

Introduction
Why don't you partition your table if you have millions of rows and get complaints about the degradation of performance?
This is the question I asked my friend and I was amazed to find out he, along with many people, wasn't aware of this feature of SQL Server. This feature was first made available in SQL Server 2005, and today I will discuss what partitioning is.
Partitioning is a feature designed to improve the performance of queries made against a very large table. It works by having more than one subset of data for the same table. All the rows are not directly stored in the table, but they are distributed in different partitions of this table. When you query the table looking for data in a single partition, or just a few, then due to the presence of these different subsets, you should receive a quicker response from the server.
There has been a long history, in SQL Server, as this feature has evolved. It first started with partitioned views. A developer had to create different tables having same schema and use these tables through a UNION operation in a view. Now after 2005, your tables and indexes can also be partitioned. This feature is further improved upon in SQL Server 2008.
SQL Server only supports one type of partitioning, which is Range Partitions. More specifically I should say 'Horizontal Range Partitions'. This the partitioning strategy in which data is partitioned based on the range that the value of a particular field falls in. The other partitioning types are reference, hash, list etc. partitions, which are not supported currently in SQL Server.
Simply saying, when we partition a table, we define on which portion of a table a particular row will be stored. Now you must be wondering what would be the criterion that a specific row would be saved in a particular partition. There are actually rules defined for ranges of data to fill a particular partition. These ranges are based on a particular column; this is called the Partition Key. It should be noted that these ranges are non-overlapping. To achieve this, a Partition Function and a Partition Scheme is defined.
There might be many questions in your mind. Let's go step by step. We start with the terminologies used in Partitioning.
PARTITION FUNCTIONS
The Partition Function is the function that defines the number of partitions. This is the first step in the implementation of partitioning for your database object. One partition function can be used to partition a number of objects. The type of partition is also specified in the partition function, which currently can only be 'RANGE'.
Based on the fact about boundary values for partitions that which partition they should belong to, we can divide partition function into two types:
- Left: The first value is the maximum value of the first partition.
- Right: The first value is the minimum value of the second partition.
The syntax for the creation of a partition function is as follows:
CREATE PARTITION FUNCTION partition_function_name ( input_parameter_type )
AS RANGE [ LEFT | RIGHT ]
FOR VALUES ( [ boundary_value [ ,...n ] ] ) [ ; ]
e.g.
Generally the input_parameter_type is numeric. SQL Server supports only certain input_parameter_types. The list of partition functions defined can be obtained by using the SYS.PARTITION_FUNCTIONS catalog view:
SELECT * FROM sys.partition_functions
The first thing that you would want to do is to test whether your partition function is implemented as per your desire or not. Specially, we can check if it is working on boundary values. You can check it with the special function provided: $Partition. We test the partition function MyPartitionFunc2 created by us earlier. In this SQL, we are verifying to which partition, (Partition Key = 100), would belong to.
SELECT $PARTITION.MYPARTITIONFUNC2(100) [PARTITION NUMBER]
To find out the boundary values defined by partition functions, partition_range_values catalog view is available.
SELECT * FROM SYS.PARTITION_RANGE_VALUES
Though SQL Server does not directly support List Partitioning, you can create list partitions by tricking the partition function to specify the values with the LEFT clause. After that, put a CHECK constraint on the table, so that no other values are allowed to be inserted in the table specifying Partition Key column any value other than the 'list' of values.
PARTITION SCHEME
This is the physical storage scheme that will be followed by the partition. To define scheme, different file groups are specified, which would be occupied by each partition. It must be remembered that all partitions may also be defined with only one file group.
After the definition of a partition function, a partition scheme is defined. The partition scheme just like specifying an alignment for data i.e. it specifies the specific file groups used during partitioning an object. Though it is possible to create all partitions on PRIMARY but it would be best if these different partitions are stored in a separate file groups. This gives some performance improvement even in the case of single core computers. It would be best if these file groups are on different discs on a multi core processing machine.
The syntax for creating partition schema is as follows:
CREATE PARTITION SCHEME partition_scheme_name
AS PARTITION partition_function_name
[ ALL ] TO ( { file_group_name | [ PRIMARY ] } [ ,...n ] )
[ ; ]
The list of partition schemes can be obtained by using the SYS.PARTITION_SCHEMES.
SELECT * FROM SYS.PARTITION_SCHEMES
To get the list of all data spaces SYS.DATASPACES catalog view may be used:
SELECT * FROM SYS.DATA_SPACES
PARTITIONED TABLE
After creation of a partition scheme, a table may be defined to follow that scheme. In this case the table is called PARTITIONED. A partitioned table may have a partitioned index. Partition aligned index views may also be created for this table. These index and view may be based on different partition strategy (partition function and partition scheme).
There may be question in your mind if it is possible to partition your table using multiple columns. The answer may be YES or NO. Why? No, because there is no such direct support for this in SQL Server. Yes, because you can still do that by using persisted computed column based on any number of columns you want. It must be remembered that this is still a single dimension partition.
Now you might be wondering whether your existing tables could be partitioned or not. For partitioning your existing table just drop the clustered index on your table and recreate it on the required partition scheme.
CREATE TABLE
[ database_name . [ schema_name ] . | schema_name . ] table_name
( { <column_definition> | <computed_column_definition> }
[ <table_constraint> ] [ ,...n ] )
[ ON { partition_scheme_name ( partition_column_name ) | filegroup
| "default" } ]
[ { TEXTIMAGE_ON { filegroup | "default" } ] [ ; ]
SQL Server 2008 has introduced an exciting new feature, 'FileStream'. Remember if you have any column specified which is based on filestream data, you have to follow some additional steps to get things to work with partitioning.
PARTITIONED INDEX
We can also partition our indexes, and this should contribute to improved performance. If indexes are partitioned they serve as the local indexes for each partition. We can also go with Global indexes on a partitioned table without caring about the different partitions of the table.
It must be remembered that indexes can be partitioned using a different partition key than the table. The index can also have different numbers of partitions than the table. We cannot, however, partition the clustered index differently from the table. To partition an index, ON clause is used, specifying the partition scheme along with the column when creating the index:
CREATE NONCLUSTERED INDEX MyNonClusteredIndex ON dbo.MyTable(MyID1)
ON MyPartitionScheme(MyID2);
You can see that Mytable is indexed on the MyID1 column, but the index is partitioned on the MyID2 column. If your table and index use the same Partition function then they are called Aligned. If they go further and also use the same partition scheme as well, then they are called Storage Aligned (note this in the figure below). If you use the same partition function for partitioning index as used by the table, then generally performance is improved.
PARTITION ALIGNED INDEX VIEWS
Partition aligned index views allow to efficiently create and manage summary aggregates in relational data. The query results are materialized immediately and persisted in physical storage in the database. This is an extension of Indexed views which existed in SQL Server 2005. Earlier, it was difficult to manage index views on partitioned table. This is because switching in and out the partition was not possible as the data was not distributed in a partitioned way in the indexed view. Indexed views were required to be dropped before this operation. In SQL Server 2008, this became possible with the introduction of Partition Aligned Index Views. In this way Indexed views have now evolved to become 'Partition Aware'.
It is said that these types of index views increase the speed and efficiency of queries on the partitioned data. The following conditions should be true if an index view has to be partition aligned with the table on which this view is defined.
- The partition functions of the indexes of the indexed view and table must define the same number of partitions, their boundary values and the partition must be based on the same column.
- The projection list of the view definition includes the partitioning column (as opposed to an expression that includes the partitioning column) of the partitioned table.
- Where the view definition performs a grouping, the partitioning column is one of the grouping columns included in the view definition.
- Where the view references several tables (using joins, sub queries, functions, and so on), the indexed view is partition-aligned with only one of the partitioned tables.
These views can be local or distributed. The local partitioned index view is the one in which all partitions lie on the same SQL Server instance. For a distributed one, different partitions of tables, queried in single view, reside on different SQL Server instances across the network. The distributed partitioned views are specially used to support federation of SQL Server instances.
Enough Study, Let's Practice!
CREATE A PRACTICE DATABASE
Before looking at an example implementation of partitioning, let us create a new database to test this feature. Let us create a database with two file groups FG1 and FG2. Make sure that you create PartitionPractice folder in C directory before running the following query:
USE master
GO
CREATE DATABASE MyPartitionPracticeDB
ON PRIMARY
( NAME = db_dat,
FILENAME = 'c:\PartitionPractice\db.mdf',
SIZE = 4MB),
FILEGROUP FG1
( NAME = FG1_dat,
FILENAME = 'c:\PartitionPractice\FG1.ndf',
SIZE = 2MB),
FILEGROUP FG2
( NAME = FG2_dat,
FILENAME = 'c:\PartitionPractice\FG2.ndf',
SIZE = 2MB)
LOG ON
( NAME = db_log,
FILENAME = 'c:\PartitionPractice\log.ndf',
SIZE = 2MB,
FILEGROWTH = 10% );
GO
USE MyPartitionPracticeDB
GO
1. STEP # 01 (Create partition function)
CREATE PARTITION FUNCTION partfunc (int) AS
RANGE LEFT FOR VALUES (1000, 2000, 3000, 4000, 5000);
2. STEP # 02 (Create partition scheme)
CREATE PARTITION SCHEME MyPartitionScheme AS
PARTITION MyPartfunc TO
([FG1], [FG2])
GO
3. STEP # 03 (Create table or index based on the partition scheme)
The important clause related to partitioning is ON clause in CREATE TABLE statement. We create our table MyPartitionedTable as follows:
CREATE TABLE MyPartionedTable
(
ID int PRIMARY KEY,
Name VARCHAR(50)
)
ON MyPartitionScheme(ID)
GUI SUPPORT FOR PARTITIONING
Great GUI support is provided in SQL Server 2008 for partitioning. If you see the properties of a table, you can easily find partition related properties under the Storage tab.
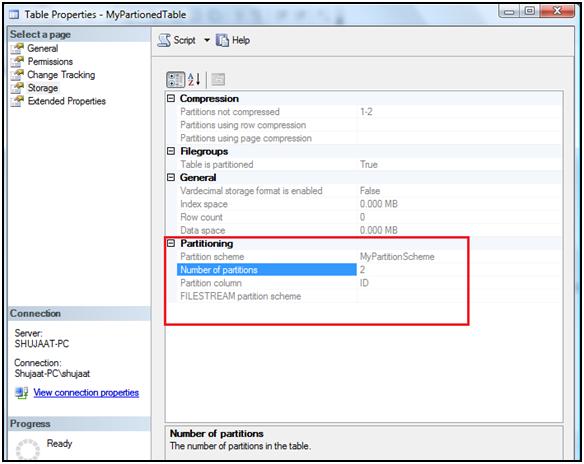
There is no support of partitioning at the time of table creation, but later you can use the wizard for partitioning. There is a new partitioning wizard introduced in SQL Server 2008 Management Studio.
CREATE PARTITIONS
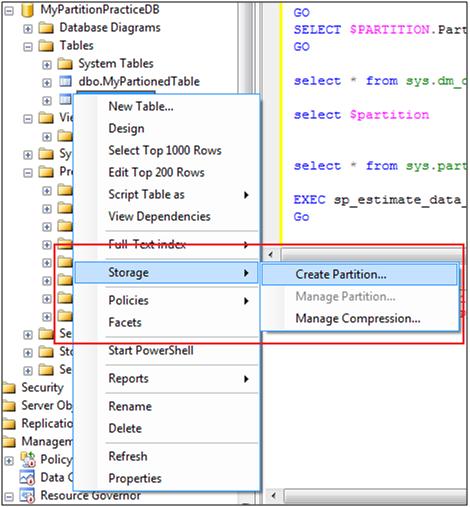
After the creation of a non-partitioned table, it can then be partitioned. To ensure the ease of partitioning, GUI support is available in SQL Server Management Studio. Not only can you create partitions in a non-partitioned table but you can also manage partitions in an already partitioned table.
Just right click a non-partitioned table and look at the following pop-up menu i.e. the Create Partition option under Storage menu:
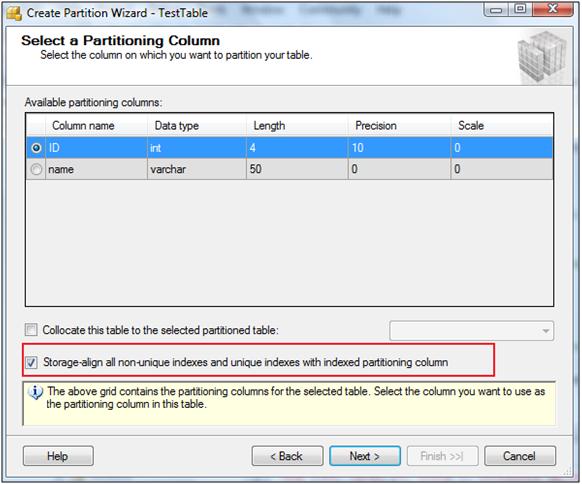
When you select this option, an easy to use wizard is started to allow you to create partitions. Remember, you can also use already existing partition functions and scheme to partition a table. You can also create new ones and the wizard allows you to enter the details for the partition function, it allows the LEFT or RIGHT options, and for entering the details of the partition scheme. It also asks for the details of file groups for new partitions.
This wizard is very easy to use and allows the developer to generate partition functions, partition schemes and other options if none of the already existing ones fits the user's needs. There are also some third party solutions available to manage partitioning of your objects outside SQL Server Management Studio.
ADDITIONAL OPERATIONS WITH PARTITIONS
SQL Server also supports other operations with partitions. These operations help in managing a partitioned object. They are as follows:
1. Split
2. Merge
3. Switch
Remember that these operations are meta data operations and do not involve any movement of data.
ADDING A NEW PARTITION
This operation is supported to accommodate the continuous changes when a new Partition needs to be added if the already existing partitions are very large. This is technically called a Partition Split. ALTER TABLE statements support partition split with the required options. To split a partition, the ALTER PARTITION FUNCTION statement is used.
ALTER PARTITION FUNCTION MyPartitionFunction()
SPLIT RANGE (5000)
But before splitting, a new file group must be created and added to the partition scheme using the partition function being modified, otherwise, this statement would cause an error while executing.
REMOVING AN EXISTING PARTITION
The Merge operation is used to remove an existing partition. The syntax of MERGE statement is nearly the same as the SPLIT statement. This statement would remove the partition created in SPLIT command shown before this.
ALTER PARTITION FUNCTION MyPartitionFunction ()
MERGE RANGE (5000)
SWITCHING A PARTITION
This operation is used to switch a partition in or out of a partitioned table. It must be remembered that for switching in, the already existing partition must be empty within the destination table. In the following example, we are switching in a table MyNewPartition as 4th partition to MyPartitionedTable.
ALTER TABLE MyNewPartTable switch TO MyPartitionedTable PARTITION 4
In the following example we are switching partition 3 out to a table MyPartTable:
ALTER TABLE MyPartitionedTable switch PARTITION 4 TO MyNewPartTable
We partitioned our table because of large amount of data. In order to speed up data retrieval, we have incorporated several indexes on our table. This would certainly help in satisfying the query requirements of users, but it adds additional time while updating or adding records to the table given the large amount of data in the table. So it is better that we insert our records in an empty table, which is exactly same as the partitioned table. Insert new records in that table and then switch that partition into the partitioned table. We discuss this further as we will be discussing the Sliding Window Technique.
The requirement for the table when switching in and out of a partition means that both of them must also have same clustered and non-clustered indexes, and additionally, the same constraints.
PARTITIONING AND PARALLEL EXECUTION:
If you have multiple processing cores on your server then partitioning your large tables could also result in more optimized parallel execution plans by the database engine. It must be remembered that in SQL Server 2005, a single thread was created per partition (at max). So if there are less number of partitions then the number of processors, all the cores were not optimally utilized and some processors used to be sitting idle. With SQL Server 2008, this restriction has been removed. Now all processors can be used to satisfy the query requirement.
When SQL Server uses parallel execution plan for partition tables, you can see Parallelism operator in the execution plan of the query. In actual there are multiple threads working on different partitions of the table. Each partition is processed by a single thread. We can control parallel plan of our queries by using MAXDOP hint as part of query or plan guide. First we see how we could control the degree of parallelism using query hints:
SELECT * FROM MyPartitionedTable
ORDER BY OrderDate DESC
OPTION (MAXDOP 4)
The plan can also be created to support parallelism:
EXEC sp_create_plan_guide
@name = N'Guide1',
@stmt = N'SELECT * FROM MyPartitionedTable
ORDER BY OrderDate DESC',
@type = N'SQL',
@module_or_batch = NULL,
@params = NULL,
@hints = N'OPTION (MAXDOP 4)';
Remember if you are creating a custom plan guide for your query then you must not have specified (Maximum Degree Of Parallelism) MAXDOP = 1 as an option. Additionally the configuration option of maximum degree of parallelism for the server should be appropriately set.
sp_configure 'show advanced options', 1;
GO
RECONFIGURE WITH OVERRIDE;
GO
sp_configure 'max degree of parallelism', 0;
GO
RECONFIGURE WITH OVERRIDE;
GO
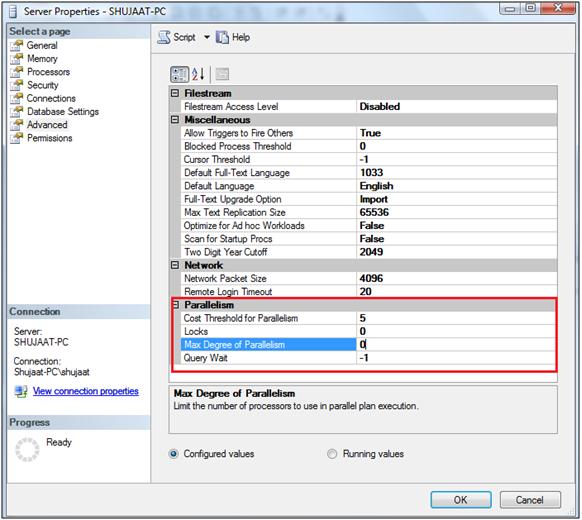
You can also set the configuration settings of the instance from the Properties window of the instance selected from the object explorer in the SQL Server Management Studio.
MULTITHREADED PARTITION ACCESS
Threading support for partitions has also been improved in SQL Server 2008. Earlier in 2005 one thread was assigned to each partition. So if there are e.g. 40 threads available and table has only 2 partitions then only 2 threads may be utilized for accessing these partitions' data. In 2008, all the partitions are accessed by all the available threads. These threads access table partitions in a round robin fashion.
You need to make sure that the 'max worker thread' configuration is properly set for your SQL Server instance.
SELECT * FROM SYS.CONFIGURATIONS
WHERE NAME = 'max worker threads'
This feature is also important in the case of non-partitioned table. This is because back in 2005 if we had large amounts of data in a non-partitioned table then only one thread was available to it. Now in 2008 all the available thread could utilize it which results in boosting the performance of data access.
Many operations can be done in parallel due to partitioning like loading data, backup and recovery and query processing.
SLIDING WINDOW TECHNIQUE
SQL Server cannot have an unlimited number of partitions. The limitation is 1000 partitions in 2005. Based on this limitation we cannot switch in partitions forever. So, how to resolve this? The Sliding Window Technique is the answer.
According to this technique, a table always has some specified number of partitions. As the new partition comes, the oldest partition is switched out of the table and archived. This process can goes on forever. Additionally, this should be very fast to do since it is a metadata operation.
This technique could give a drastic boost in performance based on the fact that so long as data is being loaded into the source staging table, your partitioned table is not locked at all. You can even improve that using bulk inserts. After it is loaded the switching in process is basically a metadata operation.
This process is so regular that you can automate this using dynamic SQL. The tasks to be followed are as follows:
- Managing staging tables for switching in and out the partitions.
- Switching new partition in and old partition out of the table.
- Archive staging table in which data is archived and remove both staging tables.
LOCK ESCALATION AND PARTITIONING
Lock escalation is the process of converting many fine-grain locks into fewer coarse-grain locks, reducing system overhead. SQL Server 2005 supports lock escalation on only the table level. Now in SQL Server 2008, lock escalation is also supported on the partition Level. This was introduced to improve the availability of data in the partitioned table. This is not the default behavior but it can be changed for any table. So changing this option can further improve the performance for querying your table.
If you want to find out about lock escalation for any of your existing tables then you can check it from TABLES table in SYS schema.
SELECT lock_escalation_desc FROM sys.tables WHERE name = 'MyPartitionedTable'
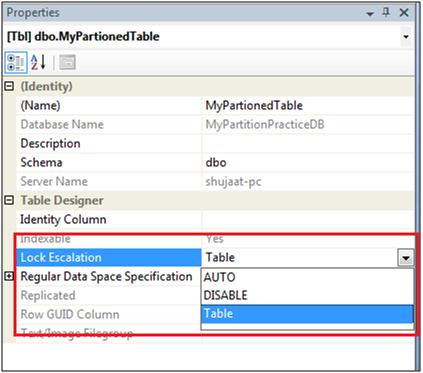
You can change the new LOCK_ESCALATION property of any of your existing table. The possible options are as follows:
1. Auto: This option lets the SQL Server decides whether table is partitioned or not. If the table is partitioned, it is on partition level otherwise it is on table level.
2. Table: The lock escalation will always be on the table level no matter if the table is partitioned or not. This is the same behavior as in SQL Server 2005. This is also the default behavior in SQL Server 2008.
3. Disable: This prevents lock escalation in most cases. Table-level locks are not completely disallowed e.g. when you are scanning a table that has no clustered index under the serializable isolation level, the database engine must take a table lock to protect data integrity.
After you are done with partitioning your table set the LOCK_ESCALATION on the table to AUTO so that database engine may allow locks to escalate on the partition i.e. HoBT (Heap or Binary Tree) level for the said table.
ALTER TABLE MyPartitionedTable SET (LOCK_ESCALATION = AUTO)
It must be remembered that if the partition level escalation option is not implemented correctly, this may create some deadlock problems for the clients expecting table level lock escalation. This is the reason this is not the default option.
You can also specify the lock escalation settings by changing the properties of your table.
You can view the locking details in your server by using the sp_lock stored procedure.
COLLOCATION
This is a strong form of alignment. In collocation, objects are joined with an equijoin predicates. These predicates use columns which are partitioning columns. They are useful in writing queries that run way faster than regular queries. These are used by the tables, which are partitioned using the same partition key, and the same partition function is used to partition them.
To ease the creation of partitions in an un-partitioned table, collocation support is provided in the wizard to specify the collocation table. This collocation table is used to copy the definition of partition settings and we don't need to specify the partition settings again for each table having the same partition settings.
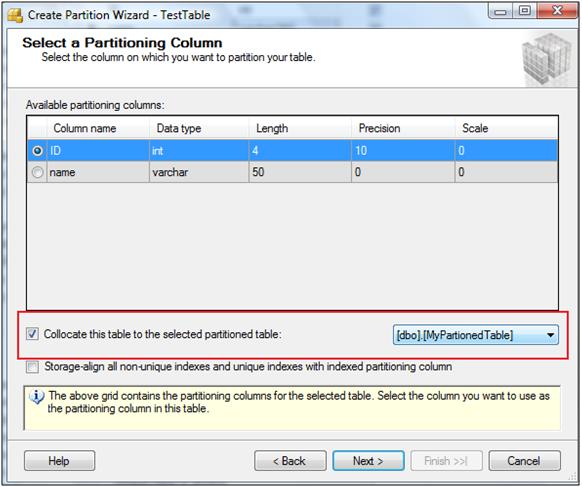
Though, In T-SQL there is no support for specifically specifying the collation table, this option has been added in this wizard to provide ease of partitioning a table. On the performance side, if two tables are collocated then extraordinary performance can be expected in joins.
PARTITION ELIMINATION / PRUNING
This is the process used by the optimizer to figure out which partitions are necessary to access in order for SQL Server to provide the results of any query. It means those partitions that do not fulfill the criteria of the query are not even checked to find the result. The optimizer figures this out based on the filter specified in the query. These filters are specified in WHERE, IN or other filtering clauses.
If you want to know if the database engine is using partition elimination while executing your queries then run SET STATISTICS PROFILE ON command before running your queries. We can see the partition elimination in the execution plan of the following query:
SELECT * FROM [MYPARTITIONPRACTICEDB].[DBO].[MYPARTIONEDTABLE]
WHERE ID > 1001
To find out which partition are used to satisfy the required query result, we can look at <RunTimePartitionSummary> in the XML plan of execution.
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="1">
<PartitionRange Start="2" End="2" />
</PartitionsAccessed>
</RunTimePartitionSummary>
It is apparent that only 2nd partition is used and the other partition is not part of the search.
There are two types of partition elimination schemes that SQL Server may use. They are as follows:
- Static Partition Elimination
- Dynamic Partition Elimination
As appears from the name, with Dynamic Partition Elimination scheme, the decision about selection of partitions, to satisfy the query criteria, is made at the query execution time.
Now you must be wondering how SQL Server decides which scheme to use. You will be glad to know that in SQL Server 2008 the dynamic partition elimination is much more efficient than in SQL Server 2005.
PARTITIONING AND COMPRESSION
After the long debate about CPU versus data size, your organization might have decided to include compression in your design. Don't forget that you have taken your partitioning strategy into consideration how it would be affected by this new world order.
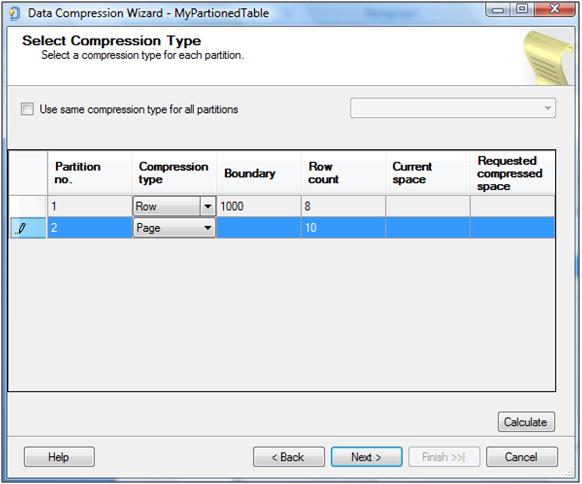
The good thing is that you can employ compression in your partitions as well. The greatest part is that different partitions may have different compression settings.
All of you who have played around with this feature (compression) know that the first step in compressing any object is to see whether or not compression would be beneficial for the object. The sp_estimate_data_compression_savings stored procedure is available to help with this. The report generated by this stored procedure contains information about expected benefits of compression for each partition individually.
Let us check our table 'MyPartitionedTable' and see how compression could benefit us. Since we have no data in the table, first we insert some rows into the table.
SUPPORTED EDITIONS:
It must be noted that the partitioning feature is only supported on the Enterprise Edition of SQL Server 2008. So, if you backup your database, in which you have used this feature, and try to restore it on a lower edition, this will not be possible.
To check if this feature is being used on your SQL Server instance, you can use sys.dm_db_persisted_sku_features dynamic management view introduced in 2008.
Author:
My name is Muhammad Shujaat Siddiqi. I am B.E in Computer and Information Systems from NED University, Karachi. Currently, I am working as a software consultant in New Jersey, USA.
Blog Address: shujaatsiddiqi.blogspot.com

