

Recently my company moved to SQL Server 2014/2016, and I started setting up and managing SQL Server Always On Availability Groups. Availability Groups (AG) nicely replaced mirroring and log shipping functionalities. I found it relatively easy to set up and get robust performance, but as with any new technology, Availability Groups come with shortfalls that need to be dealt with. There is a very good series by Michael K. Campbell called “Always On Availability Groups and SQL Server Jobs”.
In this article, I will be focusing on one of the practical solutions for management of internal SQL Server jobs in Always On Availability Groups scenarios. The solution, discussed below, is implemented in production and UAT environments and demonstrates robust outcomes.
Let us start with some definitions which allow us understand why we are designing solution to manage jobs in Availability Group (AG). Below are the four definitions as defined by Microsoft. The availability mode determines if the primary replica waits to commit transactions on a database until a given secondary replica has written the transaction log records to disk (hardened the log). There are two AG modes: asynchronous-commit mode and synchronous-commit mode.
Asynchronous-commit mode - where the primary replica commits transactions without waiting for acknowledgement from the secondary replica. This mode minimizes transaction latency on the secondary databases but allows them to lag behind the primary databases. This creates a possibility of some data loss.
Synchronous-commit mode - before committing transactions, a synchronous-commit primary replica waits for a synchronous-commit secondary replica to acknowledge that it has finished. This mode ensures that the secondary database is synchronized with the primary database and committed transactions are fully protected. This protection comes at the cost of increased transaction latency.
Synchronous-commit mode supports two forms of failover—manual failover and automatic failover.
Manual failover occurs after a failover command is issued and pushes a synchronized secondary replica to transition to the primary role while the primary replica takes the role of the secondary replica. A manual failover can be done only if both the primary replica and the secondary replica are running in synchronous-commit mode, and the secondary replica is already synchronized.
Automatic failover occurs in response to a failure that causes a synchronized secondary replica to transition to the primary role (with guaranteed data protection). Automatic failover requires both the primary replica and the secondary replica to be in synchronous-commit mode with the failover mode set to "Automatic".
The image below shows two replicas and a primary SQL Server.
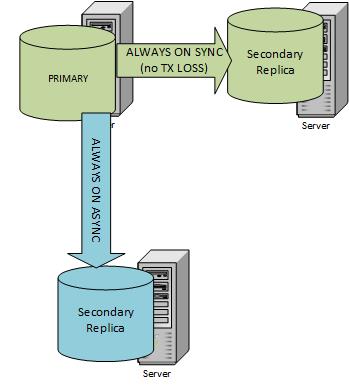
We are going to talk about what to do with jobs in Synchronous-commit mode and automatic, planned or unplanned manual failover. For the sake of discussion, I will assume that our production server has only one job. In reality, the servers I am working with have many custom build jobs. Sometimes, we are talking about hundreds of jobs per SQL Server. However, this does not change anything in our approach. The only difference will be that the same approach will have to be applied to every job on the server.
Why do we need to control custom SQL Server jobs in an AG environment? Here, we are mostly going to talk about an HA node in synchronous-commit mode with automatic failover. This is the most difficult case. But the same principle, which can be controlled manually, can apply to the synchronous-commit mode with manual failover or asynchronous-commit mode with manual failover.
Assume that there is a trivial SQL Server batch job that is designed to run every 2 hours, checking for the existence of input files, moving them to the processing directory on the local server, and loading data. What happens if a job runs in both the primary and secondary AG replicas?
The first issue is that secondary replica may process a file before the actual primary replica does so. Then the job on the secondary replica is going to fail because databases on the secondary replica are in read only mode or completely unavailable even for reading. In this case, the primary replica missed the file, and the data is missed. One can say that jobs on the secondary replica should be disabled. This is true. Initially, we can disable jobs on the secondary replica. However, there are a few issues here in automatic failover.
In this case, the primary replica becomes the secondary replica and vice versa. In this scenario, the job will not be activated on the (new) primary replica and will stay enabled on the (new) secondary replica. This is the scenario we are trying to avoid.
Another problem can be if somebody (presumably the DBA) mistakenly starts job(s) manually without realizing that he/she is on the secondary AG replica. This should not really happen because connections to the replicas should be done via the AG listener, but never say never.
For example, we have a set of jobs with multiple steps. These jobs extract data into Excel files once per month and then those extracts are placed in FTP directories for users’ consumption. The extract jobs are running on demand because it is not predictable when data that is used for extracts will arrive and get loaded into the system. The extract jobs should not run until some ETL jobs that prepare data are finished. Let’s say the DBA checked the wrong server, found that the preparation ETL jobs are not running and accidently started an extract job on demand. There will be prepared data but the data will be partial and wrong.
Now knowing a few cases, we should design a solution that will check the role of the replica and enable/disable jobs based on the replica role. This should have in an automatic or manually controlled flip between the primary and secondary replica in the AG. The solution has to be smart enough to understand that it is possible that not every job has to be disabled/enabled. This is part of one of the many different solutions I will explain below.
Because we are going to use some supporting control tables, functions, and stored procedures, we have to define in which database these will be kept and maintained. There are two choices. Choice one is to create a special database for each replica and never place this database in the AG. The second choice is using a master database. I chose the second choice with one caveat - all my objects will be created, not in the dbo schema, but in a specifically created schema, “ags”, for this purpose.
First, we do need to find how to detect if the SQL Server instance is the primary or secondary replica. For this purpose, we are going to use 2 system views: sys.dm_hadr_availability_group_states and sys.availability_groups.
Sys.availability_groups returns a row for every availability group that the local instance of SQL Server hosts an availability replica for. Each row contains a cached copy of the availability group metadata. Sys.dm_hadr_availability_group_states returns a row for each Always On availability group that possesses an availability replica on the local instance of SQL Server. Each row displays the states that define the health of a given availability group.
In view sys.availability_groups, we are using two fields:
- Group_id uniqueidentifier - Unique identifier (GUID) of the availability group.
- Name sysname - Name of the availability group. This is a user-specified name that must be unique within the Windows Server Failover Cluster (WSFC).
In view sys.dm_hadr_availability_group_states, we are using only one field.
- primary_replica varchar(128) - Name of the server instance that is hosting the current primary replica. NULL = Not the primary replica or unable to communicate with the WSFC failover cluster.
If you would like to read about those two tables in depth, you can use these links:
- https://docs.microsoft.com/en-us/sql/relational-databases/system-dynamic-management-views/sys-dm-hadr-availability-replica-states-transact-sql
- https://technet.microsoft.com/en-us/library/ff878538(v=sql.110).aspx
The function below returns the replica role – primary, secondary, or failure if empty string or NULL is passed to the function. Warning, if name of the AG group is misspelled the function will return a value of ‘N’, the same as for the Secondary replica.
CREATE FUNCTION ags.udf_AGHadrGroupIsPrimary (@AGName sysname)
RETURNS char(1)
AS
BEGIN
DECLARE @PrimaryReplica sysname, @IsPrimary char(1);
SELECT @PrimaryReplica = hags.primary_replica
FROM sys.dm_hadr_availability_group_states hags
INNER JOIN sys.availability_groups ag
ON ag.group_id = hags.group_id
WHERE ag.name = @AGName;
IF UPPER(@PrimaryReplica) = UPPER(@@SERVERNAME)
begin
set @IsPrimary = 'Y'; -- primary
end;
Else
begin
set @IsPrimary = 'N'; -- not primary
end;
IF ISNULL(@AGName,'') = ''
begin
set @IsPrimary = 'F'; -- failed
end;
return @IsPrimary;
END;
Conclusion
This is the first article in a two article series. This article explains why we need a job controlling mechanism in AG environment, which system views will be used for the control mechanism, and how determine the role of the replica in AG.
The next article will provide information about the actual implementation of the control mechanism.

{kind=link}