

Hadoop was created by the Apache foundation as an open-source software framework capable of processing large amounts of heterogeneous data-sets in a distributed fashion (via MapReduce) across clusters of commodity hardware on a storage framework (HDFS). Hadoop uses a simplified programming model. The result is Hadoop provides a reliable shared storage and analysis system.
MapReduce is a software framework that allows developers to write programs that perform complex computations massive amounts of unstructured data in parallel across a distributed cluster of processors or stand-alone computers. MapReduce libraries have been written in many programming languages (usually Java), with different levels of optimization. It works by breaking down a large complex computation into multiple tasks and assigning those tasks to individual worker/slave nodes and taking care of coordination and consolidation of the results. A MapReduce program is composed of a Map() procedure that performs filtering and sorting (such as sorting students by first name into queues, one queue for each name) and a Reduce() procedure that performs a summary operation (such as counting the number of students in each queue, yielding name frequencies).
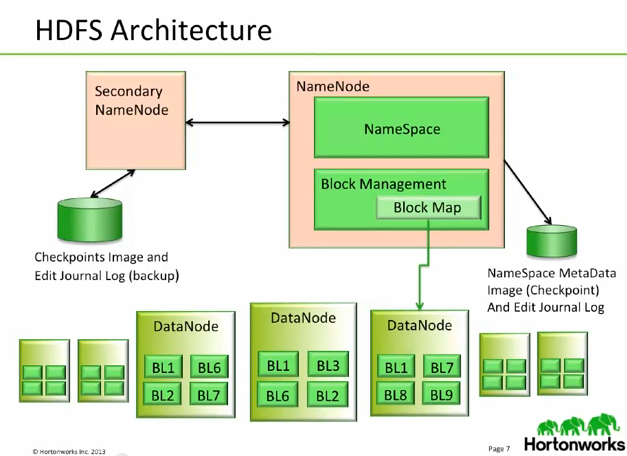
Hadoop Distributed File System (HDFS) is a distributed file-system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster. When data is pushed to HDFS, it will automatically split into multiple blocks and stores/replicates the data across various datanodes, ensuring high availability and fault tolerance.
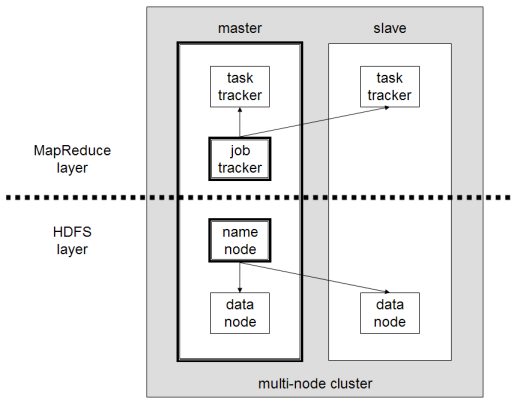
NameNode holds the information about all the other nodes in the Hadoop cluster, files present in the cluster, constituent blocks of files and their locations in the cluster, and other information useful for the operation of the Hadoop cluster. Each DataNode is responsible for holding the data. JobTracker keeps track of the individual tasks/jobs assigned to each of the nodes and coordinates the exchange of information and results. TaskTracker is responsible for running the task/computation assigned to it.
A small Hadoop cluster includes a single master and multiple worker nodes. The master node consists of a JobTracker, TaskTracker, NameNode and DataNode. A slave or worker node acts as both a DataNode and TaskTracker.
There are many other tools that work with Hadoop:
Hive is part of the Hadoop ecosystem and provides an sql-like interface to Hadoop. Hive uses MapReduce code to extract data from the Hadoop cluster. Hive is an open-source data warehouse system for querying and analyzing large datasets stored in Hadoop files. Hive supports queries expressed in a language called HiveQL, which automatically translates SQL-like queries into MapReduce jobs executed on Hadoop. Hive appeals to data analysts familiar with SQL.
Pig enables you to write programs using a procedural language called Pig Latin that are compiled to MapReduce programs on the cluster. It also provides fluent controls to manage data flow. Pig is more of a scripting language while Hive is more SQL-like. With Pig you can write complex data transformations on a data set such as aggregate, join and sort. It can be extended using User Defined Functions in Java and called directly by Pig.
While Hadoop is a natural choice for processing unstructured and semi-structured data like logs and files, there may be a need to process structured data stored in relational databases as well. Sqoop (SQL-to-Hadoop) is a tool that allows you to import structured data from SQL Server and SQL Azure to HDFS and then use it in MapReduce and Hive jobs. You can also use Sqoop to move data from HDFS to SQL Server.
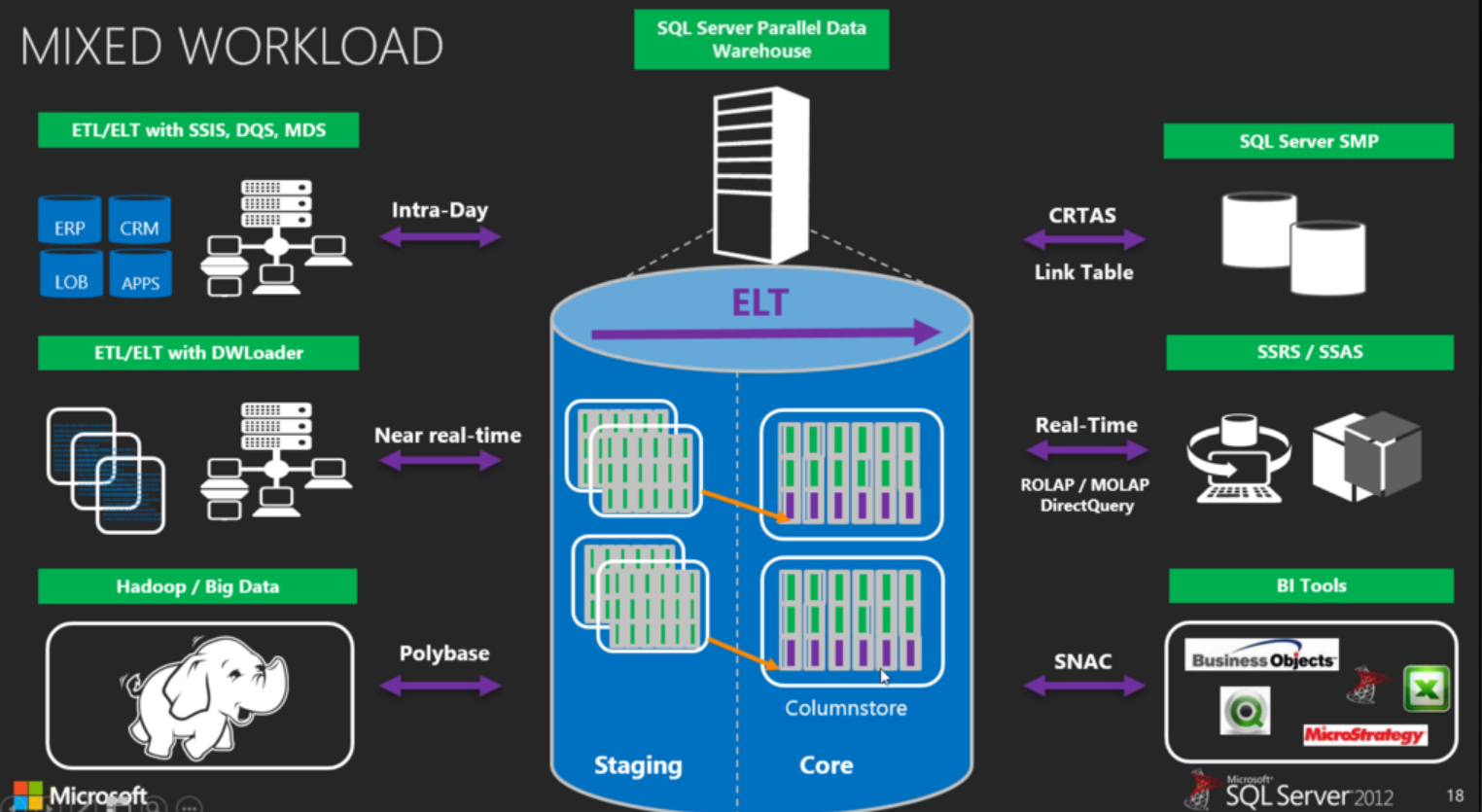
How Hadoop fits in with the Parallel Data Warehouse (PDW) and Polybase:
More info:
Big Data Basics – Part 3 – Overview of Hadoop
Video Hadoop Tutorial: Core Apache Hadoop
Hadoop Tutorial: Intro to HDFS
Hadoop: What it is, how it works, and what it can do
Hive Data Warehouse: Lessons Learned

![]()
