

Introduction
In the first article I discussed how the ROW_NUMBER() function can cut down resources spent on queries dealing with versioning. In this article I will discuss how the ROW_NUMBER() function can help when dealing with range requirements. The code samples are available for download. The name of the file is RowCountScenario2-CodeDownload.sql.
Scenario 2 – Ranges
Another scenario where the ROW_NUMBER() function is extremely useful is in creating ranges. For example, if you have the following table.
CREATE TABLE Dates.CategoryDate
(
Category nchar(1)NOT NULL,
Date datetimeNOT NULL,
CONSTRAINT PK_ProductDate PRIMARY KEY CLUSTERED
(
Category ASC,
Date ASC
)
);
This table is populated with the following data. The dates basically denote the starting date of a new version of the Category. The goal of the ranges is to add an ending date for the older version of the Category based on the newer version’s starting date.
INSERT INTO Dates.CategoryDate
SELECT N'A',CAST('2000-01-01'AS DATETIME)
UNION
SELECT N'A',CAST('2001-12-31'AS DATETIME)
UNION
SELECT N'A',CAST('2002-10-30'AS DATETIME)
UNION
SELECT N'B',CAST('1999-10-20'AS DATETIME)
UNION
SELECT N'B',CAST('2000-01-01'AS DATETIME);
The ranges that you have to create need to look like Figure 1.
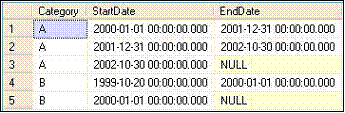
Figure1: Expected results sample
These ranges can be created using the subquery approach and the ROW_NUMBER() approach. The code complexity of the two approaches is similar and the estimated subtree costs are very similar for this small data set. The following code demonstrates the subquery approach to creating the range table.
SELECTd.Category,
d.Date AS StartDate,
( SELECTMIN(d2.Date)
FROM Dates.CategoryDate d2 WITH (NOLOCK)
WHERE d2.Category = d.Category
AND d2.Date > d.Date
) AS EndDate
FROM Dates.CategoryDate d WITH (NOLOCK);
The subquery is required so that only the next smallest date greater than current date is set as the end date. The sub-query in this example is greatly affected by the size of the data set. A large data set will cause this query to perform very, very poorly even with properly implemented primary keys and indexing because of the comparison in the WHERE clause. The ROW_NUMBER() version of the code looks like this:
WITH RangeAnalysis
AS
(
SELECT
ROW_NUMBER()
OVER(PARTITIONBY Category
ORDERBY Category,
Date
)AS RangeID,
Category,
Date
FROM Dates.CategoryDate d WITH (NOLOCK)
)
SELECT ra.Category,
ra.Date AS StartDate,
ra2.Date AS EndDate
FROM RangeAnalysis ra
LEFT OUTER JOIN RangeAnalysis ra2
ON ra.Category = ra2.Category
AND (ra.RangeID + 1) = ra2.RangeID;
The function works similarly here as it did with the Products example earlier. The ORDER BY clause orders all the dates for a Category. The join in the query essentially replaces the date comparison logic found in the subquery approach. The join replaces the logic because the row numbers are assigned by the sort order determined in the function.
I created clustered indexes/primary keys on the sample tables in the previous code samples, but what happens if your data is not properly indexes? This section briefly discusses the cost of creating ranges on non-Indexed columns utilizing the two methods. The following table contains a sample dataset like the one I worked with.
CREATE TABLE Dates.CategoryDate2
(
Category nchar(1)NOT NULL,
Date datetimeNOT NULL
);
There are no indexes on this table. In order to populate this table with data, I will use a recursive CTE to quickly generate a large set of rows. The query to insert a set of rows is shown below:
WITH RCTE (X, Category, Date)
AS
(
SELECT 0 AS X,
CAST(LEFT(NEWID(), 1) AS NCHAR(1)),
CAST(CAST(ABS(CHECKSUM(NEWID()))ASINT) % 2958464 AS DATETIME)
UNION ALL
SELECT X+1,
CAST(LEFT(NEWID(), 1) AS NCHAR(1)),
CAST(CAST(ABS(CHECKSUM(NEWID()))ASINT) % 2958464 AS DATETIME)
FROM RCTE
WHERE X < 99
)
INSERT INTO Dates.CategoryDate2
SELECT DISTINCT TOP (100) Category,
Date
FROM RCTE
OPTION(MAXRECURSION 0);
The WHERE X < 99 clause dictates the number of recursions (rows) that should be generated, in this case 100 rows. The OPTION(MAXRECURSION 0) at the end of the query allows for potentially infinite recursion. The number 2958464 signifies that the random date should be Dec 31st, 9999 or earlier. It should also decrease the number of repeated dates. A distinct is added to the select query to ensure that no duplicates are inserted into the table. The Categories this time around will be the ‘0’ through ‘9’ and ‘A’ through ‘F’, i.e. the hexadecimal digits. The following table shows the estimated subtree costs as the number of rows in Dates.CategoryDate2 increase.
| Row Size | Sub-query Implementation Est. Cost | ROW_NUMBER() Implementation Est. Cost |
| 100 | 0.0270645 | 0.0526454 |
| 1000 | 0.349152 | 0.123938 |
| 10000 | 6.1974 | 2.4727 |
| 100000 | 349.784 | 98.8483 |
| 1000000 | 16903.5 | 3139.5 |
Figure 2: Non-indexed estimated query costs
I ran the queries for 1,000,000 rows. The sub-query method took 1 hour, 51 minutes and 3 seconds while the ROW_NUMBER() implementation took only 30 seconds. Of course your results may differ depending on the hardware you’re using and other factors, but the general idea remains the same. The main assumption taken by the ROW_NUMBER() method is that there are no duplicate dates. In the case there are any duplicates; distinct rows can be pulled through the select query outside the CTE. The query plans for subquery implementation and the ROW_NUMBER() implementation are displayed in Figure 4and Figure 5respectively.
The following chart shows the changes in the query costs for increasing row size in Dates.CategoryDate. The subquery and the ROW_NUMBER() implementation ran in 17 seconds for 1,000,000 records.
| Row Size | Subquery Implementation Cost | ROW_NUMBER() Implementation Cost |
| 100 | 0.022865 | 0.0284582 |
| 1000 | 0.172902 | 0.0701899 |
| 10000 | 1.67063 | 1.24369 |
| 100000 | 16.6029 | 130.21 |
| 1000000 | 165.72 | 5069.75 |
Figure 3: Indexed table estimated query costs
Estimated Query Plans
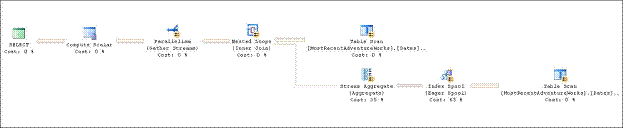
Figure4: Subquery approach

Figure5: ROW_NUMBER() approach
Conclusion
The ROW_NUMBER() function and the subqery approaches in this scenario had relatively similar code complexities. However, the subquery method was extremely dependent on indexing. The size of the data will also play an important role in which implementation is utilized. The ROW_NUMBER() function utilizes the date ordering to its advantage in order to efficiently create the date ranges.