

Optimising Server-Side Paging - Part II
Introduction
In part I of this series, we looked at an optimisation that is useful when paging through a wide data set.
This part examines four methods commonly employed to return the total number of rows available, at the same time as returning the single page of rows needed for display.
Each tested method works correctly; the focus of this article is to identify the performance characteristics of each method, and explore the reasons for those differences.
Sample Data
This part uses a single table containing one million rows of meteorological data collected at an imaginary weather station.
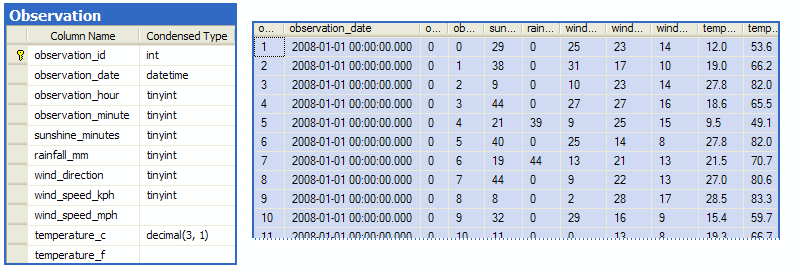
The code to create a test database, load the sample data, and run the full test suite is included in the Resources section at the end of this article.
Tested Methods
The Count Over Method
The first tested method uses the OVER clause extension to the COUNT aggregate. The syntax needed to count all the rows in the query (not just those on the requested page) is very simple:
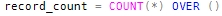
The Double Row Number Method
The second method uses two ROW_NUMBER functions to determine the total number of rows, using a technique described in this SQL Server Central article by Robert Cary.
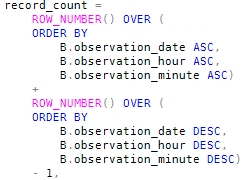
The basic idea is to number the rows in the whole set twice: once in ascending order, and once in descending order. It turns out that the sum of these two numbers (in every row) equals the count of rows in the whole set, plus one. This neat trick can be accomplished with the following code:
The Sub-query Method
The third idea is to use a simple COUNT sub-query, which duplicates the conditions in the main paging query.

The Indexed View Method
The last of the four methods uses an indexed view that contains an aggregated record count per day. The total record count is calculated by summing daily record count subtotals.
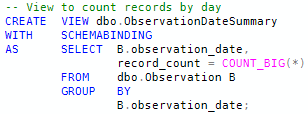

Using the view to compute the record count:

Test Results
Each test uses the same basic paging mechanism described in part I of this series, with a small section of code added to count the overall total number of rows. The test query includes all one million test rows in the paged data set.
The tests were run on a single-core machine running SQL Server 2008 Developer Edition, version 10.0.2766. The code has also been tested on SQL Server Developer Edition, version 9.0.4285.
All system caches were cleared before each test run, and the SQL Server read-ahead mechanism was disabled.
Each test use the same million-row data set, using 25 rows per page. Three tests were run using each method, to return data from the first, last, and middle pages of the set.
The data concerning physical reads, logical reads, CPU time, and elapsed time were obtained from the sys.dm_exec_query_stats dynamic management view, and validated against Profiler output. Buffer pool usage was determined from sys.dm_os_buffer_descriptors. Memory grants were obtained from actual execution plans generated on separate runs.
For each performance category in the summary tables below, the best results are shown in green, and the worst in orange.
First page

Middle page

Last page

Analysis
Count Over
This method performs a very large number of logical reads, and requires a memory grant of almost 46MB for sorting. A look at the relevant part of the execution plan for this method reveals the causes:
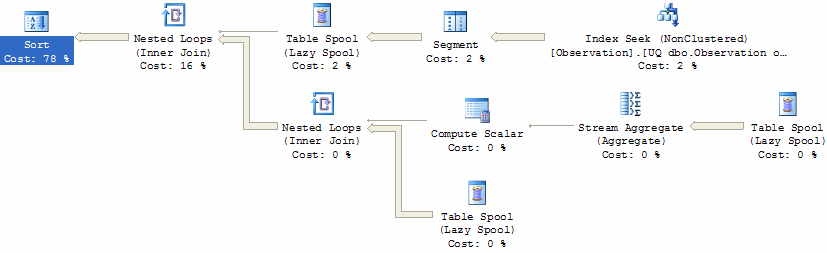
COUNT(*) OVER() is implemented using a special kind of sub-expression spool, known as a Segment Spool. The idea is to break the input up into groups (the Segment iterator), write each group to a worktable (the Spool), count the rows using a Stream Aggregate, and then join the count back onto the original rows as a new column.
The high number of logical reads incurred by this method is caused by the joins and by replaying the spooled rows twice: once to compute the row count, and then again to join the count back onto each row. The logical writes are caused by writing the rows to the spool.
The large memory grant is requested by the highlighted Sort operator. In current versions of SQL Server, the optimiser introduces this sort to guarantee the order of rows presented to a TOP operator later in the plan (not shown for space reasons). The required sort order is the same as that provided by the initial Index Seek - perhaps future optimisers will be able to take advantage of that and avoid this expensive sort altogether.
The million-row sort also contributes to the high CPU utilisation of this method.
Double Row Number
This method is the slowest overall, with high CPU usage, a large memory grant, and the largest number of physical reads.
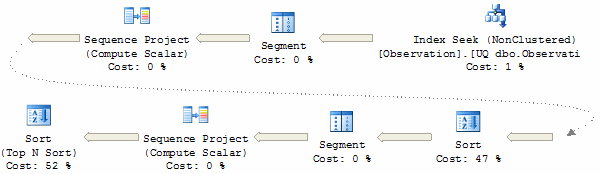
Although the initial Index Seek provides rows in the correct order for the first row numbering operation, an explicit sort is required for the second.
Another explicit sort (the Top N Sort) is required to select the keys for the single page requested. Ironically, this sort puts the rows back in the original order provided by the Index Seek.
The two sorts both have to process one million rows, though the memory granted for the first sort can be reused by the second.
Sub-Query
The sub-query method produces a nice simple plan, and performs very well:

The top row of the plan performs the count sub-query. Since the query is guaranteed to produce a single row, it can be joined directly to the Index Seek that provides the keys for the page of data to return.
The lower Index Seek provides page keys in sorted order, so for page one, it only needs to return the first 25 keys. The biggest cost in this plan is counting the million rows in the Stream Aggregate.
Indexed View
This is the best-performing solution overall:
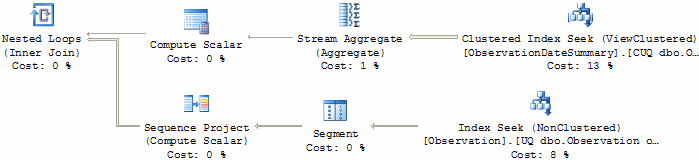
This plan is very similar to that produced by the sub-query method, but instead of counting one million rows, the top row of the plan is able to sum the partial counts stored in the indexed view - so only 695 rows flow through the Stream Aggregate (rather than one million).
This dramatic reduction in row count pays dividends across all the performance categories. In particular, it reduces the number of data and index pages which must be read in to the data cache from disk.
Conclusion
The count over and double row number methods are not really suited to large data sets, due to the cost of the sorts and spools.
The sub-query method is much more efficient, and is limited only by the costs associated with counting the qualifying rows.
The indexed view method improves further on the sub-query method, by maintaining useful partial aggregates. This is similar to the idea of keeping counts in a separate table using a system of triggers.
