

Introduction
It is common to need to access rows from a table or result set one page at a time, perhaps for display purposes.This short series of articles explores a number of optimisations that can be applied to the basic technique of using the ROW_NUMBER ranking function to identify the rows to return for a requested page.
This series does not include an introduction to the core method, since there are a number of good articles already on SQL Server Central which do this. An excellent explanation can be found in this article by regular columnist Jacob Sebastian.
This first article takes a close look at an optimisation that is useful when paging through a wide data set. The next parts in the series will cover optimisations for returning the total number of pages available, and implementing custom ordering.
For layout reasons, the code samples in this article are rendered as images. A full test script with additional annotations can be found in the Resources section at the end of this article.
Paging through a wide data set
A wide data set is one which has a large average row size. Paging through a set like this presents some special challenges. To illustrate, this article uses a table that might form part of a design for an on-line discussion forum (like the ones here on this site).
The rows of the example table are potentially quite wide, since the body text of a posted message can use up to 2500 Unicode characters.
Sample Data
The following code creates the test table and populates it with 10,000 random rows.
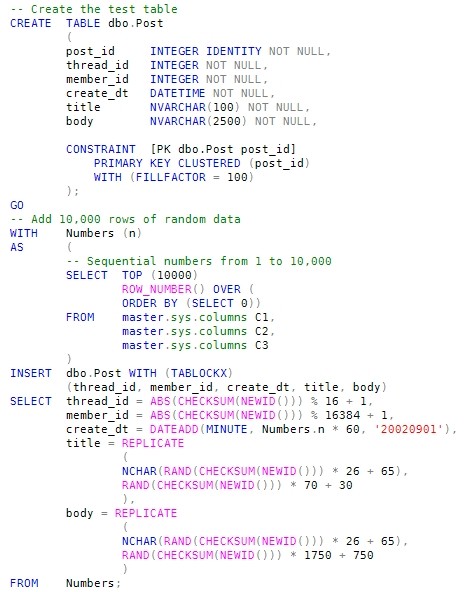
The task is to return data from this table as a paged data set. The client will supply the page number required, and the number of rows per page.
Initial solution
One solution to this problem uses a common table expression (CTE) to number the rows, and an expression in the WHERE clause to return just the rows that correspond to the single page of data required. A TOP expression is used to allow SQL Server to stop looking through the table as soon as it has found the rows needed.
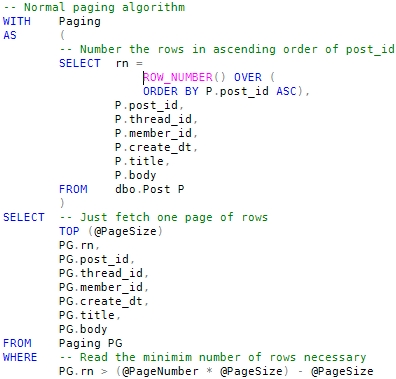
Running the above code on our test data produces an execution plan like this:

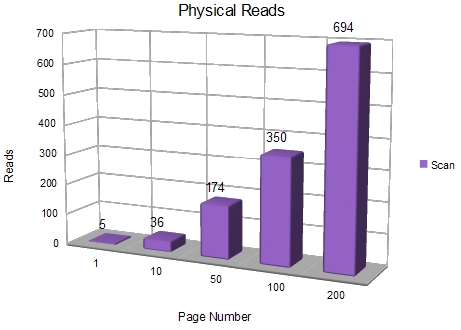
This is a simple and efficient-looking plan, but scanning the clustered index of a wide table can quickly become expensive. The following graph shows the number of physical reads incurred using this method, when reading a specified page number from our test table, with 50 rows per page.
Why scanning the clustered index can be inefficient
The cost of scanning the clustered index rises quickly due to the high average size of the data rows. This might seem counter-intuitive, since the clustered index key is very narrow - just 4 bytes for the integer post_id column.
While that is certainly true, the key just defines the logical order of data pages - the leaf level of the clustered index contains the entire data row, by definition. When SQL Server scans a clustered index in an ordered fashion, it follows a linked list of page ids. Since the linked list is found at the leaf level, entires are separated by the full width of the data row. This makes the clustered index the least-dense index possible.
Alternative Methods
Using a non-clustered index
One alternative to scanning the clustered index, is to create a covering non-clustered index. In this case, however, a covering index is not practical since it would essentially duplicate the clustered index.
We might instead consider creating a non-clustered index just on the post_id column, with a plan to use that index to quickly find the page required, and then look up the rest of the row data. The index is created using this statement:
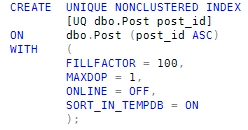
This new index is very narrow (just 4 bytes per row at the leaf, plus index overhead), which ought to make finding the requested page very much more efficient. Sadly, running the query again with a forced index produces the following execution plan:

This plan is very similar to that generated for the clustered index, except now the query performs a bookmark lookup for every row, in order to fetch the columns not included in the index. This plan is less efficient than scanning the clustered index, so it seems that this is a step backward.
The problem is that SQL Server is fetching the off-index columns for every row it examines - not just the rows that will be eventually returned. The Key Lookup operator fetches the extra columns before the Sequence Project operator assigns a row number, and before the Filter has a chance to restrict the rows based on the assigned row number.
A much better execution plan would scan the non-clustered index, assign row numbers, filter the records, and only then use a Key Lookup to fetch the off-index columns. Since we know we will only be returning a maximum of 50 rows, it seems likely that the cost of 50 lookups would be more than offset by scanning the much narrower non-clustered index to begin with.
Unfortunately, SQL Server does not yet include logic to spot this sort of optimisation, and always places a Key Lookup just after the Index Seek or Scan it is associated with.
The 'Key Seek' Method
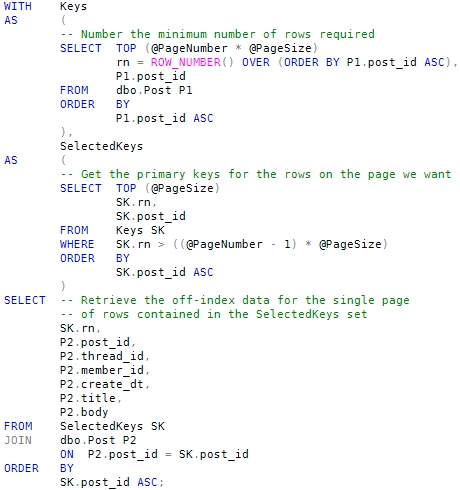
We can work around this limitation by rewriting the query as three logically separate steps:
- Start a partial scan of the non-clustered index in post_id order, assigning row numbers as we go.
- Filter those row numbers down to just the single page of rows we want.
- Use the 50 primary keys from step 2 to look up the off-index columns for the final output.
The following code implements these three steps in a single statement:
The query plan for this implementation is:
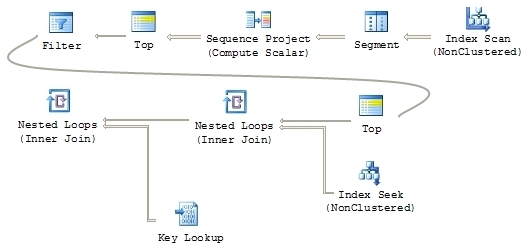
Notice that the Sequence Project and Filter operators now precede the Key Lookup in the plan, meaning that a maximum of 50 lookups will be performed. Because this method performs an index seek on filtered keys, it is referred to as the Key Seek method.
Testing and Results
Test environment
The tests were run on a single-core machine running SQL Server 2008 Developer Edition, version 10.0.2757. The code has also been tested on SQL Server Developer Edition, version 9.0.4285.
System caches, including the buffer pool (data cache) were fully cleared before each run, and the SQL Server read-ahead mechanism was disabled.
Clearing the buffer pool ensures that each data page required comes from disk, and disabling read-ahead ensures repeatable results on different editions of SQL Server. Early testing found that enabling read-ahead tended to disadvantage the clustered index scanning method, since SQL Server frequently read more pages than were ultimately required, resulting in an artificially high number of reads.
The purpose of clearing the cache and disabling read-ahead is to produce clear and consistent test results. Do not run the scripts included in this article on anything other than a personal or dedicated test server.
All tests were run on the same 10,000 row data set, using 50 rows per page, and requesting page numbers 1, 10, 50, 100, and 200 (the last page).
The data concerning physical reads, logical reads, CPU time, and elapsed time were obtained from the sys.dm_exec_query_stats dynamic management view, and validated against Profiler output and from runs with SET STATISTICS IO, TIME ON. Buffer pool usage was determined from sys.dm_os_buffer_descriptors.
The full test script is included in the Resources section at the end of this article.
Physical reads
Although the query plan for the Key Seek method looks a little more complex than the clustered index scan version, it is surprisingly efficient, with consistent performance across the whole range of tested page numbers. The following graph shows the physical reads incurred by the Key Seek method, in comparison to the clustered index scan.
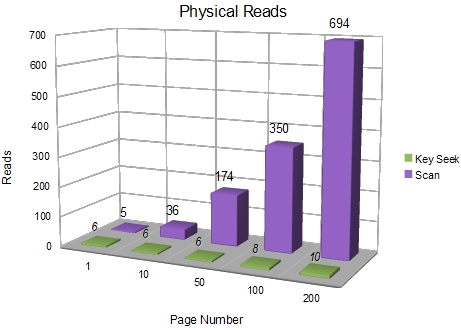
The Key Seek method ranges from 6 to 10 physical reads, whereas the clustered scan method uses between 5 and 694 physical reads.
Confirmation of the small number of data pages needed by the Key Seek method can be found later in this article, in the analysis of Buffer Pool memory usage. That analysis also shows that a each physical read was able to load multiple 8KB data pages.
Logical reads
Logical reads are the sum of read operations on pages already in the data cache, plus any physical reads from external storage. Operations on a cached page are very fast - many thousands of times faster than a physical read - but we must nevertheless account for them. The following graph shows a comparison of logical reads for the two methods:
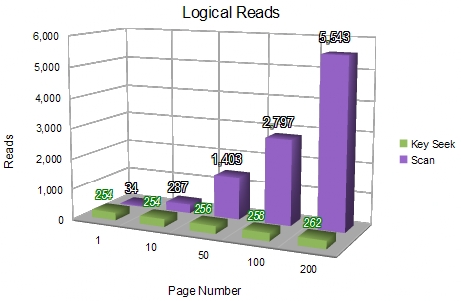
Again, the Key Seek method is very consistent, though it does perform more logical reads than the clustered index scan for the first few pages. Since we already know how many physical reads were required, it is clear that very nearly all of the logical reads are reads from data cache.
CPU and total elapsed time
Total worker time is generally slightly higher for the Key Seek method, due to the extra logical operations performed. As in the other tests, the difference is most pronounced for low numbered pages.
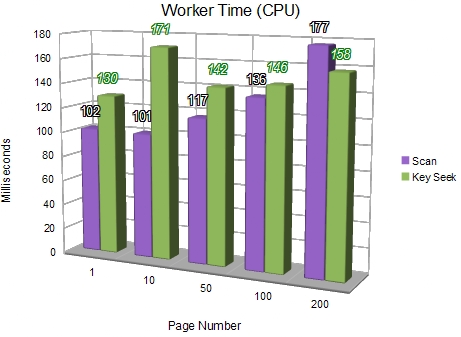
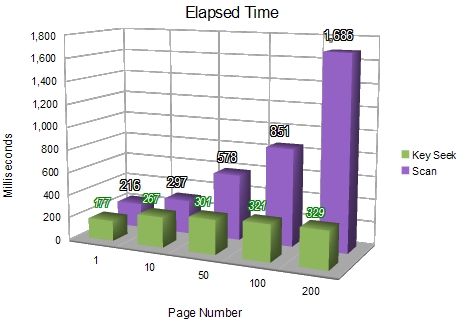
The tests for elapsed time show the Key Seek ahead in all cases - emphasising the dominant contribution of physical I/O.
Memory Usage
This test measures the number of 8KB index and data pages brought into the buffer pool by each method.
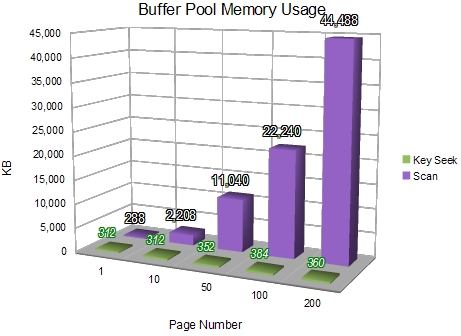
The clustered index scan consumes very slightly less memory only for the very first page. After the first page, the Key Seek method has a smaller buffer pool requirement.
This result confirms the observations from the physical read test, showing that the Key Seek method touches a consistently small number of data pages, and that many data pages can be fetched with a single physical read.
Conclusion
The Key Seek method provides a fast and efficient way to implement server-side paging when the source row data is relatively wide. The method gives predictable and consistent performance regardless of the page number requested, while making efficient use of system resources.
Very high-volume applications that frequently access the first few pages of a result set might consider combining the two methods presented here - using a clustered index seek for the first few pages, and switching to the Key Seek method for all other requests.
A comprehensive test script containing all the code samples from this article, together with additional comments and annotations can be found below.
