

So far I've covered the basics of partitioning strategies in
archiving in
and partitioned views in Part 3. This time we'll finish up by looking at the
partitioning features now available in the Enterprise edition of SQL 2005.
I'm going to start with deploying a simple partition. It's a three step process:
- Create a partitioning function
- Create a partitioning scheme
- Create the table using the partitioning scheme
For a simple example we're going to partition the Person.Contact table in
Adventureworks by year. We'll start by creating the partitioning function:
CREATE PARTITION FUNCTION fnPartitionByYear (datetime) AS RANGE RIGHT FOR VALUES ( '1/1/1996', '1/1/1997', '1/1/1998', '1/1/1999', '1/1/2000', '1/1/2001', '1/1/2002', '1/1/2003', '1/1/2004', '1/1/2005', '1/1/2006', '1/1/2007')
In this case we're creating our 'bucketing' mechanism. We want to create
partitions for each year. One slightly confusing part is whether to use LEFT or
RIGHT. Essentially you're telling the function whether your values are the last
ones in each bucket (LEFT), or the first one in each bucket (RIGHT). I like
RIGHT for dates because I want 1/1/1996 12/31/1996 23:59 in the same partition
and it's easier than using LEFT with 12/31/1996 23:59:59, 12/31/1997 23:59, etc.
SQL will apply this function to each row to figure out what partition it belongs
to when you load (or modify) data.
Now we'll create a partitioning scheme using the function we just created. A
scheme is a super container that can hold one or more filegroups. I've used the
simpler ALL syntax here to show that I want to create all the partitions on
Primary. Note that because primary is a reserved word it requires the brackets.
Putting all on one filegroup isn't as good as using multiple filegroups across
different drives, but on my laptop I have only one drive and I wanted to
illustrate the ALL usage. It is possible to specify a filegroup for each
partition and even to specify what filegroup will be used when the next
partition is created.
CREATE PARTITION SCHEME ContactScheme AS PARTITION fnPartitionByYear ALL to ([Primary])
We should see this message:

Finally, we'll create a new table called ContactPartitioned that is almost
the same as the original table. One of the rules is that partitioning columns
have to be a part of any unique index (as I understand it, this helps the
optimizer know that it only needs to check a single partition) if you want that
index to be on the same partition. So our choices based on the design of the
original Contact table are to append the modifieddate to the the previously
defined clustered index so that everything else stays the same, or we change the
primary key to be non clustered and create it directly on a filegroup. I know
it's a little confusing! It's absolutely worth spending a few minutes using my
code samples to work through all of this so you can see first hand. The "magic"
is the last line where instead of creating the table on FILEGROUP, we create it
on SCHEME. In this case, our just created ContactScheme and we pass in the
partitioning column of modified date.
CREATE TABLE [Person].[ContactPartitioned](
[ContactID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[NameStyle] [dbo].[NameStyle] NOT NULL DEFAULT ((0)),
[Title] [nvarchar](8) NULL,
[FirstName] [dbo].[Name] NOT NULL,
[MiddleName] [dbo].[Name] NULL,
[LastName] [dbo].[Name] NOT NULL,
[Suffix] [nvarchar](10) NULL,
[EmailAddress] [nvarchar](50) NULL,
[EmailPromotion] [int] NOT NULL DEFAULT ((0)),
[Phone] [dbo].[Phone] NULL,
[PasswordHash] [varchar](40) NOT NULL,
[PasswordSalt] [varchar](10) NOT NULL,
[AdditionalContactInfo] [xml](CONTENT [Person].[AdditionalContactInfoSchemaCollection]) NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL DEFAULT (newid()),
[ModifiedDate] [datetime] NOT NULL DEFAULT (getdate())
CONSTRAINT [PK_Contact_ContactIDNew] PRIMARY KEY CLUSTERED ([ContactID], ModifiedDate ASC))
ON ContactScheme(modifieddate)To see if everything is really working, we'll copy the data from
Person.contact into the new table:
INSERT INTO Person.ContactPartitioned
(NameStyle
,Title
,FirstName
,MiddleName
,LastName
,Suffix
,EmailAddress
,EmailPromotion
,Phone
,PasswordHash
,PasswordSalt
,AdditionalContactInfo
,rowguid
,ModifiedDate)
select
NameStyle
,Title
,FirstName
,MiddleName
,LastName
,Suffix
,EmailAddress
,EmailPromotion
,Phone
,PasswordHash
,PasswordSalt
,AdditionalContactInfo
,rowguid
,ModifiedDate
from person.contactLet's run two simple queries so that we can compare apples to apples:
select * from person.contactpartitioned where modifieddate = '1/1/2004' select * from person.contact where modifieddate = '1/1/2004'
The both return the same number of rows, but if just look at the plans we see that there is a big difference in the relative query costs:
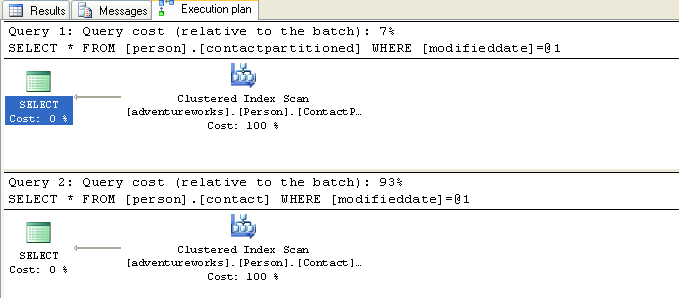
We can see that in both cases we used a clustered index scan (because we
elected to return all columns and because we have no index on modifieddate in
either table), but our query against our new partitioned table seems to be much
more efficient. We can confirm that with a quick Profiler session:

Another way to confirm that partitioning is actually being used is to hover
over the plan operator and see if it shows a partition id line (in red below):
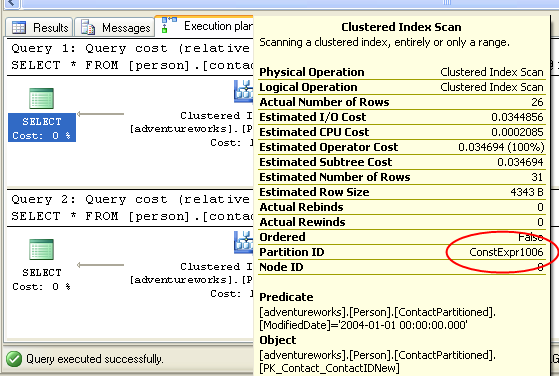
To see how the data was allocated, we can run this query:
select object_name(object_id), partition_number, rows from sys.partitions where object_name(object_id)='contactpartitioned'
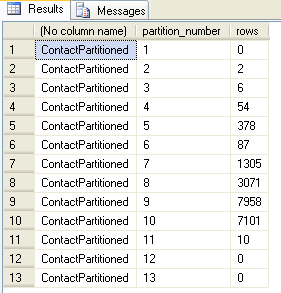
If we query the data by year directly, we get:
select year(modifieddate), count(*) as PartitionCount from person.contactpartitioned group by year(modifieddate) order by year(modifieddate)
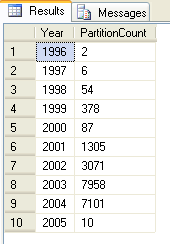
We only get 10
rows. Why? The person.contact table contains no data for 2006 or 2007, but we
created partitions for those year in our partitioning function. That accounts
for 2 of the missing 3. The other one is the first partition with 0 rows,
created to handle any data that might be prior to 1/1/1996.
Here are a few miscellaneous notes about partitioning:
- Remember its only Enterprise edition (and Developer of course)
- Indexes can be partitioned to match the table partition, or not. Just as
partitioning a table can boost speed in certain cases, same is true for
indexes
- It's horizontal only
- There's a lot of options and rules to partitioning and no UI to help you
out. Before you go big, build a small table with some test data that matches
your scenario and work through the steps
I blog once a week or so at
http://blogs.sqlservercentral.com/blogs/andy_warren/default.aspx about
SQL Server, SQL user groups, and related topics. I hope you'll visit and comment
occasionally!

