

Introduction
Just like a cold-war underground bunker(1), the Disaster/Recovery (D/R) implementation of a database-server environment is insurance against the unthinkable: you hope you will never need to use it, but if you do, it had better be ready to serve its purpose and provide shelter for as long as necessary. We live in a world, where natural disasters, accidents and malicious intent can cause untold damage to the data centres of organizations, no matter how thorough the measures taken to counteract such crises. For this reason, prudence dictates a "plan B": a secondary (D/R) site, geographically separated from the location of the primary production environment and configured to closely match production settings, so that one day, if need be, it can be turned into production quickly and reliably.
In this article I describe the implementation of an extensible framework designed for monitoring configurational differences between production and D/R SQL-Server database-engine instances. This framework (let us call it DRsync framework from here on) consists of a set of configurational categories, such as jobs, logins and linked servers. Each configurational category is a container of individual attributes; for example, the "jobs" category contains the job name, description and whether or not a job is enabled. These settings are stored in a special database placed in each SQL instance and compared in each production-D/R instance pair. The results of the comparison are stored in the D/R instance of the pair and a report of these differences is generated for subsequent analysis by the DBA.
Why is there a need for such an implementation? After all, there are already several well-established technologies in SQL Server for maintaining secondary environments synchronized with production: replication, log-shipping and database mirroring propagate database-level settings (2,3), while GeoCluster (4) is a server-level solution offering the capability of geographically dispersed clusters. The problem is that all these technologies suffer from important limitations. GeoCluster protects the entire server against failure, but its cost is currently prohibitive for most organizations. Replication, log-shipping and database mirroring, on the other hand, are more cost-effective but also more restrictive in scope: they handle settings at the database (not server) level, and only for databases configured with the Full recovery model. System databases and other databases not using the full recovery model are not covered. That leaves components, such as sp_configure settings, logins, jobs, linked servers, trace flags and server-level roles/permissions in need of a separate treatment.
Conceivably, many of these "server" settings could be recovered in the event of a disaster from backups of the master and msdb databases. Other features, however, such as external files used by a database application or Windows permissions of SQL accounts on the local server and on network shares, are not recoverable that way. If the D/R environment doubles as a secondary reporting site with its own pre-existing custom settings, overwriting these settings with system-database restores from production may not be tenable. Some of the reporting may be critical to the business and still off-loaded to a secondary site to reduce strain on the production servers. In such situations it may be preferable to have a D/R environment in which D/R-specific and production settings are somehow made to co-exist. It will then be possible, in a disaster situation, to use this D/R environment as both a production and a reporting site, until the original production site becomes operational again.
At first the task of identifying which settings to target for such an implementation may seem daunting. Those of us involved in past SQL Server migration projects, where the entire database application is being moved to a new server, know that the possibility of "things being missed" during the migration process is almost a certainty. There is usually a phase post-migration where DBAs need to work closely with system administrators, application developers and business analysts to plug the holes and smooth out the kinks left behind. Everyone's expertise (and memory) is put to the test, especially if there is inadequate documentation of the historical progression and rationale of configurational changes and no proper change-management process in place.
This is where the extensibility of the DRsync framework comes into play: its design makes it easy to keep adding/deleting configurational categories as the set of components in need of monitoring changes over time. Inevitably this set of categories will not even be the same for every organization but will depend on a company's policies and procedures. If it is company policy to keep database mail disabled on all production servers, there will be no need to include a category that tracks database-mail settings. If, on the other hand, the PowerShell execution policy on a specific production server is set to a mode other than the default "Restricted", this setting will have to be added to the DRsync framework, and the non-default setting applied to the D/R server. Failure to account for such non-default settings may result in functionality failures on the fateful day when the D/R server needs to be turned into "production". In principle, any deviations from default settings in the SQL Server instance, the local Windows environment and the Windows domain in which the database instance is located will need to be added to the DRsync framework and propagated to the D/R site.
Before getting into the specifics, I should make two clarifications. First, database-level settings are only considered for inclusion in the DRsync framework for system databases and for user databases that are not on the full recovery model. I will assume that all other databases are mirrored, log-shipped or replicated from a production to a D/R environment. Second, what I present here is strictly a reporting solution: configurational differences still need to be reconciled at the D/R site manually by the DBA. Mainly this is because of the additional effort required to develop code that automatically synchronizes changes from production to D/R. Each configurational category requires its own syncing solution, so the effort involved to automate this for all elements is substantial. Partly though, it is also a conscious choice. At any given moment it is important for the DBA to have detailed knowledge of configurational differences between production and D/R and to be able to determine which of these differences are critical to reconcile in the two environments. If the D/R environment is also used as a business-reporting site, any changes to it will need to be considered carefully, and an automated solution developed with these precautions in mind.
The DRsync Framework
Let's start by listing the configurational categories making up the DRsync framework as presented in this article. They are (along with the catalog views used to retrieve the data):
- Database permissions: data derived from joining master-db catalog views sys.database_permissions and sys.database_principals (used only for system databases and user databases not on full recovery);
- Database roles - system databases: custom database roles added to master and msdb databases (master..sys.database_principals);
- Databases: databases that exist in production but not in the D/R environment (master..sys.databases catalog view);
- Database-mail configuration settings: settings stored in msdb..sysmail_configuration;
- SQL Server Agent Jobs: job settings retrieved from combining msdb catalog views sysjobs, syscategories and sysoperators;
- SQL Server Agent Job Schedules: job-schedule settings obtained from msdb catalog views sysjobs, sysjobschedules and sysschedules;
- SQL Server Agent Job Steps: job-step settings obtained from msdb catalog views sysjobs and sysjobsteps;
- SQL Server Agent Operators: retrieved from msdb..sysoperators;
- Linked Servers: from master.sys.servers;
- Server Logins: from master..sys.server_principals;
- Server-Logins' mappings to database roles: retrieved from executing stored procedure sp_helprolemember in the master and msdb databases
- Server-Logins' server-level permissions: obtained from joining master.sys.server_permissions with master.sys.server_principals (an example permission of this type is VIEW SERVER STATE);
- Server-Logins' server roles: master.sys.server_principals joined to sys.server_role_members;
- sp_configure settings: settings obtained from executing the sp_configure stored procedure;
- Trace Flags: retrieved from executing the "DBCC TRACESTATUS(-1)" command;
- SSIS packages: package information (including versioning) deployed on the server and likely invoked for execution by SQL jobs; obtained by querying msdb catalog views sysssispackages and sysssispackagefolders (only feasible for SSIS packages deployed in msdb) (7,8).
All this information is stored in a database named utildb. A version of the utildb database is deployed on all production and D/R SQL Server instances. It is helpful here to think of each production instance as having a single D/R partner and vice versa. In the production environment the utildb database contains data specific to the SQL instance that hosts it. In the D/R environment utildb stores data pertaining to its D/R instance host plus data from the corresponding production partner. There is an important benefit in storing production data in the D/R utildb: should a disaster occur, it will be possible to reconcile any outstanding production-D/R differences on the D/R instance, based on information that is readily available.
For each configurational category there are two database tables. To illustrate, let's take the "Server Logins" category from the above list of categories. If situated in a production SQL instance, the first table - drsync_logins - stores all records of that category in that SQL instance. That would be all server logins found under the Security/Logins node in SQL Server Management Studio (builtin logins, such as "sa", and server roles are not considered). In a D/R instance, on the other hand, drsync_logins stores data from the D/R instance plus its production partner. The second table - drsync_logins_compare - is only populated in the D/R SQL instance; it contains records that are either different (in one or more fields) in the D/R-vs.-production-instance pair or altogether absent in one of the two instances in the pair. Note that it is named just as the first table with "_compare" at the end.
Let's clarify with an example. Suppose a new login, applogin1, has been added to the production instance DI-L-00233\alex. However this login has not yet been added to the D/R instance DI-L-00233\zoe (in real life, it is the server names in a production-D/R instance pair that would be different and the instance names the same, but I had to develop many of the samples for this article on my laptop, so indulge me a little). On the D/R instance, DI-L-00233\zoe, the drsync_logins_compare table will look as in the following figure:
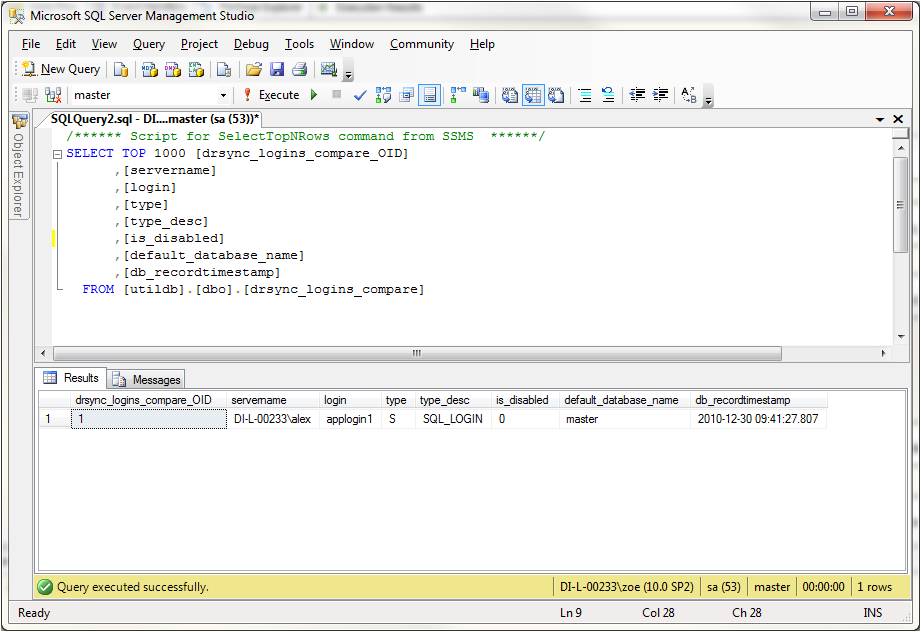
Fig. 1: The drsync_logins_compare table in the D/R instance showing an extra login, applogin1, that exists in production but not in D/R
Locating extra logins that way and writing the T-SQL code to extract these records for reporting is relatively straightforward. There is, however, something else worthy of notice in the above figure. Although it is clear that there is an extra login in production that has not yet been added to D/R, this login is not a one-dimensional entity. It comes with several configurable attributes: type, is_disabled and default_database_name. In a more complicated scenario the login may exist in both instances of the production-D/R pair but with different settings for one or more of these attributes. Locating differences at this level of granularity is not as simple, especially as the number of attributes increases from three, in the case of Server Logins, to eleven for SQL Server Agent Jobs and fourteen for SQL Server Agent Job Steps.
Fortunately there is help in the form of the EXCEPT operator (5,6). When placed between two queries, EXCEPT returns records that in some way differ from the one result set to the other. (The number and order of columns must be the same in the two sets and the data types compatible.) Let's demonstrate this with the earlier example, only in this case the applogin1 server login exists on both instances (production and D/R), as querying the drsync_logins table on the D/R instance shows (remember that in the D/R instance the drsync_logins table contains all logins from the corresponding production instance as well):
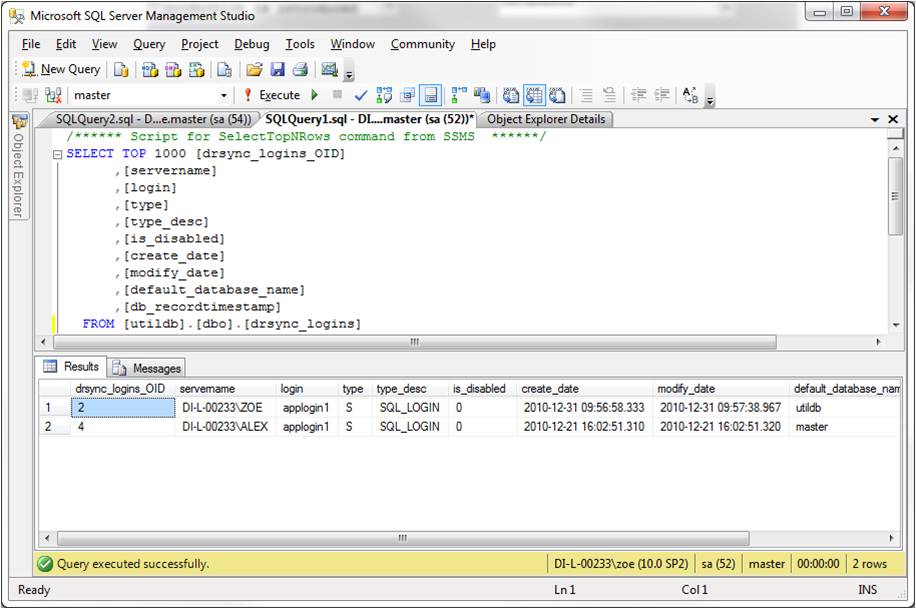
Fig. 2: The drsync_logins table in the D/R instance
Although this time the login exists on both instances, it differs in one setting: default_database_name. In production (DI-L-00233\ALEX) the default_database_name is master, whereas in D/R (DI-L-00233\ZOE) it is utildb. Script EXCEPT_query.sql (see first download at the end of this article) will detect this difference by returning both logins, as shown below (if the settings of the two logins were identical, the script would return no records):
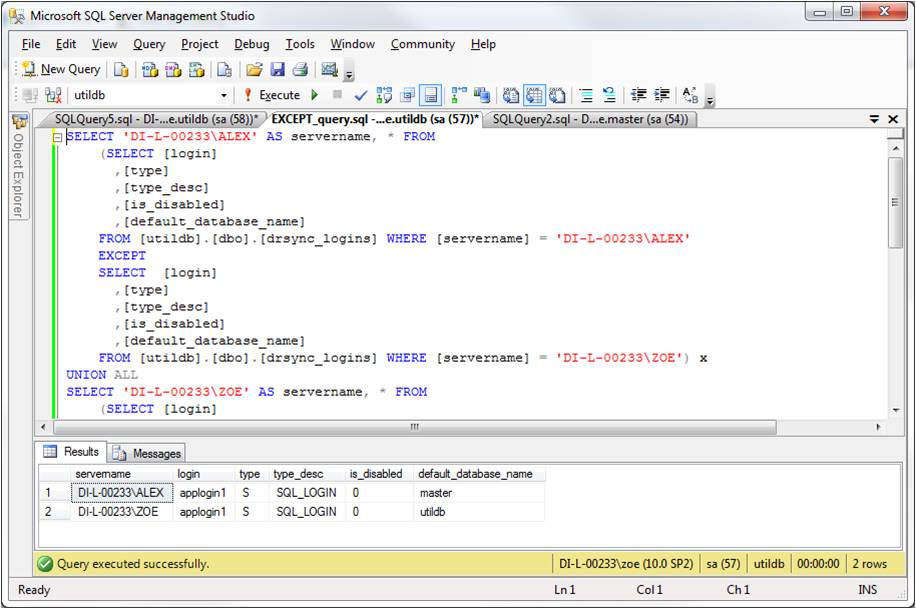
Fig. 3: Output of EXCEPT_query.sql
Queries of the form of EXCEPT_query.sql populate all drsync_xxxx_compare tables with differences between production and D/R SQL instances, so let's look at the structure of this query in a little more detail:
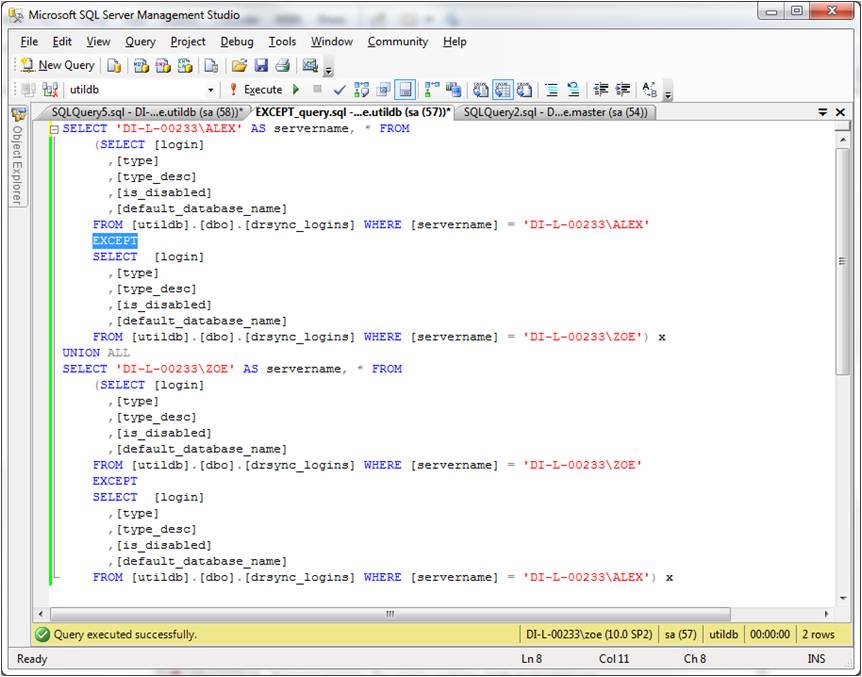
Fig. 4: The EXCEPT_query.sql query
The first half of the query is returning differences of the production instance from its D/R counterpart; the second half is doing the same thing but from the "point of view" of the D/R instance. The two halves are then linked with UNION ALL to return a unified output. Within each half, two result sets - production and D/R - are superimposed using the EXCEPT operator; the columns compared are: [login], [type], [type_desc], [is_disabled] and [default_database_name]. Any difference in one or more of these columns, including absence of an entire record, between production and D/R is returned in the query output, as shown in Fig. 3 above. That data is in turn inserted into table drsync_logins_compare:
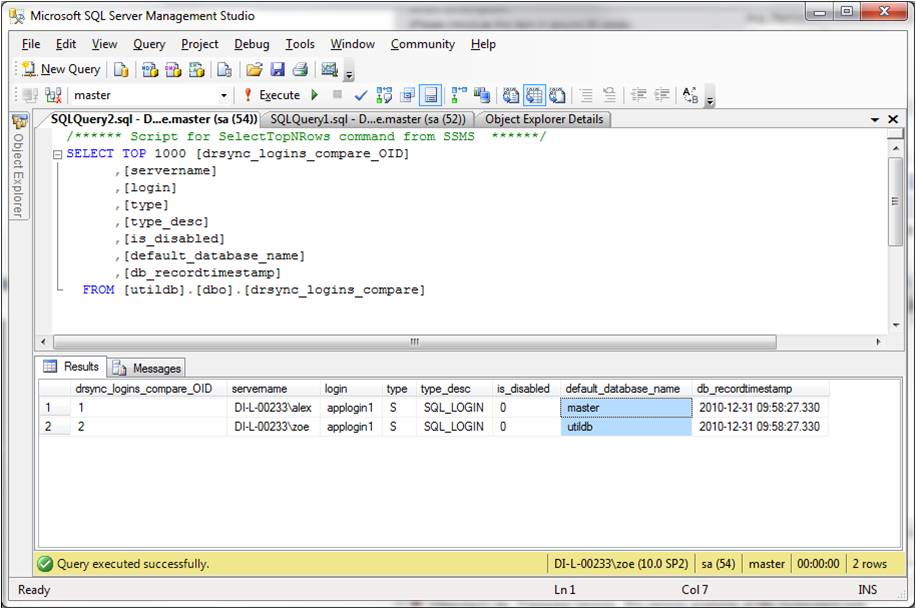
Fig. 5: The drsync_logins_compare table in the D/R instance showing a login that exists in both production and D/R but with a single different setting
SSIS Package DRsync.dtsx
Data retrieval for each configurational category and storage into tables in the utildb database is done in the SSIS package DRsync.dtsx (see Fig. 6). At the top an Execute SQL Task named "Get Server Names" retrieves all prod-D/R SQL-instance pairs from table DRsync_ServerNames in a central database called CentralDb (see attachment CentralDb.sql for script).
Data retrieval for each configurational category and storage into tables in the utildb database is done in SSIS package DRsync.dtsx (see Fig. 6). At the top of the package an Execute-SQL-Task named "Get Server Names" retrieves all prod-D/R SQL-instance pairs from table DRsync_ServerNames in a central database called CentralDb (see file ReadMe.txt for deployment instructions - DRsync-article-download.zip download). The CentralDb database should be preferably deployed in a central admin server but any production or D/R instance will do as well.
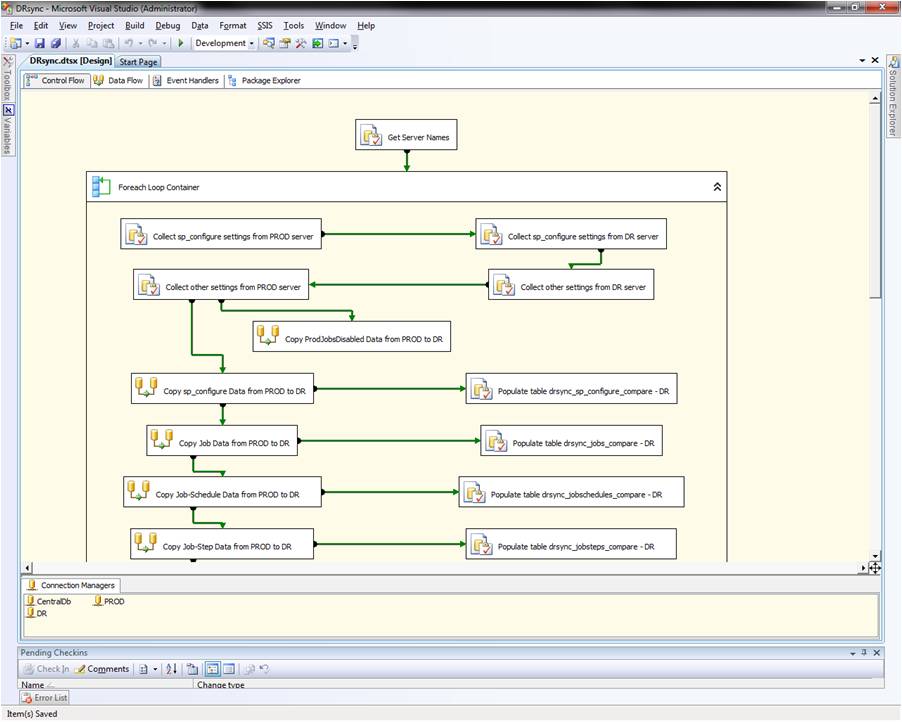
Fig. 6: The DRsync.dtsx SSIS package
The resultset from the "Get Server Names" Execute SQL Task is then saved in variable ObjServerNames and passed to a Foreach Loop Container that is responsible for the bulk of the operations in the package. Two more string variables, ServerNameDR and ServerNameProd, are created and initialized for the D/R and production SQL instance names respectively, here named DI-L-00233\zoe and DI-L-00233\alex (the reader will need to change these names with those from his/her environment before running this package; these names correspond to those found in any one record in table DRsync_ServerNames in the CentralDb database; the CentralDB, Prod and DR connection managers shown at the bottom of the screen in Fig. 6 will also need to be changed accordingly). The variables used in this package are shown in Fig. 7:
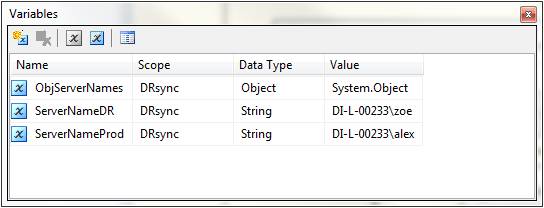
Fig. 7: SSIS-Package Variables
The Foreach Loop Container is using the Foreach ADO Enumerator (9) to cycle through each production-D/R SQL-instance pair. It consists of the following steps:
(a) collects sp_configure settings from the production and D/R instances and populates table [utildb].[dbo].[drsync_sp_configure] in each instance (see Execute-SQL tasks "Collect sp_configure settings from PROD server" and "Collect sp_configure settings from DR server" in Fig. 6);
(b) collects all other settings of the rest of the configurational categories from the production and D/R instances and populates the corresponding tables in each instance (e.g. table [utildb].[dbo].[drsync_jobs]); this task is performed by stored procedure [utildb].[dbo].[DRsync_populate] (see Execute-SQL tasks "Collect other settings from PROD server" and "Collect other settings from DR server");
(c) copies information on which jobs are disabled in production from table drsync_ProdJobsDisabled in the production instance to the same table in the D/R instance (see Data-Flow task "Copy ProdJobsDisabled Data from PROD to DR"); the role of this information is to help determine which jobs to keep as disabled in the event that the D/R SQL instance needs to be turned into "production"; in the D/R instance all "production" (business-related) jobs are deployed as disabled and this particular property is ignored in comparisons between production and D/R;
(d) performs the following tasks for each configurational category: (i) copies the data gathered in the production-instance table in steps (a) and (b) above to the corresponding table in the D/R instance (see, for example, data-flow task "Copy sp_configure Data from PROD to DR" in Figure 6; that task copies all data contained in production table drsync_sp_configure to the corresponding table in the D/R instance); (ii) executes a stored procedure to populate a table in the D/R instance with differences detected between the production and D/R instances for the configurational category in question (see, for example, Execute-SQL task "Populate table drsync_sp_configure_compare - DR" in Figure 6; this task executes utildb procedure DRsync_populate_sp_configure_compare that populates table drsync_sp_configure_compare in the D/R instance; the code for this is analogous to that shown in Figure 4).
The SSIS package is deployed as job "DBA - DRsync.dtsx" to the central admin server and scheduled to run daily.
Job "DBA - DRSync - GetDRSyncInfoToFiles.ps1"
The purpose of the DRsync.dtsx SSIS package is to detect configurational differences in a series of production-D/R SQL-instance pairs and persist the results in the utildb database. The next step is to output this data in a form convenient for a DBA to review and be able to take actions to synchronize the D/R environment with production. This is done by a PowerShell script that loops through the production-D/R SQL-instance pairs and outputs the results in a series of files (one file per instance pair). The script is configured as a SQL Agent job running daily. Fig. 8 shows the PowerShell script:
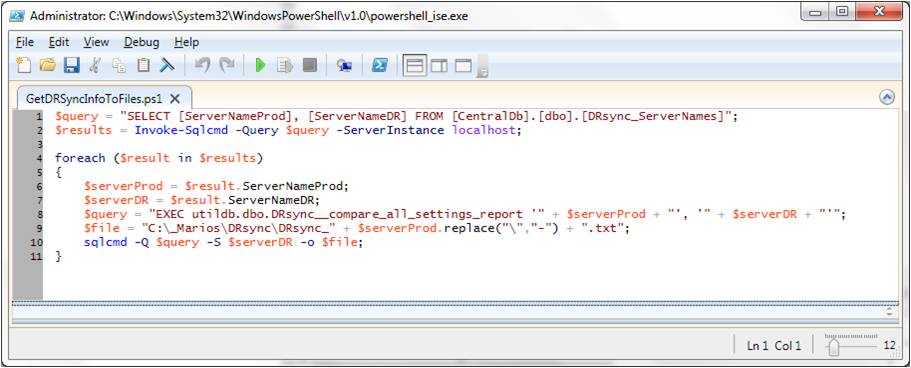
Fig. 8: The GetDRSyncInfoToFiles.ps1 PowerShell script
As a first step, the GetDRSyncInfoToFiles.ps1 script retrieves all production-D/R SQL instance pairs from the [CentralDb].[dbo].[DRsync_ServerNames] table in the central-admin instance. It then cycles through each instance pair executing stored procedure [utildb].[dbo].[DRsync__compare_all_settings_report]. This procedure outputs configurational differences between the production and D/R instance in an easy-to-read formatted file. The contents of a sample file, DRsync_DI-L-00233-alex.txt, showing the differences between the production instance, DI-L-00233\ALEX, and the D/R instance, DI-L-00233\ZOE, are shown in Fig. 9:
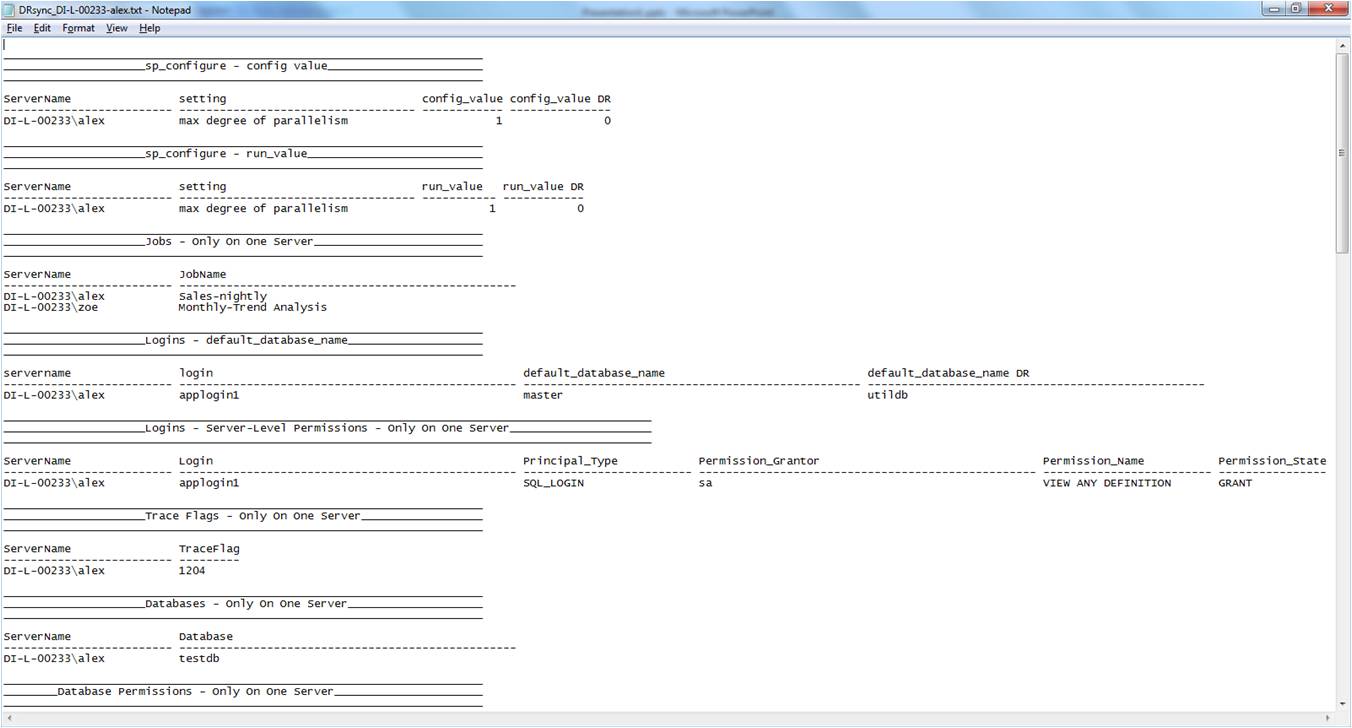
Fig. 9: Configurational differences between production and D/R instances output to a .txt file for analysis
The comparison results in Fig. 9 are organized in two basic forms: (i) objects (or settings) that exist only on one server and not the other are denoted by the suffix "...Only On One Server" in the heading: for example, in the "Jobs - Only On One Server" section we see that job "Sales-nightly" is found only in the production instance, DI-L-00233\alex, whereas job "Monthly-Trend Analysis" is found only in the D/R instance; (ii) configurational attributes that exist on both servers (production and D/R) but with different values are denoted in the heading by the name of the configurational category, followed by the attribute name: for example, in the "sp_configure - run_value" section, the run_value attribute of the "max degree of parallelism" setting is equal to 1 on the production instance, DI-L-00233\alex, whereas on the D/R instance it is 0. Armed with this knowledge, the DBA can then take action to synchronize the D/R environment with production in a way that serves the business needs of the organization both now and in the event of a disaster.
Conclusion and a Roadmap
In this article I have described a framework for tracking configurational differences between production and D/R SQL-Server-instance pairs. However, comparing settings between production and D/R environments is not the only applicable scenario that comes to mind. Any pair of SQL instances can be incorporated in the DRsync framework and the results of this examination used to make one environment consistent with another: a development/test environment can be synchronized with production and a "new" production environment made to match "old" production as part of a migration/upgrade effort. There are many possible applications of this implementation, and the main difficulty is deciding which configurational categories to focus on so comparison of environments is as thorough as needed with no "important" differences being missed.
Rather than a self-contained solution, the implementation presented here is intended as a roadmap and an extensible framework that can easily be adjusted to the particular needs of any environment and organization. (Although here I have focused on features at the SQL-Server-instance level, in a future article I will describe extensions to the DRsync framework pertaining to O/S-level comparisons of database servers.) Having decided on a set of configurational categories to include in the DRsync framework, and having regularly monitored and reconciled discrepancies between the production and D/R environments, the DBA can rest easy that, should the unthinkable happen, he/she will live to fight another day. In a DBA's life it cannot get much better than that!
Note: download file DRsync-article-download.zip contains all functionality discussed in this article, as well as deployment instructions and a roadmap for extending the DRsync framework with new features (see ReadMe.txt file as part of the download).
References
(1) Wiltshire's Underground City: http://www.bbc.co.uk/wiltshire/underground_city/
(2) High Availability Solutions Overview: http://msdn.microsoft.com/en-us/library/ms190202.aspx
(3) Description of disaster recovery options for Microsoft SQL Server: http://support.microsoft.com/kb/822400
(4) GEO Clustering Windows Server 2008 & SQL Server 2008: http://social.msdn.microsoft.com/Forums/en-US/sqldisasterrecovery/thread/cbac5637-10c7-4b6a-a2b7-43f5b8a3a28c
(5) EXCEPT and INTERSECT (Transact-SQL): http://msdn.microsoft.com/en-us/library/ms188055.aspx
(6) SQL Server 2005: Using EXCEPT and INTERSECT to compare tables: http://weblogs.sqlteam.com/jeffs/archive/2007/05/02/60194.aspx
(7) List All SSIS Packages Deployed On Your Integration Server:
http://blog.hoegaerden.be/2010/01/10/list-all-ssis-packages-deployed-on-your-integration-server/
(8) SSIS package version control: http://www.sqlservercentral.com/Forums/Topic463182-148-6.aspx
(9) Using the Foreach ADO Enumerator in SSIS: http://www.codeproject.com/KB/database/foreachadossis.aspx
