

When I wrote "Soundex - Experiments with SQLCLR" the resulting forum posts drew my attention to a number of weaknesses with the Soundex algorithm.
Soundex as implemented in SQL Server has around 7,000 possible values where as the English language has over 1 million words. Clearly there is huge scope for false matches as many words can generate the same Soundex code. In addition it makes no concessions to the fact that combinations of letters can make different sounds so will miss occurrences such as "Philip" and "Fillip".
Clearly something better than Soundex is required and fortunately there are quite a few good resources to look at.
- Nikita's blog lists a number of alternative phonetic algorithms
- The Apache Commons library contains actual Java implementations of the algorithms and adds ColognePhonetic
- Utilitymill.com allows you to test words against Soundex and NYSIIS and also take a look at the source code.
- Rosettacode.org provides many programming language implementations of common algorithms.
I decided to see if I could extend my "SoundexLong" function to take these into account. I also wanted to see if continuing the Test Driven Development approach helped or hindered further development.
The first step in doing so was to perform some basic analysis into the way that these algorithms work in order to understand the scope of the changes that would have to be made.
Basic analysis of the algorithms
A good starting point is to understand what algorithms are available and what they are used for. Those of interest are shown in the table below:-
| Algorithm | Purpose |
|---|---|
| Soundex | Simple character substitution algorithm originally designed for a manual name indexing system. |
| Refined Soundex | Slight enhancement to the original routine intended to reduce the number of false positives. Still a simple character substitution algorithm |
| ColognePhonetic | Very similar to Soundex but the encoding is to suit German pronounciation. |
| NYSIIS | New York State Identification and Intelligence System. Designed to cater for various Americanisations of European names. Starts to consider combinations (n-Grams) of letters and their changing role depending on their relative positions within a word. |
| Daitch-Mokotoff | Intended to cater for Jewish and Eastern European names. Again, starts to consider combinations of letters and their changing role depending on their relative positions within a word. Introduces the concept that multiple values may be returned |
| Caverphone | Intended to cater for New Zealand names. Largely a character substitution algorithm |
| Metaphone | Sophisticated algorithm sensitive to both combinations of letters and their relative positions in a word. Rules vary in complexity but there a large number to cater for multi-lingual usage. |
| Double-metaphone | Returns two phonetic codes for a given input to allow for multi-lingual pronounciations. Double-metaphone will match Schmidt and Smith |
I also characterised the types of transformations that each algorithm supported. Again these are summarised in the table below:-
| Algorithm | Character Substitution | Start Of Word | End Of Word | After Vowel | Combinations | Case Sensitive | Input < Output |
|---|---|---|---|---|---|---|---|
| Soundex | Y | Y | |||||
| Refined Soundex | Y | Y | |||||
| CoognePhonetic | Y | Y | |||||
| NYSIIS | Y | Y | Y | Y | Y | ||
| Daitch-Mokotoff | Y | Y | Y | Y | Y | ||
| Caverphone | Y | Y | Y | Y | Y | ||
| Metaphone | Y | Y | Y | Y | Y | Y | |
| Double-Metaphone | Y | Y | Y | Y | Y | Y |
The right-most column indicates that the number of substituted characters can exceed the number of characters being replaced. This is important as in my original article I looked to use a single character array iterating through deciding whether to ignore or overwrite characters as appropriate. An example of which is shown below.
Daitch-Mokotoff, ColognePhonetic and the Metaphone algorithms can replace a single 'X' with two characters. If we were to use a single character array then we would risk prematurely overwriting characters rather than considering them appropriately.
This means that we are certainly going to need to have a separate input array from an output array.
Design Decisions
The original function from my "Soundex - Experiments with SQLCLR" article had the following characteristics:
- Accepted a single argument, a string
- Converted the input argument to upper case effectively making the function case insensitive
- Returned a single string value
- Named the function SoundexLong
If I want to cater for a range of phonetic algorithms then I face a number of choices.
- Do I refactor my original code or build a new function that duplicates the functionality of the existing algorithm?
- Do I produce multiple separate functions thereby duplicating code or a single function with a parameter to indicate what I want the function to do?
All the decisions have undesirable implications either from a code complexity, code duplication or alteration of established code perspective. I am going to do the following:
- My original SoundexLong will remain as an immutable set of code
- I will have a single "LongPhonetic" function rather than multiple functions as I have learnt that end users lean towards simplicity and ease of use.
- I am going to duplicate my SoundexLong code to form the starting point for LongPhonetic and refactor it to achieve the desired result
It is quite possible that these decisions will return to haunt me, however, we have to start somewhere. Attempt a course of action but do so in such a way that identifies as quickly as possible if it is a dead end. This is the principle of "failing fast" and allows us to develop a strategy for failure that removes fear and doubt. Such a strategy gives us a number of advantages:
- Failure has to be viewed as a learning experience. A success is great but we learn more from our failures.
- Avoids analysis paralysis. Fear and doubt can lead to analysis paralysis in an attempt to avoid failure
- Allows us to take less timid steps and therefore open up potentially greater rewards.
Step One - Addressing some technical debt
jimbobmcgee gave constructive feedback to my original article pointing out that my implementation of an IsLetter() function was unnecessary as a char object has an inbuilt IsLetter() function. To correct this I simply changed both occurences of IsLetter in my code with char.IsLetter
if(!char.IsLetter(inputArray[0]))
if (char.IsLetter(inputArray[currentCharacterPosition]))Step Two - Refactoring for an outputArray
Given that Daitch-Mokotoff and Metaphone necessitate a 2nd array the next step was to change my code to read from the inputArray[] and write to the outputArray[]. At this stage I don't need to know how long I to make the outputArray as I am simply refactoring my code. Making it the same length as the inputArray[] will suffice.
char[] inputArray = InputString.ToUpper().ToCharArray();
char[] outputArray = new String(' ', inputArray.Length).ToCharArray();
return new string(inputArray).Trim();
return new string(outputArray).Trim();- currerntCharacterPosition = The position we read from within the original input string
- validCharacterPosition = The position we write to in the target array, initially inputArray[] but to be changed to outputArray[]
It turns out we need a bit of code to cater for the first character of the input argument being a letter.
if (!char.IsLetter(inputArray[0]))
{
inputArray[0] = ' ';
}
else
{
outputArray[0] = inputArray[0];
}Valid criticism of Test Driven Development
- Answer the question "What is the acceptance criteria that would demonstrate that this piece of functionality will deliver what it should"?
- Develop a test that expresses that acceptance criteria and will only pass if your code meets that criteria.
- Write the code to pass the test
- Refactor mercilessly
Frameworks such as Cucumber with its Gherkin language address these points because the common language in which tests are defined is separate from the implementation of the items that for which the tests apply. By having the separation between the language defining the tests and the language implementing the tests it means that if you took the decision to replatform your application from one language to another all your tests would remain valid for your new application.
Step Three - Refactoring my function to accept an additional argument
So far my LongPhonetic() function (refactored from SoundexLong in my original article) accepts a single string argument. All I am going to do at this stage is change the signature of my function and refactor all the tests so they are proven to work. I am NOT going to implement the selection of phonetic algorithms at this stage.
[Microsoft.SqlServer.Server.SqlFunction (IsDeterministic=true,IsPrecise=true)]
public static SqlString LongPhonetic(short PhoneticType,String InputString)
#region LongPhonetic() tests
[TestMethod]
public void StartUpTest()
{
Assert.AreEqual("D", Phonetics.LongPhonetic(0, "D"));
}
[TestMethod]
.....
#endregion
Step Four - Acting on the additional argument
I could implement the selection of a phonetic algorithm by building up a complicated series of if() statements. Although I could make it work the code would become increasingly unwieldy as more algorithms are implemented.
Ideally what I need is a variable that acts as if it were a function so I could set this at the start of the function and keep the heavy lifting as simple as possible. Fortunately we can do this by using a .NET delegate as shown in the code below.
using System;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
delegate Char PhoneticAlgorithm(Char a);
public partial class Phonetics
{
[Microsoft.SqlServer.Server.SqlFunction(IsDeterministic=true,IsPrecise=true)]
public static SqlString LongPhonetic(short PhoneticType,String InputString)
{
PhoneticAlgorithm phoneticAlgorithm;
switch (PhoneticType)
{
case 0:
phoneticAlgorithm = new PhoneticAlgorithm(SoundexChar);
break;
default:
phoneticAlgorithm = new PhoneticAlgorithm(SoundexChar);
PhoneticType = 0;
break;
}The code works as follows:-
- The "PhoneticAlgorithm" delegate is simply a signature of a function accepting a Char and returning a Char
- We declare the variable phoneticAlgorithm to be of type "PhoneticAlgorithm"
- We instantiate the variable phoneticAlgorithm as a function object matching the signature and return for the delegate. In this case SoundexChar (as described in my original article) irrespective of what the value of our additional "PhoneticType" argument may be.
Compile and run the tests to check everything is working before moving onto the next stage.
Step Five - Implementing our delegate?
I eventually want to be able to use my additional argument to specify which phonetic algorithm I will use but right now I want to run my existing code and also to default to using my existing algorithm should any other value be specified. Again this means refactoring my tests to prove that other values for the phonetic type argument work as expected.
#region LongPhonetic() tests
[TestMethod]
public void StartUpTest()
{
Assert.AreEqual("D", Phonetics.LongPhonetic(0, "D"));
Assert.AreEqual("D", Phonetics.LongPhonetic(99, "D"));
}
[TestMethod]
.....
#endregion
// If not a double occurrence of either characters or phonetic codes
if (!((outputArray[validCharacterPosition] == inputArray[currentCharacterPosition]) ||
outputArray[validCharacterPosition] == SoundexChar(inputArray[currentCharacterPosition])))
{
// Only increment the validCharacterPosition if it is not a vowel
if (outputArray[validCharacterPosition] != '0')
{
validCharacterPosition++;
}
outputArray[validCharacterPosition] = SoundexChar(inputArray[currentCharacterPosition]);
}
// If not a double occurrence of either characters or phonetic codes
if (!((outputArray[validCharacterPosition] == inputArray[currentCharacterPosition]) ||
outputArray[validCharacterPosition] == phoneticAlgorithm(inputArray[currentCharacterPosition])))
{
// Only increment the validCharacterPosition if it is not a vowel
if (outputArray[validCharacterPosition] != '0')
{
validCharacterPosition++;
}
outputArray[validCharacterPosition] = phoneticAlgorithm(inputArray[currentCharacterPosition]);
}Step Six - Adding a new phonetic algorithm
So far we have made quite a few changes simply to refactor our code to the point where it delivers exactly the same as it did before we started. We are now ready to implement a 2nd phonetic algorithm that will better demonstrate what we are trying to achieve.
By far the simplest algorithm to implement is the refined Soundex algorithm as it is the same method with additional character encodings.
| Encoded Value | Soundex | Refined Soundex |
|---|---|---|
| 1 | B,P,F,V | B,P |
| 2 | C,S,G,J,K,Q,X,Z | F,V |
| 3 | D,T | C,K,S |
| 4 | L | G,J |
| 5 | M,N | Q,X,Z |
| 6 | R | D,T |
| 7 | L | |
| 8 | M,N | |
| 9 | R |
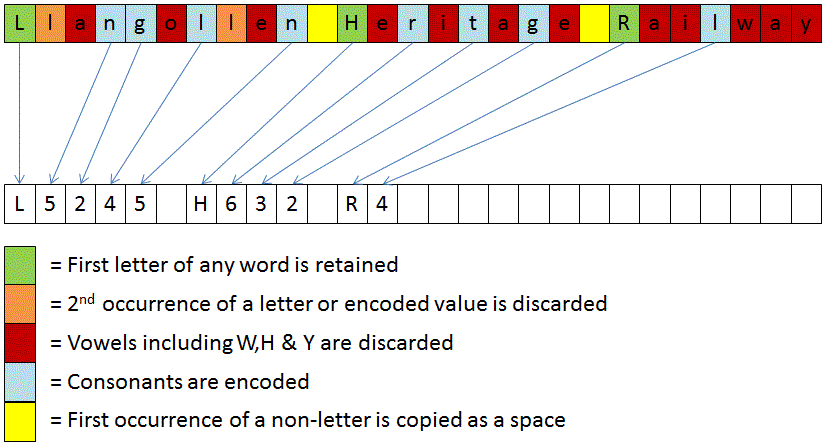
Again, the starting point is to refactor our tests so a phonetic type of one indicates that refined Soundex should be used. An example of a refactored test is shown below.
[TestMethod]
public void LlangollenHeritageRailwayTest()
{
Assert.AreEqual("L5245 H632 R4", Phonetics.LongPhonetic(0, "llangollen heritage railway"));
Assert.AreEqual("L8478 H964 R7", Phonetics.LongPhonetic(1, "llangollen heritage railway"));
Assert.AreEqual("L5245 H632 R4", Phonetics.LongPhonetic(99, "llangollen heritage railway"));
}
/// <summary>
/// For a given character return the raw refined soundex value. If the argument is not a letter then return a space.
/// </summary>
/// <remarks>Refined Soundex works in the same way as normal Soundex but assigns digits from 1 to 9 as opposed to 1-6.</remarks>
/// <param name="a">The character to be evalutated.</param>
/// <returns></returns>
private static Char RefinedSoundexChar(Char a)
{
switch (a)
{
case 'A':
case 'E':
case 'I':
case 'O':
case 'U':
case 'W':
case 'H':
case 'Y':
a = '0';
break;
case 'B':
case 'P':
a = '1';
break;
case 'F':
case 'V':
a = '2';
break;
case 'C':
case 'K':
case 'S':
a = '3';
break;
case 'G':
case 'J':
a = '4';
break;
case 'Q':
case 'X':
case 'Z':
a = '5';
break;
case 'D':
case 'T':
a = '6';
break;
case 'L':
a = '7';
break;
case 'N':
case 'M':
a = '8';
break;
case 'R':
a = '9';
break;
default:
a = ' ';
break;
}
return a;
}
PhoneticAlgorithm phoneticAlgorithm;
switch (PhoneticType)
{
case 0:
phoneticAlgorithm = new PhoneticAlgorithm(SoundexChar);
break;
case 1:
phoneticAlgorithm = new PhoneticAlgorithm(RefinedSoundexChar);
break;
default:
phoneticAlgorithm = new PhoneticAlgorithm(SoundexChar);
PhoneticType = 0;
break;
}Step Seven - Retiring unnecessary code
while (validCharacterPosition < currentCharacterPosition)
{
outputArray[validCharacterPosition++] = ' ';
}Step Eight - Further refactoring
while (currentCharacterPosition < inputArray.Length)
{
...
}- validCharacterPosition
- currentCharacterPosition
- inputArray
- outputArray
- phoneticAlgoritm
while (currentCharacterPosition < inputArray.Length)
{
SimpleSoundex(ref validCharacterPosition,ref currentCharacterPosition,inputArray,outputArray,phoneticAlgorithm);
currentCharacterPosition++;
}
private static void SimpleSoundex(ref int validCharacterPosition, ref int currentCharacterPosition, char[] inputArray, char[] outputArray,PhoneticAlgorithm phoneticAlgorithm)
{
// If start of word
if (outputArray[validCharacterPosition] == ' ')
{
......
}
}
Achievements so far
It may seem that we have made a lot of changes so far to achieve very little. We have actually achieved more than would appear at first glance.
- Addressed some technical debt
- Refactored our code to split the inputArray from the outputArray and used existing tests to show the refactoring has been successful
- Refactored our code and tests to accept an additional argument and act on it. The tests show that the code produces the desired results
- Refactored our code to lay the foundation stones to be able to plug in further phonetic algorithms.
In short we have taken a series of small steps to get to the point where we have a working function in a fit state for deployment that implements two phonetic algorithms.
New algorithms, new Challenges
One challenge we have to face when implementing the more complex phonetic algorithms is that we have to consider more character relationships.
- We need to be capable of matching a contiguous occurrence
- We need to determine the location of the occurrence (beginning of word, end of word, after vowel, relative to other combinations
- We need to be capable of deciding appropriate encoding for that occurence
- We need to consider cases such as the letter 'X' which encodes to two characters
Problems with the current approach
Looking at the code I have written it is becoming apparent that the approach I have used up to now is not suitable to meet the challenges for the more complex phonetic algorithms.
It is clear that a number of functions and methods are needed. As the functions are static methods of a static class we cannot maintain state for our validCharacterPosition and currentCharacterPosition variables. Although we are addressing this by passing the variables between the various functions by reference it will make messy and convoluted code if we continue to do so.
Clearly a more radical rethink is needed and that will be a subject for the next article.
