

If you don't have to deal with case sensitivity, count yourself lucky! SQL
2000 is much better than SQL 7 with regard for collations, supporting collations
at database, table, and column level. In this article I'm going to delve into a
interesting (or obvious?) item I noticed recently when I did some performance
tuning.
Basically we were doing a join to a table where we had to treat one column as
case sensitive. The table in question had about 130k rows and had an index (not
unique) on the column we were joining to. Not a huge table, a join to it should
be reasonably fast, yet I saw a high number of reads. Digging into the code -
which I sadly admit to writing - I found that we were handling the issue of case
sensitivity by converting the column to varbinary, a technique that works in
SQL7 or SQL 2000. An example written using a different table and simplified
syntax is shown here:
select * from instantforum_members where convert(varbinary(50), fullname) = 'andy warren'
If you're using SQL2K, you can accomplish the same thing or even better
depending on your needs by using a collation instead, like this:
select * from instantforum_members where fullname='andy warren' collate Latin1_General_CS_AI
Before we go on, let's start with what a simpler non case sensitive query
would look like and do:
select * from instantforum_members where fullname='andy warren'
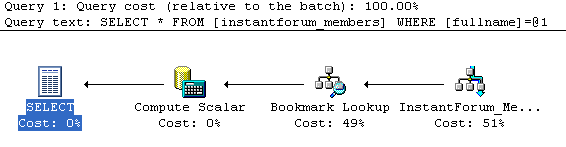
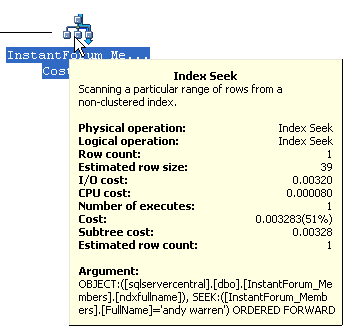
You can see that just doing a simple select for my name results in a plan
that starts with an index seek, which is good, and has a cost of .003283. The
cost is relative, but in practical terms this is a very fast efficient query.
Now let's try the method I was using to handle sensitivity:
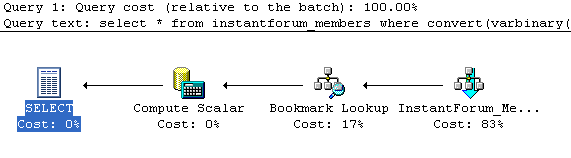
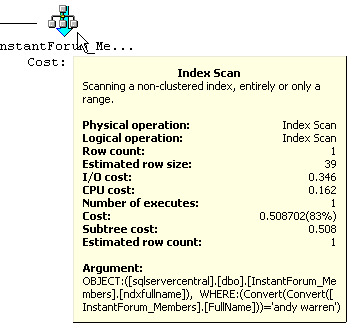
Here you can see the percentages shift as it does an index scan rather than
an index seek, no doubt caused by the convert statement which requires it to
touch every row. What's far more interesting is that the query cost jumps to
.508702, a huge jump! I ran the statement that used collate, not really
expecting a difference but you have to try, resulting in the exact same query
plan. That seems to make sense, it has to do the same work. Being curious, I
tried one more query specifying the collation as case insensitive and wound up
with the same results. Double checking the database found that I wasn't
specifying the correct & current collation which was
SQL_Latin1_General_CP1_CI_AS. Running one more time resulted in the same results
that I got in the first query with no collation specified.
Sorry if that is confusing. The net is that if you specify any collation
except the one in use on that column or you use a convert you're going to force
SQL to check each row, most likely resulting in either an index scan or a table
scan.
That got me thinking about how I could improve the performance without
changing the collation (an article for another day!). My thought process was
that the query itself was quick, the case sensitive compare slow only because it
had to look at every row, how to limit the query first and then do the compare.
For once it turned out to be exactly that easy, resulting in the following:
select * from instantforum_members where fullname = 'andy warren' and convert(varbinary(50), fullname) = 'andy warren'
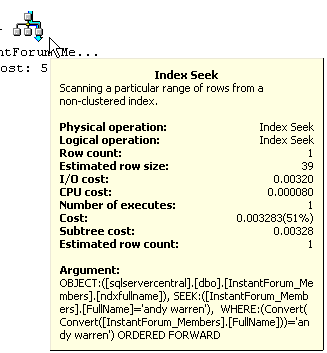
Just that simple change gave me the results I needed at basically zero cost.
I've only tested on two tables so I can't say with certainty that the results I
show here are always true, but so far it seems to be consistent. It also shows
how even the simplest change can have an impact on query efficiency. In a follow
up article I'll look into others options including making the column case
sensitive.
