

A few months ago my company opened a new call center. One of the issues that we
knew we were going to face was keeping the data for a client current between
two call centers. My boss (Andy Warren) decided to use a combination of queued
updates and merge replication. This was running smoothly until last week. For
some unknown reason all of the publications became invalidated. This meant that
all the subscriptions had to be reinitialized and all the data had to be
re-snapshot. This is no problem for some of our smaller tables but the majority
of the tables had 1 million+ records. The biggest tables had 9 million+ rows in
them. Yikes!!!
Andy and I came up with a plan to get this done and I was almost ready to go. I
say almost because I was a little reluctant to take this on as I’m primarily a
developer with a second title of Junior DBA (kind of the pseudo-DBA if you
will). I'm comfortable with snapshot and transactional replication but merge is
a whole new ballgame; one I didn't understand (like croquet).
A couple of other reasons I was reluctant to take this on was if I screw this
up, not only do I create more work for my already overworked boss, but I
potentially keep 20+ people from working. Luckily I came through and saved the
day. Well not really, but you get the idea. I learned a few lessons along the
way and I’m a better pseudo-DBA for it.
Here is the plan that we came up with:
- Rename the tables on the subscriber to keep as a backup.
- Reinitialize the snapshot (let the publisher re-create the table, etc)
- To make sure the data was consistent after the snapshot I had to:
a) Insert rows from the backup tables that didn’t exist on the snapshotted (is
that a word?) table from the publisher.
b) Update rows on the table that was snapshotted (seriously, I don't think this
is a word) where the data didn't match what was on backup table.
Simple as it looks, I learned the hard way that it wasn’t that easy.
Lesson 1
In reference to transactional / queued updates publications; tables that exist
in the publication and have already been part of a subscription before a
re-initialization, have to be present on the subscriber, otherwise the
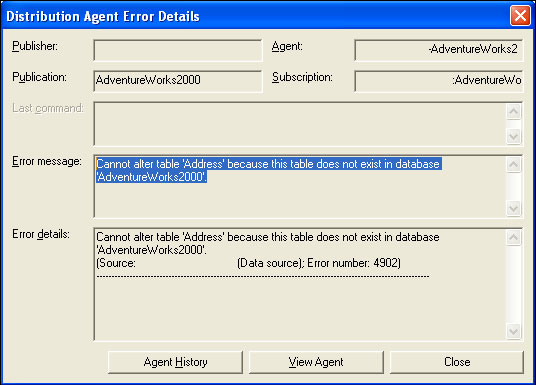
distribution agent fails. (See error message below). This was perplexing as I
thought the publisher would create the table no matter what if the article
setting was "Drop existing table and re-create it."
Lesson 2
Again, in reference to transactional / queued replication; the table
has to be almost an exact copy of what’s on the publisher (not including
indexes) if the table was part of the publication before a re-initialization of
the subscription. To solve lesson 1 I created a table with the same name as the
table on the publisher. The distribution agent failed with the
same message above. I created a shell of the table without the
constraints; the distribution agent failed again!!!! What the hell was going
on? I was really irritated at this point. What finally worked was scripting the
table from the publisher and creating it on the subscriber (constraints and
all). I started the distribution agent again and I
finally saw the bulk copy starting.
Lesson 3
To snapshot a lot of rows requires a lot MORE time if the database is 80 miles
away. This is kind of obvious, but I was a little surprised how long it really
takes. When I ran the snapshot for the 9 million row table overnight I
woke up to a surprise. In 9 hours only 6.7 millions rows went over. I had to
stop the distribution agent, rename the backup table and recreate the
constraints. Fun, Fun, Fun… Out of sync for a few more days. I finally ran the
snapshot on a Saturday and for some reason the data went over much faster. This
allowed me to run the snapshot for the 14 million row table in the next day.
Maybe less network traffic was the difference.
Lesson 4
The distribution agent does not always give you a status update of the bulk
copy. I’m used to seeing the distribution agent give some type of status of the
bulk copy with transactional replication (100000 rows copied, etc). The
merge replication distribution agent does not give any type of status. This
freaked me out for a while. I thought that once again something else went
wrong. Finally, I discovered that if I query the table on the subscriber I
could see the row count.
Lesson 5
You can keep data synced between two tables using queued updates with
transactional replication. I thought the only way to keep data synced up
between two tables was to use merge replication. I found out that using
transactional replication with queued updates can accomplish basically the same
thing. One major difference is queued updates cannot keep text and image
columns synced between the two tables. I found the official explanation on the
msdn site. The Subscriber cannot
update or insert text or image values because they cannot be read
from the inserted or deleted tables inside the trigger. Similarly, the
Subscriber cannot update or insert text or image values using
WRITETEXT or UPDATETEXT because the data is overwritten by the Publisher.
Instead, you could partition the text and image columns into a
separate table and modify the two tables within a transaction. Use merge
replication to synchronize these values. You cannot be assured there are no
conflicts because the update of the text or image table can occur
if the data is not well partitioned.
Lesson 6
Maybe I should read more articles on sqlservercentral.com about replication.
Conclusion
All in all I’m sure everything would have gone much smoother if I read about
what I was doing beforehand, but I had Andy to help me along the way. I was
happy with the solution. Whether you agree that it was the best solution is
another matter, it worked. I hope that by reading this you understand the
struggles that an Until next time...Happy databasing!
