

There are two really great features just added to Power BI that I wanted to blog about: Composite models and Dual storage mode. This is part of the July release for Power BI Desktop and it is in preview (see Power BI Desktop July 2018 Feature Summary). I’ll also talk about a future release called Aggregations.
First a review of the two ways to connect to a data source:
Import – The selected tables and columns are imported into Power BI Desktop. As you create or interact with a visualization, Power BI Desktop uses the imported data. You must refresh the data, which imports the full data set again (or use the preview feature incremental refresh), to see any changes that occurred to the underlying data since the initial import or the most recent refresh. Import datasets in the Power BI services have a 10GB dataset limitation for Premium version and 1GB limitation for free version (although with compression you can import much large data sets). See Data sources in Power BI Desktop
DirectQuery – No data is imported or copied into Power BI Desktop. As you create or interact with a visualization, Power BI Desktop queries the underlying data source, which means you’re always viewing current data. DirectQuery lets you build visualizations over very large datasets, where it otherwise would be unfeasible to first import all of the data with pre-aggregation. See Data sources supported by DirectQuery.
Up until now in Power BI, when you connect to a data source using DirectQuery, it is not possible to connect to any other data source in the same report (all tables must come from a single database), nor to include data that has been imported. The new composite model feature removes this restriction, allowing a single report to seamlessly combine data from one or more DirectQuery sources, and/or combine data from a mix of DirectQuery sources and imported data. So this means you can combine multiple DirectQuery sources with multiple Import sources. If your report has some DirectQuery tables and some import tables, the status bar on the bottom right of your report will show a storage mode of ‘Mixed.’ Clicking on this allows all tables to be switched to import mode easily.
For example, with composite models it’s possible to build a model that combines sales data from an enterprise data warehouse using DirectQuery, with data on sales targets that is in a departmental SQL Server database using DirectQuery, along with some data imported from a spreadsheet. A model that combines data from more than one DirectQuery source, or combines DirectQuery with imported data is referred to as a composite model.
Also, composite models include a new feature called dual storage mode. If you are using DirectQuery currently, all visuals will result in queries being sent to the backend source, even for simple visuals such a slicer showing all the Product Categories. The ability to define a table as having a storage mode of “Dual” means that a copy of the data for that table will also be imported, and any visuals that reference only columns from this table will use the imported data, and not require a query to the underlying source. The benefits of this are improved performance, and lessened load on the backend source. But if there are large tables being queried using DirectQuery, the dual table will operate as a DirectQuery table so no table data would need to be imported to be joined with an imported table.
Another feature due out in the next 90 days is “Aggregations” that allows you to create aggregation tables. This new feature along with composite models and dual storage mode allows you to create a solution that uses huge datasets. For example, say I have two related tables: One is at the detail grain called Sales, and another is the aggregated totals of Sales called Sales_Agg. Sales is set to DirectQuery storage mode and Sales_Agg is set to Import storage mode. If a user sends a query with a SELECT statement that has a GROUP BY that can be filled by the Sales_Agg table, the data will be pulled from cache in milliseconds since that table was imported (for example, 1.6 billion aggregated rows imported from SQL DW compressed to 10GB in memory). If a user sends a query with a GROUP BY for a field that is not in the Sales_Agg table, it will do a DirectQuery to the Sales table (for example, sending a Spark query to a 23-node HDI Spark cluster of 1 trillion details rows of 250TB, taking about 40 seconds). The user is not aware there is a Sales_Agg table (all aggregation tables are hidden) – they simple send a query to Sales and Power BI automatically redirects the query to the best table to use. And if using a Date table, it can be set to Dual mode so it joins with Sales_Agg in memory in the first part of the example, or joins with Sales on the data source using DirectQuery in the second part of the example (so it does not have to pull the 1 trillion detail rows into Power BI in order to join with the imported Date table).
So you can think of aggregations as a replacement for creating an Azure Analysis Services tabular data model, saving on cost and optimization work.
You will need to right-click the Sales_Agg table and choose “Manage aggregations” to map the aggregated Sales_Agg table columns to the detail Sales table columns. There is also a “Precedence” field that allows you to have multiple aggregation tables on the same fact table at different grains:
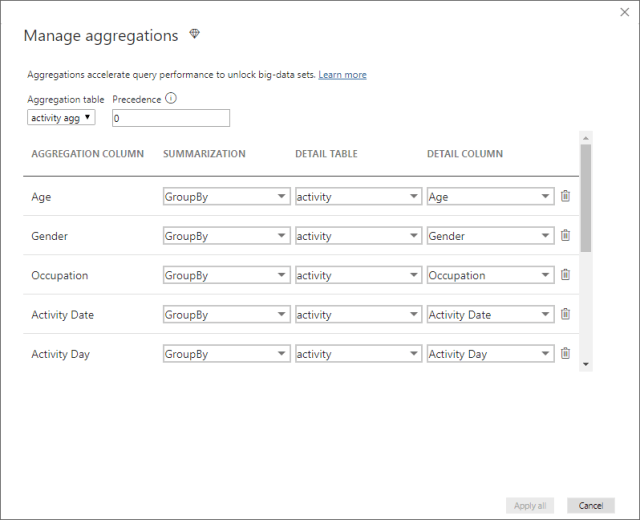
You can also create a report with a drillthrough feature where users can right-click on a data point in a report page that was built with an aggregation table and drillthrough to a focused page to get details that are filtered to that context that is built using DirectQuery.
So in summary, there are three values for storage mode at the table level:
- Import – When set to Import, imported tables are cached. Queries submitted to the Power BI dataset that return data from Import tables can only be fulfilled from cached data
- DirectQuery – With this setting, DirectQuery tables are not cached. Queries submitted to the Power BI dataset (for example, DAX queries) that return data from DirectQuery tables can only be fulfilled by executing on-demand queries to the data source. Queries submitted to the data source use the query language for that data source (for example, SQL)
- Dual – Dual tables can act as either cached or not cached, depending on the context of the query submitted to the Power BI dataset. In some cases, queries are fulfilled from cached data; in other cases, queries are fulfilled by executing an on-demand query to the data source
Note that changing a table to Import is an irreversible operation; it cannot be changed back to DirectQuery, or back to Dual. Also note there are two limitations during the preview period: DirectQuery only supports the tabular model (not multi-dimensional model) and you can’t publish files to the Power BI service.
More info:
Power BI Monthly Digest – July 2018
Composite models in Power BI Desktop (Preview)
Storage mode in Power BI Desktop (Preview)
Power BI Composite Models: The Good, The Bad, The Ugly
Composite Model; DirectQuery and Import Data Combined; Evolution Begins in Power BI
Video Building Enterprise grade BI models with Microsoft Power BI Premium
Video Building a data model to support 1 trillion rows of data and more with Microsoft Power BI Premium
Video Power BI and the Future for Modern and Enterprise BI
Video Introducing: Advanced data prep with dataflows—for unified data and powerful insights
Understanding Power BI Dual Storage
Video Microsoft Power BI Premium: Building enterprise-grade BI models for big data

![]()
