is supposed to pass the Part Number, Part Name, and Quantity ordered for multiple parts. Bingo... that's a 2 Dimensional parameter. Like any good table, each "row" (group of 3 elements) is all about 1 part and each column (element in a group) is some attribute for that part and always has the same data type.
We also have to assume (rather... demand from the GUI developer) that the parameters will always be passed in multiples of 3 elements... one for Part Number, one for Part Name, and one for Quantity ordered and that they will always be passed in that order. Without those rules in place, they're not passing an array, they're passing a mess. 😉
For human readability, they decide to separate each group of three with the pipe "|" character and each attribute (element) within the group with a comma. For testing purposes, let's say the 2 Dimensional parameter that we need to split looks like this...
--===== Simulate a passed parameter
DECLARE @Parameter VARCHAR(8000)
SET @Parameter = 'Part#1,PartName1,1|Part#2,PartName2,2|Part#3,PartName3,3'
So, we have 3 parts with the 3 attributes of Part Number, Part Name, and Quantity ordered in a 2 Dimensional parameter. First, we'll use the different delimiters to determine how many elements there are per group. Then, because we no longer care about what a delimiter looks like, we'll change all the pipe delimiters to commas just to make the code easy. We'll do the very same split we did with the 1 Dimensional parameter and that's where the similarity ends. We'll do an update on the @Elements table to calculate and store the row and column number references (indices) using some really simple math against the IDENTITY column. Finally, we'll do a SELECT from the table to display the result of our efforts. Here's all the code... as usual, the details are in the comments...
--2D Split with "Zero" Based Indices --===== Simulate a passed parameter
DECLARE @Parameter VARCHAR(8000)
SET @Parameter = 'Part#1,PartName1,1|Part#2,PartName2,2|Part#3,PartName3,3' --===== Create a table to store the results in
DECLARE @Elements TABLE
(
ElementNumber INT IDENTITY(1,1), --Order it appears in original string
ElementValue VARCHAR(8000), --The string value of the element
RowNum INT, --One of the two indices
ColNum INT --One of the two indices
) --===== Declare a variable to store the number of elements detected in each group
-- of the input parameter
DECLARE @GroupCount INT --===== Suppress the auto-display of rowcounts to keep them from being
-- mistaken as part of the result set.
SET NOCOUNT ON --===== Determine the number of elements in a group (assumes they're all the same)
SELECT @GroupCount =
-- Find the length of the first group...
LEN(SUBSTRING(@Parameter,1,CHARINDEX('|',@Parameter)))
-- ... subtract the length of the first group without any commas...
- LEN(REPLACE(SUBSTRING(@Parameter,1,CHARINDEX('|',@Parameter)),',',''))
-- ... and add 1 because there is always 1 element more than commas.
+ 1 --===== Add start and end commas to the Parameter and change all "group"
-- delimiters to a comma so we can handle all the elements the same way.
SET @Parameter = ','+REPLACE(@Parameter,'|',',') +',' --===== Join the Tally table to the string at the character level and
-- when we find a comma, insert what's between that comma and
-- the next comma into the Elements table
INSERT INTO @Elements (ElementValue)
SELECT SUBSTRING(@Parameter,N+1,CHARINDEX(',',@Parameter,N+1)-N-1)
FROM dbo.Tally
WHERE N < LEN(@Parameter)
AND SUBSTRING(@Parameter,N,1) = ',' --Notice how we find the comma --===== Calculate and update the "row" and "column" indices
UPDATE @Elements
SET RowNum = (ElementNumber-1)/@GroupCount, --"Zero" based row
ColNum = (ElementNumber-1)%@GroupCount --"Zero" based col --===== Display the final result of the split and the
-- index calculations
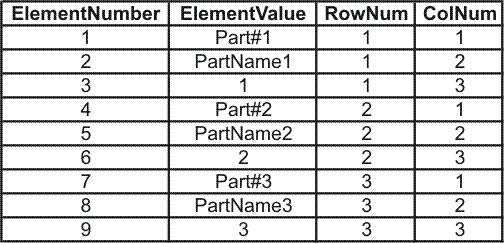
SELECT * FROM @Elements
That returns the following and, since most folks that use an array never look at the array, no further formatting is required...

You should notice that the row and column numbers are "zero" based. That is, they both start with the number "0". If you want a "unit" or "one" based array, simply add +1 to the right most side of the two formulas. In other words, change the update to look like this...
--Changes for 2D Split with "Unit" Based Indices --===== Calculate and update the "row" and "column" indices
UPDATE @Elements
SET RowNum = (ElementNumber-1)/@GroupCount+1, --"Unit" based row
ColNum = (ElementNumber-1)%@GroupCount+1 --"Unit" based col
... and the return will look like this...
Another "trick" you could employ is to make "calculated columns" in the table definition so that you don't need to do the final update.
Refactoring the 2 Dimensional Split to a Table
The returns in the 2 Dimensional splits are sometimes referred to as "EAV's" or "Entity, Attribute, Value" tables. They're long and skinny and respond very well to a covering index. I normally leave them like they are because I don't really care what they look like when I use them.
Still, some folks have got to have them in a more "normal" table form. So, with a little help from another of my favorite tools, the "Cross-tab", let's put this 2 Dimensional result set into a more table-like form. I won't actually insert it into a table, but you certainly could. Further, I'm only going to show the SELECT instead of repeating all of the split code. Just replace the final SELECT in the split code with the following. Refer to Books Online for how "Cross-tabs" work...
--Convert 2D Split to a Table --===== Display the final result of the split and the
-- index calculations as a "table" instead of an "EAV"
SELECT MAX(CASE WHEN ColNum = 1 THEN ElementValue END) AS PartNumber,
MAX(CASE WHEN ColNum = 2 THEN ElementValue END) AS PartName,
MAX(CASE WHEN ColNum = 3 THEN ElementValue END) AS QtyOrdered
FROM @Elements
GROUP BY RowNum
... and that produces something that folks are more accustomed to looking at...

If you want, you could certainly add RowNum to the SELECT list. In SQL Server 2005, you could probably use PIVOT to flip this around instead of a Cross-Tab, but I wanted to write something that could be used in both SQL Server 2000 and 2005. Again, you could use a Tally CTE in place of the Tally Table in SQL Server 2005.
One final thought on this. If you don't use different delimiters to determine where groups end, then you can hard code the math. Just replace the formula for the @GroupCount with a hard coded value. If you turn the code for 2 Dimensional splits into a UDF, you could actually include @GroupCount as one of the input parameters and still maintain general-purpose utility of the 2 Dimensional split code.
Combined Split and Refactor to Table for 2D Parameters (2005 only)
We can combine the split right along with the refactoring to a table all in one shot and without the use of a Temp table in SQL Server 2005. This works if you know the format of the 2 Dimensional parameter that you want to split and refactor back to a table. In this particular case, we know our 2D parameter has 3 elements or columns per row. Knowing the format ahead of time makes the code very, very simple in SQL Server 2005 and, like I said, there's no need for a Temp table of any kind... here's an example similar to what we've been working with, so far. Obviously, the number "3" used in the code is the number of columns we're working worth and could be in a variable. As always, the details are in the comments in the code...
--2D Split Combined with Refactor to Table --===== Simulate a passed parameter
DECLARE @Parameter VARCHAR(8000)
SET @Parameter = 'Part#1,PartName1,1|Part#2,PartName2,2|Part#3,PartName3,3' --===== Suppress the auto-display of rowcounts to keep them from being
-- mistaken as part of the result set.
SET NOCOUNT ON --===== Add start and end commas to the Parameter and change all "group"
-- delimiters to a comma so we can handle all the elements the same way.
SET @Parameter = ','+REPLACE(@Parameter,'|',',') +',' --===== Join the Tally table to the string at the character level and
-- when we find a comma, insert what's between that comma and
-- the next comma into the Elements table. CTE does the split...
;WITH
cteSplit AS
(
SELECT ROW_NUMBER() OVER (ORDER BY N)-1 AS RowNumber,
SUBSTRING(@Parameter,N+1,CHARINDEX(',',@Parameter,N+1)-N-1) AS Element
FROM dbo.Tally
WHERE N < LEN(@Parameter)
AND SUBSTRING(@Parameter,N,1) = ',' --Notice how we find the comma
)
--==== ... and this puts the data back together in a fixed table format
-- using classic Cross-Tab code. It also converts columns that are
-- supposed to be numeric
SELECT (RowNumber/3)+1 AS RowNumber,
MAX(CASE WHEN RowNumber%3 = 0 THEN Element END) AS PartNumber,
MAX(CASE WHEN RowNumber%3 = 1 THEN Element END) AS PartName,
CAST(MAX(CASE WHEN RowNumber%3 = 2 THEN Element END) AS INT) AS QtyOrdered
FROM cteSplit
GROUP BY RowNumber/3
3 Dimensional Splits
The only difference between a 2 Dimensional split and a 3 Dimensional split is you need to identify yet another delimiter (I use the Tilde or "~"), add 1 column to the @Elements table, add 1 more formula to determine the number of elements per "page", and 1 more calculation to the UPDATE. That's IT! Here's the code complete with a sample parameter...
--3D Split with "Unit" Based Indices --===== Simulate a passed parameter
DECLARE @Parameter VARCHAR(8000)
SET @Parameter
= 'Part#01,PartName01,1|Part#02,PartName02,2|Part#03,PartName03,3~' --First Page
+ 'Part#04,PartName04,4|Part#05,PartName05,5|Part#06,PartName06,6~' --Second Page
+ 'Part#07,PartName07,7|Part#08,PartName08,8|Part#09,PartName09,9~' --Third Page
+ 'Part#10,PartName10,10|Part#11,PartName11,11|Part#12,PartName12,12' --Last Page --===== Create a table to store the results in
DECLARE @Elements TABLE
(
ElementNumber INT IDENTITY(1,1), --Order it appears in original string
ElementValue VARCHAR(8000), --The string value of the element
RowNum INT, --One of the three indices
ColNum INT, --One of the three indices
PagNum INT --One of the three indices
) --===== Declare a variable to store the number of elements detected in each group
-- of the input parameter
DECLARE @GroupCount INT --===== Declare a variable to store the number of elements detected in each page
-- of the input parameter
DECLARE @PageCount INT --===== Suppress the auto-display of rowcounts to keep them from being
-- mistaken as part of the result set.
SET NOCOUNT ON --===== Determine the number of elements in a group (assumes they're all the same)
SELECT @GroupCount =
-- Find the length of the first group...
LEN(SUBSTRING(@Parameter,1,CHARINDEX('|',@Parameter)))
-- ... subtract the length of the first group without any commas...
- LEN(REPLACE(SUBSTRING(@Parameter,1,CHARINDEX('|',@Parameter)),',',''))
-- ... and add 1 because there is always 1 element more than commas.
+ 1 --===== Replace the group delimiters with element delimiters
SET @Parameter = REPLACE(@Parameter,'|',',') --===== Determine the number of elements in a page (assumes they're all the same)
SELECT @PageCount =
-- Find the length of the first group...
LEN(SUBSTRING(@Parameter,1,CHARINDEX('~',@Parameter)))
-- ... subtract the length of the first group without any commas...
- LEN(REPLACE(SUBSTRING(@Parameter,1,CHARINDEX('~',@Parameter)),',',''))
-- ... and add 1 because there is always 1 element more than commas.
+ 1 --===== Add start and end commas to the Parameter and change all "page"
-- delimiters to a comma so we can handle all the elements the same way.
SET @Parameter = ','+REPLACE(@Parameter,'~',',') +',' --===== Join the Tally table to the string at the character level and
-- when we find a comma, insert what's between that comma and
-- the next comma into the Elements table
INSERT INTO @Elements (ElementValue)
SELECT SUBSTRING(@Parameter,N+1,CHARINDEX(',',@Parameter,N+1)-N-1)
FROM dbo.Tally
WHERE N < LEN(@Parameter)
AND SUBSTRING(@Parameter,N,1) = ',' --Notice how we find the comma --===== Calculate and update the "row" and "column" indices
UPDATE @Elements
SET RowNum = (ElementNumber-1)/@GroupCount+1, --"Unit" based row
ColNum = (ElementNumber-1)%@GroupCount+1, --"Unit" based col
PagNum = (ElementNumber-1)/@PageCount +1 --"Unit" based page --===== Display the final result of the split and the
-- index calculations
SELECT * FROM @Elements
That little slice of computational heaven produces the following EAV with 3 Dimensional indices...
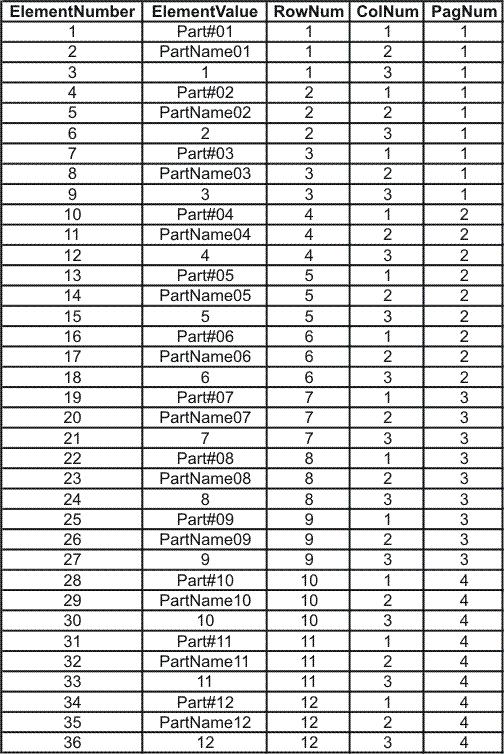
... and, heh, I'll let you figure out how you'd like to print THAT.
Again, if you don't use different delimiters, you can hard code the math and pass the number of elements for both the group count (# of elements per row) and the page count (number of elements per page).
Final Thoughts
Passing 2 Dimensional "arrays" is not difficult and generic code in the form of a UDF can be constructed from the code demonstrated in this article. With the advent of VARCHAR(MAX) in SQL Server 2005, you can pass some pretty big (huge) "arrays" and refactor the 2 Dimensional ones into real tables pretty easily and still maintain a high level of performance.
If you really have a mathematical need for indexed arrays in SQL Server 2000 or 2005, now you have a similar capability and I'll leave it to you to write your own functions to address the individual elements, as you may need them. If you always pass the same size "array", instead of doing an UPDATE on the Temp Table or Table Variable that holds the split, you could simply declare some calculated columns to do the same calculations as those found in the UPDATE for the multi-dimensional splits.
Using a bit of SQL prestidigitation with with different types of delimiters along with some some cooperation from the folks on the GUI side of the house, we found that you can make "generic" 2 Dimensional and 3 Dimensional splitters that figure out what the "arrays" should look like without hard-coding.
Last but not least, the location of the elements in parameters is not sacred... you can make it so every element is followed by a delimiter and just about any other combination you'd like. But, you should always make it so the whole parameter is wrapped in delimiters before you start the split just to keep the code simple. And to keep the code even more simple, instead of fighting different delimiters, once you know the count, change them all to be the same delimiter because you're actually only splitting elements and using the group and page counts to determine where an element actually belongs in the "array".
Thanks for listening, folks.
--Jeff Moden
"Your lack of planning DOES constitute an emergency on my part... SO PLAN BETTER! "
"RBAR is pronounced "ree-bar" and is a "Modenism" for "Row-By-Agonizing-Row"
