

Consider this article a very basic introduction to an area in which countless multi-hundred
paged books have been written during the last four decades. This article can not and does not intend to compete
with any of these books, but rather tries to explain different database models in a non-academic style.
I will discuss the following database models:
- Flat Files
- Hierarchical Model
- Network Model
- Relational Model
- Object-Relational Model
- Object-Oriented Model
- Other Models
Flat Files
Simply put, one can imagine a flat file database as one single large table. A good example to visualize
this is to think of a spreadsheet. A spreadsheet can only have one meaningful table structure at a time.
Data access happens only sequentially; random access is not supported. Queries are usually slow, because the
whole file always has to be scanned to locate the data. Although data access could be sped up by sorting the
data, in doing so the data becomes more vulnerable to errors in sorting. In addition you'll face following
problems.
- Data Redundancy.
Imagine a spreadsheet where you collect information about bonds to manage a fixed income portfolio. One
column might contain the information about the issuer of that bond. Now when you buy a second bond from this
issuer you again have to enter that information.
- Data Maintenance.
Given the above example consider what happens when the information of this issuer changes. This change has to
be applied to every single bond (row) of that issuer.
- Data integrity.
Following 2; what happens when you have a typo when changing the information? Inconsistencies are the
outcome.
As a result one concludes that Flat File Databases are only suitable for small, self-evident amounts of
data.
Hierarchical Database Model
Hierarchical databases (and network databases) were the predecessors of the relational database model.
Today these models are hardly used in commercial applications. IBM's IMS (Information Management System) is
the most prominent representative of the hierarchical model. It is mostly run on older mainframe systems.
This model can be described as a set of flat files that are linked together in a tree structure. It is
typically diagrammed as an inverted tree.
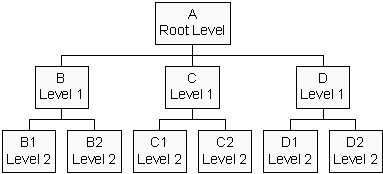
The original concept for this model represents the data as a hierarchical set of Parent/Child relations.
Data is basically organized in a tree of one or more groups of fields, that are called segments. Segments
make up every single node of the tree. Each child segment can only be related to just one parent segment
and access to the child segment could only happen via its parent segment. This means, that 1:n relations
result in data redundancy.
To solve this problem, the data is stored in only one place and is referenced through links or physical pointers.
When a user accesses data he starts at the root level and works down his way through the tree to the desired
target data. That's the reason why a user must be very familiar with the data structure of the whole database.
But once he knows the structure, data retrieval could become very fast.
Another advantage is built-in referential integrity, which is automatically enforced.
However, because links between the segments are hard-coded into the database, this model becomes inflexible to
changes in the data structure. Any change requires substantial programming effort, which in most cases comes
along with substantial changes not only in the database, but also in the application.
Network Database Model
The network database model is an improvement to the hierarchical model. In fact it was developed to
address some of the weaknesses of the hierarchical model. It was formally standardized as CODASYL DBTG
(Conference On Data System Languages, Data Base Task Group) model in 1971 and is based on mathematical set
theory.
At its core the very basic modeling construct is the set construct. This set consists of an owner record,
the set name, and the member record. Now, this 'member' can play this role in more than one set at the
same time; therefore this member can have multiple parents. Also an owner type can be owner or member in one or
more other set constructs. This means the network model allows multiple paths between segments. This is a
valuable improvement on relationships, but could make a database structure very complex.
Now how does data access happen? Actually, by working through the relevant set structures. A user need not
work down his way through root tables, but can retrieve data by starting at any node and working through the
related sets. This provides fast data access and allows the creation of more complex queries than could be
created with the hierarchical model. But, once again, the disadvantage is that the user must be familiar with
the physical data structure. Also, it is not easy to change the database structure without affecting the
application, because if you change a set structure you need to change all references to that structure within
the application.
Although an improvement to the hierarchical model, this model was not believed to be the end of the line.
Today the network database model is obsolete for practical purposes.
Relational Database Model
The theory behind the relational database model will not be discussed in this article; only the differences
to the other models will be pointed out. I will discuss the relational model along with some set theory and
relational algebra basics in a different set of articles in the near future, if they let me :).
In the relational model the logical design is separated from the physical. Queries against a Relational
Database Management System (RDBMS) are solely based on these logical relations. Execution of a query doesn't require
the use of predefined paths like pointers. Changes to the database structure are fairly simple and easy to
implement.
The core concept of this model is a two-dimensional table, comprising of rows and columns. Because the data
is organized in tables, the structure can be changed, without changing the accessing application. This is
different to its predecessors, where the application usually had to be changed when the data structure changed.
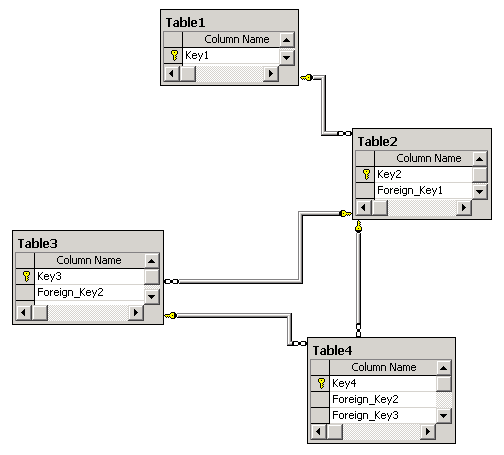
The relational database model knows no hierarchies within its tables. Each table can be directly accessed and
can potentially be linked to each other table. There are no hard-coded, predefined paths in the data. The
Primary Key - Foreign Key construct of relational databases is based on logical, not on physical links.
Another advantage of the relational model is that it is based on a solid house of theory. The inventor,
E.F.Codd, a mathematician by profession, has defined what a relational database is and what a system needs
to call itself a relational database 1), 2). This model is firmly based on the mathematical theories of
sets and first order predicate logic. Even the name is derived from the term relation which is commonly used
in set theory. The name is not derived from the ability to establish relations among the table of a relational
database.
Object-Relational Model
Also called post-relational model or extended relational model. This model addresses several weaknesses of
the relational model. The most significant of which is the inability to handle BLOB's.
BLOBs, LOBs or Binary Large Objects are complex data types like time series, geospatial data, video
files, audio files, emails, or directory structures.
An object-relational database system encapsulates methods with data structures and can therefore execute
analytical or complex data manipulation operations.
In it's most simple definition data is a chain of 0s and 1s, that are ordered in a certain manner.
Traditional DBMSs have been developed for and are therefore optimized for accessing small data elements like
numbers or short strings. These data are atomic; that is they could be not further cut down into smaller
pieces. In contrast are BLOB's large, non-atomic data. They could have several parts and subparts.
That is why they are difficult to represent in an RDBMS.
Many relational databases systems do offer support to store BLOBs. But in fact, they store these data outside
the database and reference it via pointers. These pointers allow the DBMS to search for BLOBs, but the
manipulation itself happens through conventional IO operations.
Object-Oriented Model
According to Rao (1994), "The object-oriented database (OODB) paradigm is the combination of object-oriented
programming language (OOPL) systems and persistent systems. The power of the OODB comes from the seamless
treatment of both persistent data, as found in databases, and transient data, as found in executing programs."
To a certain degree, one might think that the object-oriented model is a step forward into the past, because
their design is like that of hierarchical databases. In general, anything is called an object, which can be
manipulated. Like in OO programming objects inherit characteristics of their class and can have custom properties
and methods. The hierarchical structure of classes and subclasses replaces the relational concept of atomic data
types. As with OO programming the object-oriented approach tries to bring OO characteristics like classes,
inheritance, and encapsulation to database systems, making a database in fact a data store.
The developer of
such a system is responsible for implementing methods and properties to handle the data in the database from
within his object-oriented application.
There is no longer a strict distinction between application and database.
This approach makes Object DBMS an interesting and sometimes superior alternative to RDBMS when complex
relationships between data are essential. An example of such an application might be current portfolio risk
management systems.
However, these systems lack a common, solid base of theory that Codd provided for relational databases.
There is a model proposed by the Object Management Group (OMG), which could be viewed as de facto standard, but
the OMG can only advise and is not a standards body like ANSI.
Other Models
For the sake of "completeness" what now follows is a list of other models without further detailed
explanation:
- Semistructured Model
- Associative Model 3)
- Entity-Attribute-Value (EAV) data model 4)
- Context Model
Conclusion
Well, no real conclusion.
I hope you are with me so far and have seen that there (still) is a world outside the relational model,
which can be pretty exciting to discover.
If you are interested in more details, you might want to follow the links provided in the reference.
References
1)Codd, E.F. "Is Your DBMS Really Relational?" and "Does Your DBMS Run By the
Rules?" ComputerWorld, October 14 1985 and October 21 1985.
2)Codd, E.F. The Relational Model for Database Management, Version 2;
Addison-Wesley; 1990.
http://www.lazysoft.com/docs/other_docs/amd_whitepaper.pdf
http://ycmi.med.yale.edu/nadkarni/eav_cr_contents.htm