

In a perfect world we wouldn't need disaster recovery and standby servers for SQL Servers. Hardware would never fail, data would never be corrupted, and disaster recovery would never be required. In a partially perfect world, companies could afford expensive clustered SQL Servers that automatically failed over their production SQL Servers. Unfortunately, there is no perfect world and often, a DBA needs to implement a home grown solution to create a synchronized copy of production database(s).
There are many different purposes for this exercise. Some of them include implementing a disaster recovery mechanism and keeping warm standby servers with set of databases, transferring data for the reporting and BI needs, or verifying the validity of the production data and backups. Microsoft log shipping in SQL Server 2005 and 2008 can be used for such tasks.
This article will demonstrate how to implement a custom log shipping solution and how it can be augmented to implement the ability to automatically recover from failures the next time it runs.
The architecture is simple enough. SQL Server is going to run a transaction log backup job and dump the files to a specified location on the source server. A stored procedure will copy the file(s) to the target server over a network. Then the files will be restored on the target server. Each step of the process will be managed by a control mechanism.
Let’s go step by step over the process and process’ components. Many pieces of the process can be implemented many different ways but the general idea is going to be the same. I will try to focus on the mechanism’s architecture, especially on the control part which allows self recovery in case of a failure and I will present one of the many implementations. I think that most DBAs use SQL Server maintenance plans for the database’s log backup. The system table backupset contains a row for each backup, and it is stored in the msdb database. The table has many columns but we need to focus only on few of them.
Column name | Data type | Description |
backup_set_id | int | Unique backup set identification number that identifies the backup set. Identity, primary key. |
backup_set_uuid | uniqueidentifier | Unique backup set identification number that identifies the backup set. |
name | nvarchar(128) | Name of the backup set. Can be NULL. |
type | char(1) | Backup type. Can be: D = Database I = Database Differential L = Log F = File or Filegroup G = File Differential P = Partial Q = Partial Differential Can be NULL. |
database_name | nvarchar(128) | Name of the database involved in the backup operation. Can be NULL. |
server_name | nvarchar(128) | Name of the server running the SQL Server backup operation. Can be NULL. |
Backup_finish_date
| Datetime
| Date and time the backup operation finished. |
The first step in our process is to save the log files backup data. The table LS_backupset is created for this purpose.
CREATE TABLE ls_backupset
( Backup_set_id int not null,
Server_name nvarchar(128) not null,
Backup_set_uuid uniqueidentifier not null,
Name nvarchar(128) not null,
Type char(1) not null,
Database_name nvarchar(128) not null,
Backup_finish_date datetime not null);
This table has a primary key that consists of 2 columns: backup_set_id and server_name. This is done in case the standby server has multiple databases from the multiple servers. When backup_set_id comes from multiple servers it may have the same value, but the combination of backup_set_id and server_name is unique. To get data into this control table, the log backup maintenance plan has to be extended by adding a SQL Task step to insert all additional log backup rows to the ls_backupset when the log backup is done.
Declare @set_id int;
Set @set_id = 0;
Select @set_id = max(backup_set_id)
from ls_backupset;
Insert into ls_backupset
( Backup_set_id,
Server_name ,
Backup_set_uuid ,
Name ,
Type ,
Database_name ,
Backup_finish_date)
Select Backup_set_id ,
Server_name,
Backup_set_uuid ,
Name ,
Type ,
Database_name ,
Backup_finish_date
From msdb.dbo.backupset
Where backup_set_id > @set_id;
The second control table keeps metadata information about the source, the destination server names, the log file locations, and the standby path for the logs to be restored.
CREATE TABLE [dbo].[BackupDBInfo]( [BackupDBInfo_ID] [int] IDENTITY(1,1) NOT NULL primary key, [Source_SRVR_Name] Nvarchar(128) NOT NULL, [Dest_SRVR_Name] Nvarchar(128) NOT NULL, [DBSE_Name] [int] NOT NULL, [BackupType] [char](1) NOT NULL, [Source_File_Path] [varchar](255) NOT NULL, [Source_File_Ext] [varchar](5) NOT NULL, [Dest_File_Path] [varchar](255) NOT NULL, [Dest_StandBy_Path] [varchar](255) NULL, [Status] [char](1) NOT NULL, [StartRestoreFrom_DT] [datetime] NULL)
The column Status turns each metadata row on or off. StartRestoreFrom_DT is the column that specifies the initial datetime and makes sure that the process ignores all log files created prior to this date. Usually I set the value of the column with date and time of the full backup file that is used to initialize the standby server. This table should have one row per each database and is going to be created on the source and on the destination server. The source server will use it to define the location of log files and where files have to be copyed. The destination server will use it to define the location of the database log files for the process of log files restore.
CREATE TABLE [dbo].[CopySetHistory]( [CopySetHistory_ID] [int] IDENTITY(1,1) NOT NULL primary key, [backup_set_id] [int] NOT NULL, [server_name] [nvarchar](128) NOT NULL, [Database_NM] [varchar](30) NOT NULL, [Status] [char](1) NOT NULL, [File_NM] [varchar](255) NOT NULL, [CopyFile_FromPath] [varchar](255) NOT NULL, [CopyFile_ToPath] [varchar](255) NOT NULL, [BackupDBInfo_ID] [int] NOT NULL, [Dest_SRVR_ID] [int] NOT NULL, Createdate datetime default (getdate()) )
The table CopySetHistory is created on the source server site and keeps the set of copied files moved from the source to the destination. The status will let us know about success or failure of the file(s) copy. Column Createdate stores the information about date and time when log file was copied. This table allows us to check the history of copied files, get the information about unsuccessfully processed files and recopy it to the destination server. The last control table controls data about restored log files.
CREATE TABLE [dbo].[BackupSetHistory]( [BackupSetHistory_ID] [int] IDENTITY(1,1) NOT NULL primary key, [backup_set_id] [int] NOT NULL, [server_name] [nvarchar](128) NOT NULL, [Restore_Database_name] [nvarchar](128) NOT NULL, [Restore_Status] [char](1) NOT NULL, [Restore_File_NM] [varchar](128) NOT NULL, [Restore_File_Path] [varchar](128) NOT NULL, [BackupDBInfo_ID] [int] NOT NULL, [CreateDate] [datetime] NOT NULL DEFAULT (getdate()) );
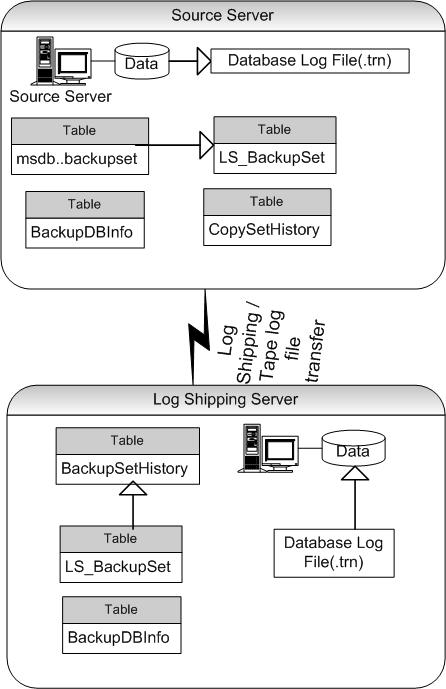
The image below shows the log shipping and control mechanism tables. Log files on source server can be copied to the destination server by the process or even delivered by backup tape if the source and the destination servers cannot talk to each other. Usually, I have one centralized database per server that keeps control tables and generic stored procedures for all back end processes.
Let's assume that the database name is test. To restore the database for the log shipping on the destination server:
RESTORE DATABASE test FROM DISK = '\\servernm\sharenm\<backupfilenm>' with MOVE 'test_SYS' TO 'd:\mssqldb\data\test_SYS.MDF', MOVE 'test_LOG' TO 'd:\mssqldb\LOG\test_LOG.LDF', STANDBY = 'd:\StandbyDir\test.LDF', replace, stats;
To apply transaction log file to the database following command has to be issued:
RESTORE LOG test FROM disk = '\\servernm\sharenm\testlogfile.trn' WITH STANDBY = 'd:\StandbyDir\test.LDF';
To be able restore the log files all connections to the database have to be killed. The code below is one example of how it can be
implemented.
declare @tmpkill table (cmd varchar(255), tid int identity(1,1));
declare @cnt int, @cmd varchar(4000), @minid smallint, @maxid smallint;
declare @db_nm;
set @db_nm = 'test'
insert into @tmpkill(cmd)
select 'kill ' + cast(sp.spid as varchar) from master..sysprocesses sp
inner join master..sysdatabases sd on sp.dbid = sd.dbid
where sd.name = @db_nm and sp.spid @@SPID;
select @minid = min(tid), @maxid = max(tid)
from @tmpkill;
while (@minid <= @maxid)
begin
select @cmd = cmd
from @tmpkill
where tid = @minid;
exec (@cmd);
set @minid = @minid + 1;
end;
Every part of the code for the process presented in this article can be wrapped into a stored procedure and used with a set of parameters. Later on, the set of procedures can be used inside of a general wrapper to restore log files one by one for the multiple databases.
To keep log shipping near real time, I created two additional jobs. The first job is on the source server and will be started by the alert from a trigger on the table ls_backupset. This job has several steps such as copying database log files to the destination server based on the information from ls_backupset and CopySetHistory tables. When each log file is copied, the record of success or failure becomes inserted to the history table CopySetHistory. To define the log backup file’s name the last two characters have to be taken out from the file’s name in table msdb.. backupset. This is how Microsoft writes it in the name field. It can be done while inserting the records to the table ls_backupset and at the same time extension trn can be added at the end of the file’s name.
Then, this job starts a second job which is located on the destination server. It can be done many different ways. For example, one way is through the linked server option between source and destination servers. The destination server job is going to insert all new records from the source control tables: ls_backupset and CopySetHistory.
To restore log files,all database connections must be killed first. I developed 3 stored procedures. The first one is restoring one log file based on the next submitted parameters – database name, log file path and name, standby file path and name. The second one is the wrapper for one database that allows us to restore multiple log files for this database in a loop. The third one is the wrapper which allows us to restore log files for multiple databases on the same server. Remember that table BackupDBInfo has all the necessary information for each database and this allows us to construct a copy and restore statements with dynamically built code inside the stored procedures. Also, it permits us to make the procedures generic.
For example, procedure to restore one log file can be done as follows:
Create procedure [dbo].[RestoreOneLogFile]
@standby_path varchar(128), -- file name the same as db name
@File_NM VARCHAR(255), -- including path
@dbnm VARCHAR(50)
as
begin
SET NOCOUNT ON;
declare @cmd varchar(4000);
BEGIN TRY
set @cmd = ' RESTORE LOG ' + @dbnm + ' FROM DISK = ''' + @file_nm + '''
WITH Standby = ''' + @standby_path + '\' + @dbnm + '.ldf' + ''' ';
-- kill all database connections before restoring log file
exec dbo.spKILL_DB_CONNECTIONS
@db_nm = @dbnm;
exec (@cmd);
END TRY
BEGIN CATCH
raiserror ('Error in proc to restore', 16, 1);
END CATCH
SET NOCOUNT OFF;
return 0;
end;
The copy record in the table BackupSetHistory will be set inside of wrapper for this stored procedure because the wrapper has all additional information and can analyze the output of the log restore.
Insert into [dbo].[BackupSetHistory](
[backup_set_id] ,
[server_name] ,
[Restore_Database_name],
[Restore_Status] ,
[Restore_File_NM] ,
[Restore_File_Path],
[BackupDBInfo_ID])
Select
@backup_set_id ,
@server_name ,
@dbnm,
@Restore_Status , -- (S)uccess or (F)ailure
@File_NM ,
@Restore_File_Path,
@BackupDBInfo_ID;
In all my stored procedures I am setting a lot of validations to be able to better control the process. For example, before I copy a specific file, I am checking the existence of the file in the specified directory by executing Microsoft extended procedure master.dbo.xp_fileexist or I am checking database presence on the source and/or destination server. Now, lets see how the control mechanism helps me make the process more robust.
Let's say that we have 3 databases and 2 log files that are copied on the destination server while the copy of the third file fails because of a network issue. It will be written in control table CopySetHistory with a failed status. The next time when log files are backed up and the process will define which files to copy, the failed file will be included again and delivered to the destination server. On the destination server the process will try to restore only the log files that are copied successfully. E.g. if the file is copied later it will be restored with the next restore iteration.
What happens if restore process failed for one or many files? For example, file was locked by the other process. The restore will insert a record in the control table BackupSetHistory on the destination server with Restore_Status = ‘N’ and the next time the process will start restoring from this file. This is what makes the process very robust. In our company we have had this type of control mechanism in place for hot standby server for more than a year. Sometimes there is a failure to copy or restore log files due to the network or other issues. And during the next run, the log backup process picks up from the place where it stopped previously and recovers itself automatically.
Conclusion
This article demonstrates how the "log shipping process" can be augmented to give it the ability to automatically recover from failures next time it runs.
It is important to note that very similar approach can be used for many other back end processes.
