

Clustering a SQL Server machine was one of the most frustrating tasks a DBA and Windows administrator had to accomplish in SQL Server 7.0 and Windows NT 4.0. With the maturity of both the OS and the DBMS in Windows 2000 and SQL Server 2000, this operation has been simplified tremendously. In the next two articles, I hope to show you the fundamentals of how SQL Server and Windows clusters and then how to actually accomplish this task.
In SQL Server 7.0, performing the task of clustering was daunting. If you knew how to cluster a machine and keep it stable, you were a hot commodity and had better job security than the CEO of the company. I’m afraid that the job security has lessened with Windows 2000 and SQL Server 2000. When I train others how to cluster a Windows 2000 machine, the first thing I hear is, “That was it?”. Thanks to the wizards at Microsoft, I just watched the wows of my peers become the terrifying sentence “That was it?”.
Before we can dive too much into clustering a SQL Server, we must cover the basic terminology. When I was first introduced to clustering a Windows machine, the terminology sent my head into a tailspin because it was so foreign to me. Let me see if I can do a little better. Clustering allows you to have a set of servers that all share a set of drives. If one server fails, its defined resources like SQL Server move to one of the other servers. The entire process usually takes under a minute in a properly configured cluster. It’s not unheard of in some cases for a SQL Server to take 5 minutes to transfer its resources from one server to another.
The most misunderstood area of Windows clustering is that it does not help performance. Clustering is not a way to scale-out or distribute traffic. Instead, if one server fails, its defined services and shared data move to the other server in the cluster. If you wish to scale-out traffic, you must use distributed partitioned views. The main software that controls clustering in Windows 2000 or NT is Microsoft Cluster Service (MSCS). You must have at least Windows 2000 Advanced Server to cluster. Windows 2000 Data Center offers much more better failover protection but at a hefty price tag. You can purchase third-party software and equipment to cluster but many third-party vendors are pulling out of the market because MSCS has become increasingly reliable. For example, a Compaq clustering solution called RSO recently was discontinued and their salespeople are now pushing MSCS.
Each server that participates in clustering is referred to as a node. Windows 2000 Advanced Server supports two-node clusters and Windows 2000 Data Center Supports up to 4 nodes in the cluster. A tool called Cluster Administrator manages the Windows clustered resources including SQL Server. Inside Cluster Administrator, you can specify which server is the preferred owner of a resource (like SQL Server), and you can define who are the possible owners. This means that when you have the possibility of having 4-node clusters, you can specify that one service failover to a particular node. You can also set which server is dependent on another server. By setting a dependent service, you can make sure that SQL Server does not start until the drives are ready.
Here’s the important piece. There are two types of failover clustering in Windows: Active/Passive and Active/Active. Active/Passive means that your cluster has an active node and a passive mode. If your active node failed, then its defined resources would shift to the passive node and it would become active. The passive node is not accessible unless an accident occurs and the resources shifted. Active/Active clustering takes the previous example and twists it slightly. In Active/Active clustering, both nodes are accessible and active. If a node fails, then its resources would shift to the other active node. The node that survives would then carry the load for both nodes. Keep this point in mind when you’re purchasing your equipment. You will need to ensure that in an Active/Active environment that both nodes could sustain the traffic generated for both nodes by themselves.
Tip: I prefer to use Active/Active clustering because in Active/Passive you have hardware that essentially goes unused until a problem arises. In Active/Active, you ensure that all of your expensive hardware is at full utilization.
You cannot cluster your base server equipment by default. You must also purchase a shared drive array that both servers can see. The most common device to use is a shared SCSI array device but I typically use a storage area network (SAN) device. If you do use a SAN, you must also purchase card to connect to the SAN. Make sure when you purchase connectivity equipment like network cards and SAN fiber optic cards, that you buy two of everything for each server so there’s not a single point of failure. In my SAN environment, we purchased multiple Emulex fiber optic cards to connect to the SAN and specified certain hard drives to go out of each card. That way, you not only give yourself added performance, but you also create another level of fault tolerance.
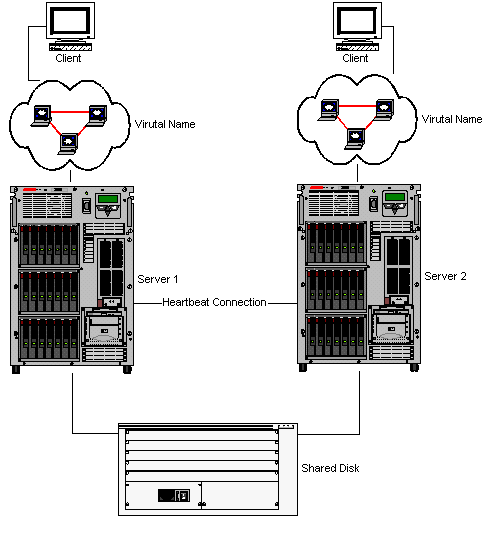
The more typical environment is shown in the below graphic.
You would normally have a shared SCSI disk that both servers can have access to.
You would have a public network that clients would connect to your server with,
while a private network would be used to check the health of the network through
a heartbeat. This "heartbeat connection" can share the public network
connection as well. Applications would connect to SQL Server using a virtual
server name, which can float to any server that owns the server’s resources.
There is also a cluster name, which can also float based on who owns the main
server resources. Performance monitor and all the SQL Server tools are
“cluster aware”.
When you deal with clusters, you will wish you had a
healthy relationship with whoever deals out the IP addresses in your company.
This is because you will need a number of IP addresses to successfully cluster a
SQL Server.
- (2)
Actual server IP addresses (one for each server) used for heartbeat
connection. This can be a private network (for example, 192.168.1.1).
- (1)
Cluster’s IP address
- (up
to 2) SQL Server IP addresses for each virtual SQL Server name. 1 is needed
in Active/Passive. 2 are needed in Active/Active.
There’s also a licensing issue to keep in mind when
doing clustering. In SQL Server 7.0, you had to license each node, even if the
node was passive and inaccessible. In SQL Server 2000, this has been corrected
and you must only license your active node. In an Active/Active environment, you
must license both nodes still since both nodes are accessible.
Clustering SQL Server in Active/Active
In an Active/Active 2-node cluster setup, an
application would connect to the virtual SQL Server name, which is not
necessarily the server’s name. For example, the name could be VIRTUALNAME and
the server could be called SERVER1. The virtual name has an IP address
associated with it and can “float” between the two nodes based on who owns
the SQL Server resources at any given time. In SQL Server 2000, the first node
is considered the default instance. In next week’s article on the installation
of the cluster, I’ll show you how to install this type of topology
step-by-step. There is not an option in a wizard to make your cluster
Active/Active. Instead, it’s in the method you configure the cluster.
The second node must use a named instance to install SQL
Server. In other words, the client may connect to the SQL Server with the name
VIRTUALNAME2\INSTANCENAME. Notice that the virtual server name for the second
SQL Server is not the same as the first node. The catch with using an instance
name is that DBLIBRARY and earlier versions of MDAC (2.5 and below) cannot
communicate to a named instance easily. So, you will have two choices, either
upgrade all your web servers or applications to MDAC 2.6 or later or use a SQL
Server alias in Client Network Utilities to work around the problem.
Each node has drives that it primarily owns. I always
give my drives a volume name where I can recognize who is the primary owner of
the drive. For example, I commonly label a drive PrimaryDBNode1. There is also a
drive that is shared called the quorum drive. This drive is used to write logs
to. If one node fails, the other node will take control of the quorum drive and
read the logs to see where the node left off. MSDTC also uses this drive to
write logs to. You will want to make sure this drive is about a gigabyte in
size. In actuality, Windows will use much less space of this drive. Only one
node can own the quorum drive at a time.
In an Active/Active cluster, you will need to set
aside a number of data drives for each node. For example, I typically create
three shared drives for each SQL Server in my cluster. I have 2 data drives and
1 log drive for each node. The SQL Server files are installed on the local
drives with Windows.
When installing SQL Server into an Active/Active
cluster, you will install the software twice. The SQL Server service will
actually be set to startup manual and will be started by the cluster. When you
look at the services on each node, you will notice that the SQL Server service
is installed on both nodes but is only started on the node that owns the SQL
Server resource.
Installing the SQL Server Cluster
Installing a SQL Server and Windows cluster has never
been easier. Windows and SQL Server both have wizards to practically
self-configure the cluster. The problem is after you install the cluster, there
is still much configuration to do. A bonus in SQL Server 2000 is that the SQL
Server installation and yes, even the service packs are cluster-aware. Analysis
Services (previously called OLAP Services) is not supported in a cluster however
I have clustered it successfully. In a future article, we will cover this topic.
Next week, we’ll cover setting up the cluster step-by-step in a Windows 2000
environment with SQL Server. I’ll also show you how to configure the resources
for peak performance.
If you’d like to ask a SQL Server enterprise-level
question, please post it in our In
