

The OVER clause was added to SQL Server “way back” in SQL Server 2005, and it was expanded upon in SQL Server 2012. It is used predominantly with the “Window Functions”; the sole exception being the sequence function NEXT VALUE FOR. The OVER clause is used to determine which rows from the query are applied to the function, what order they are evaluated in by that function, and when the function’s calculations should restart. Since it is used in conjunction with other functions, and this article is about specifically just the OVER clause, these functions will be talked about only as it pertains to the OVER clause in the examples given.
The syntax of the OVER clause is:
<function> OVER ( [PARTITION BY clause]
[ORDER BY clause]
[ROWS or RANGE clause])In looking at the syntax, it appears that all of the sub-clauses are optional. In fact, each function that can use the OVER clause determines which of the sub-clauses are allowed, and which are required. Depending on the function being used, the OVER clause itself may be optional. There is a chart at the end of this article that shows which functions allow / require which portions of the OVER clause.
The PARTITION BY clause is used to divide the result set from the query into data subsets, or partitions. If the PARTITION BY clause is not used, the entire result set from the query is the partition that will be used. The window function being used is applied to each partition separately, and the computation that the function performs is restarted for each partition. You define a set of values which determine the partition(s) to divide the query into. These values can be columns, scalar functions, scalar subqueries, or variables.
For example, let’s examine the following query:
SELECT COUNT(*) FROM [msdb].sys.indexes;
This query returns the following result set:
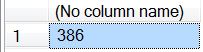
This is simply the number of rows returned by the query – in this case, the number of indexes in the msdb database. Now let’s add the OVER clause to this query:
SELECT object_id, index_id, COUNT(*) OVER () FROM [msdb].sys.indexes;
The abridged results are:
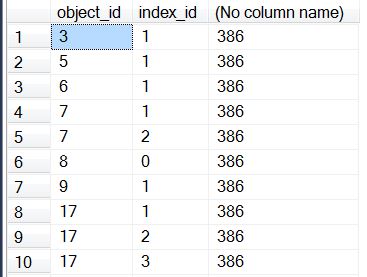
This query returns the object_id and index_id for each index, and the total number of indexes in the result set. Since a PARTITION BY clause was not used, the entire result set was treated as a single partition. It’s now time to add the PARTITION BY clause and see how this changes the results:
SELECT object_id, index_id, COUNT(*) OVER (PARTITION BY object_id) FROM [msdb].sys.indexes;
The abridged results are:
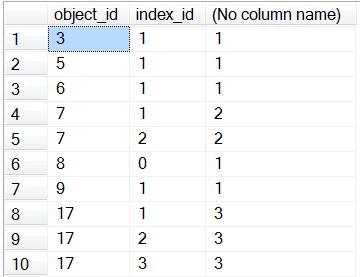
This query returns a row for each index, but now the query specifies a PARTITION BY clause of the object_id column, so the count function is returning the number of indexes on that particular object_id. The ORDER BY clause controls the order that the rows are evaluated by the function. This will be demonstrated shortly. The ROWS or RANGE clause determines the subset of rows within the partition that are to be applied to the function. When using ROWS or RANGE, you specify the beginning and ending point of the window. The allowed values are:

There are two syntaxes for specifying the window:
BETWEEN <beginning frame> AND <ending frame> <beginning frame>
If just the beginning frame is specified, the default ending frame is CURRENT ROW.
The UNBOUNDED keyword specifies the beginning of the partition (for PRECEDING), or the end of the partition (for FOLLOWING). CURRENT ROW specifies that the current row is either the start of the window, or the end of the window, depending on which window frame position it is used in. “N” specifies a number of rows either prior to the current row (for PRECEDING), or after the current row (for FOLLOWING) to use for the window frame.
The following are valid window specifications:
-- specifies the entire result set from the partition BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING -- specifies 5 rows, starting 4 rows prior to the current row through the current row from the partition BETWEEN 4 PRECEDING AND CURRENT ROW -- specifies all of the rows from the current row to the end of the partition BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING -- specifies all of the rows from the start of the partition through the current row UNBOUNDED PRECEDING
In order to use the ROWS or RANGE clause, you must also specify the ORDER BY clause. Conversely, if you use the ORDER BY clause and you don’t specify a ROWS or RANGE clause, then the default RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW is used.
To demonstrate the ORDER BY and ROWS or RANGE clauses, let’s create some test data: two accounts, four dates per account, and an amount for each date. The query will show both of these clauses being used in different ways:
DECLARE @Test TABLE (
Account INTEGER,
TranDate DATE,
TranAmount NUMERIC(5,2));
INSERT INTO @Test (Account, TranDate, TranAmount)
VALUES (1, '2015-01-01', 50.00),
(1, '2015-01-15', 25.00),
(1, '2015-02-01', 50.00),
(1, '2015-02-15', 25.00),
(2, '2015-01-01', 50.00),
(2, '2015-01-15', 25.00),
(2, '2015-02-01', 50.00),
(2, '2015-02-15', 25.00);
SELECT Account, TranDate, TranAmount,
COUNT(*) OVER (PARTITION BY Account
ORDER BY TranDate
ROWS UNBOUNDED PRECEDING) AS RowNbr,
COUNT(*) OVER (PARTITION BY TranDate) AS DateCount,
COUNT(*) OVER (PARTITION BY Account
ORDER BY TranDate
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW) AS Last2Count
FROM @Test
ORDER BY Account, TranDate;This query returns the following result set:
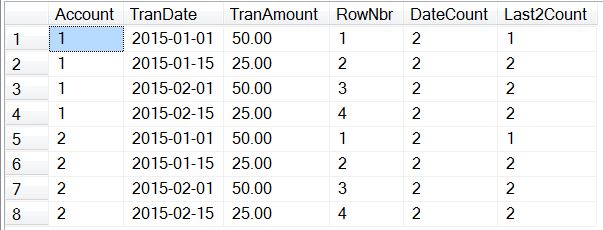
The “RowNbr” column is using the COUNT function to return how many rows are in the partition. The partition is ordered by TranDate, and we are specifying a window frame of all of the rows from the start of the partition through the current row. For the first row, there is only one row in the window frame, so the value “1” is returned. For the second row, there are now two rows in the window frame so the value “2” is returned. And so on through the rest of the rows in this account.
Since the PARTITION BY clause specifies the account, when the account changes then the function calculations are reset, which can be seen by examining the rows for the second account in the result set. This is an example of a “running” aggregation, where the aggregation builds upon previous calculations. An example of when you would use this would be to when calculating your bank account balance after each transaction (otherwise known as a running total).
The “DateCount” column is performing a count of how many rows, partitioned by the date. In this example, each of the accounts have a transaction on each of the same four dates, so each date has two transactions (one for each account). This results in the value “2” being returned for each row. This is similar to performing a count that uses GROUP BY for the date; the difference being that the total is returned for each row instead of just once for each date. An example of when you would use this method would be to display a “Row X of Y”, or to calculate a percent of the current row to the total.
The “Last2Count” column performs a count of the rows within the partition, for the current row and the one row immediately preceding it. For the first row in each account, since there aren’t any rows preceding it, a value of “1” is returned. For the remaining rows in each account, a value of “2” is returned. This is an example of a “moving” or “sliding” aggregation. An example of when you would use this method would be to calculate a bonus based upon the last two months sales.
At this point, I’ve shown just the ROWS clause. The RANGE clause works in a similar manner, but instead of dealing with the rows in a positional manner, it deals with the values returned by that row. It is because it is not positional that the N PRECEDING/FOLLOWING clauses cannot be used. Let’s take a quick look at the difference between ROWS and RANGE by using both of them in the same query. Here we have a list of people (let’s call them DBAs), and their hourly rates. Note that the rows with RowIDs 4&5, and 12&13 have the same rate. The query will sum up the rates two times, once using ROWS and the other using RANGE:
SELECT FName,
Salary,
SumByRows = SUM(Salary) OVER (ORDER BY Salary
ROWS UNBOUNDED PRECEDING),
SumByRange = SUM(Salary) OVER (ORDER BY Salary
RANGE UNBOUNDED PRECEDING)
FROM (VALUES (1, 'George', 800),
(2, 'Sam', 950),
(3, 'Diane', 1100),
(4, 'Nicholas', 1250),
(5, 'Samuel', 1250),
(6, 'Patricia', 1300),
(7, 'Brian', 1500),
(8, 'Thomas', 1600),
(9, 'Fran', 2450),
(10,'Debbie', 2850),
(11,'Mark', 2975),
(12,'James', 3000),
(13,'Cynthia', 3000),
(14,'Christopher', 5000)
) dt(RowID, FName, Salary);This query produces the following result set:
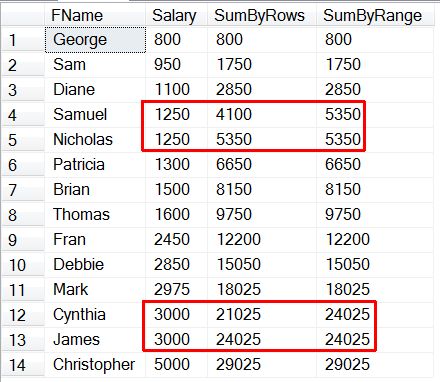
In both the SumByRows and SumByRange columns the OVER clause is identical with the exception of the ROWS/RANGE clause. Notice also that since the ending range was not specified, the default is to use CURRENT ROW. Since we’re summing the salary from the beginning of the result set through the current row, what we’re really calculating is a running total of the Salary column. In the SumByRows column, the value is calculated using the ROWS clause, and we can see that the sum of the current row is the current row’s Salary plus the prior row’s total. However, the RANGE clause works off of the value of the Salary column, so it sums up all rows with the same or lower salary. This results in the SumByRange value being the same value for all rows with the same Salary.
One important note: the ORDER BY clause in the OVER clause only controls the order that the rows in the partition will be utilized by the window function. It does not control the order of the final result set. Without an ORDER BY clause on the query itself, the order of the rows is not guaranteed. You may notice that your query may be returning in the order of the last specified OVER clause – this is due to the way that this is currently implemented in SQL Server. If the SQL Server team at Microsoft changes the way that it works, it may no longer order your results in the manner that you are currently observing. If you need a specific order for the result set, you must provide an ORDER BY clause against the query itself.
Finally, here is a chart of the various functions that can use the OVER clause, as well as which portions of the clause are allowed / required / optional.
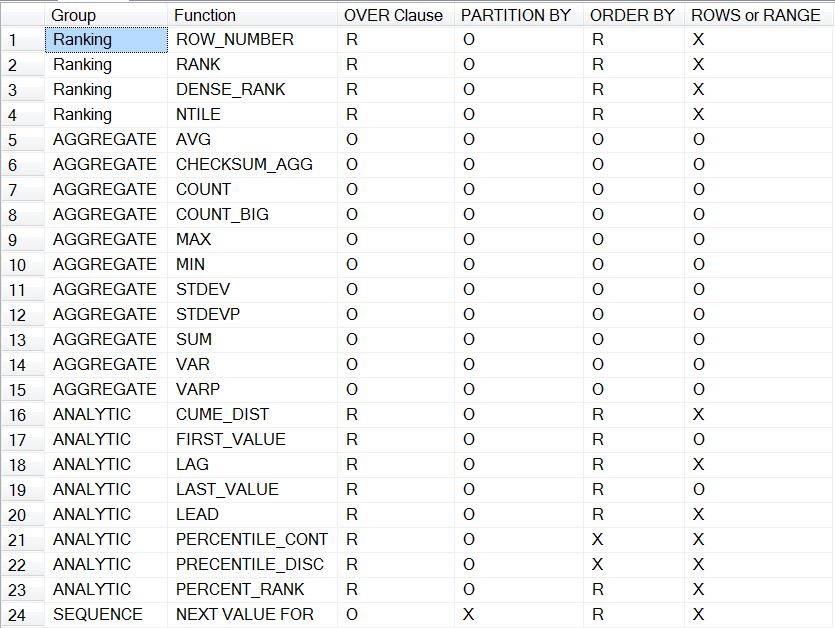
R-Required, O-Optional, X-Not Allowed

