

In my previous article (Analysis About Analysis Services) I showed how to make analysis from the log of Analysis Services. As the information about olap queries are modest, we should try to get as much information from the log as we can. For example, we should known how many partitions were read by the query. This is written in the columns MOLAP_Partitions and ROLAP_Partitions. When the value of MOLAP_Partitions and ROLAP_Partitions columns is 0, then the query was answered from the server cache. In this article I'll describe how to get information from the DataSet column in the querylog table.
Table querylog was designed for usage based optimization, but by using the information from that table soundly, we can get the results needed for our purposes and use them however we want.
The DataSet column represents levels and dimensions in the cube. Let's examine the dimensions of the "HR" cube in the "food mart 2000" database. The cube has these dimensions and levels:
- Time - 3 levels: Year, Quarter, Month.
- Store - 4 levels: Store Country, Store State, Store City, Store Name.
- Pay Type - 1 level: Pay Type.
- Store Type - 1 level: Store Type.
- Position - 2 levels: Management Role, Position Title.
- Department - 1 level: Department description.
- Employees - 1 level (parent child dimension): Employee ID.
You can view all dimensions and levels from the FoodMart 2000 cube expanding the cubes and right clicking the cube "HR" and then expanding each dimension.
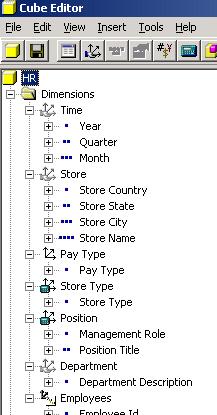
Figure 1
Now let's browse the HR cube. Select Employees table and select "Rebecca Kanagaki" (under Sheri Nowmer). In the querylog table you'll find a new record with a dataset = "1111113". Then let's select "Alameda" city from the Store dimension (in the CA state, USA). In the query log you'll find a next record with a dataset = "1411113".
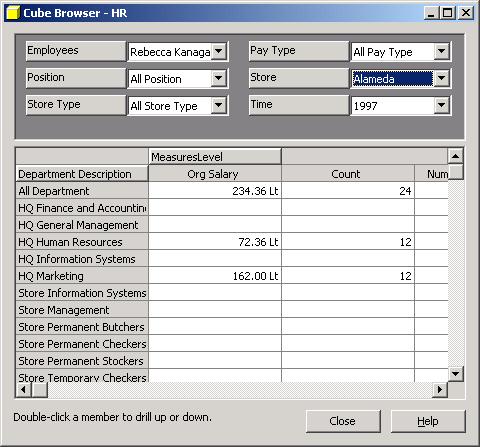
Figure 2
As you may understand the number of characters in the dataset column is equal the number of the dimension in the cube. And each number in the dataset represent the level of dimension. The number "1" in the dataset always represents level "(All)". So, in our example the dataset "1111113" represents the 3rd level of the Employees dimension in the Store dimension and dataset "1411113" represents "Store City" in the Store dimension plus the 3rd level of the Employees dimension. The biggest number of each dimension dataset could be [number of levels] + 1. The exception is a parent-child dimension, where the number of actual levels is unknown.
Now we can easily create some dso code that will help us to understand the full description of the dataset. I created the sql proc fn_resolve_dataset (fn_resolve_dataset.txt). This proc checks the dataset and formats a strings that represents dimension and dimension level in such format:
"dimension_a.level_x;dimension_b.level_y...."
If you already migrated the querylog table into your sql server, after creating this proc in your sql server olap repository database, you can fine out about each query's dimensions dimensions by running a query like:
select top 100
*
, olap_repository.dbo.fn_resolve_dataset
('your_server_name', MSOLAP_Database, MSOLAP_Cube, Dataset)
as DataSet_Description
from querylog with (nolock)
Or, you can add a column named DataSet_description to your querylog_history table and populate that column with a trigger, or use for your own purposes in another way.
Conclusions
OLAP administrators often need to know not only who and when a query is executed. By analyzing the querylog table and especially the column dataset, they learn more and answer more complex questions about the usage of their cube's dimensions. In my practice I have found that my users never used several dimensions even though they exists in my cubes. Knowing this, I can safely remove them.

