

Introduction
When Bob started his Global Supplies business, things were nice and simple. He had some stock, a copy of Microsoft Office, and a basic web site that allowed anyone with access to the Internet to purchase something from his growing range of novelty gifts.
Each day, Bob would go through the list of orders, package them up, fill out a Sales Receipt, and send the items off to his eagerly-awaiting customers.
Bob was particularly pleased with his receipts: they were based on one of the new Microsoft Word templates, and looked quite the part. He kept the original files on his laptop, regularly backed them up to an external drive, and kept the originals in a large old filing cabinet - just in case.
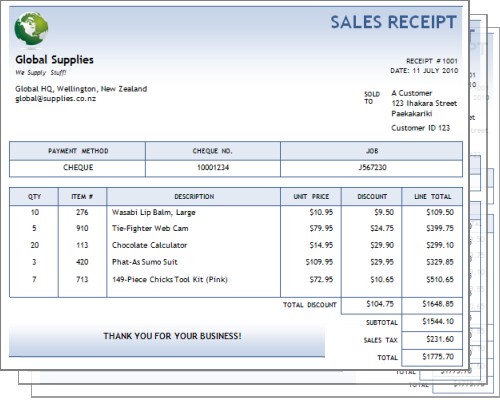
As time went by, and business picked up, Bob looked at his growing stack of Sales Receipts, and wondered if he ought to be making more use of the information they contained. Of course, he had a feeling for who his best customers were, and sometimes flicked through the papers held in the filing cabinet to answer some of the other questions that had popped into his head from time to time.
This could be frustrating at times, because the receipts were stored in a way that wasn't always conducive to answering Bob's question quickly. Sometimes he thought about reorganising things - perhaps placing each customer's receipts in separate folders, or sorting them in a different way, perhaps by name.
The problem was that each potential arrangement seemed to have advantages and disadvantages: sorting by order value would help with some questions, but not others, for example. In the end, Bob came to the conclusion that what he really needed was an Excel spreadsheet.
With a spreadsheet, Bob could record the information held on his receipts in a much more organised way:
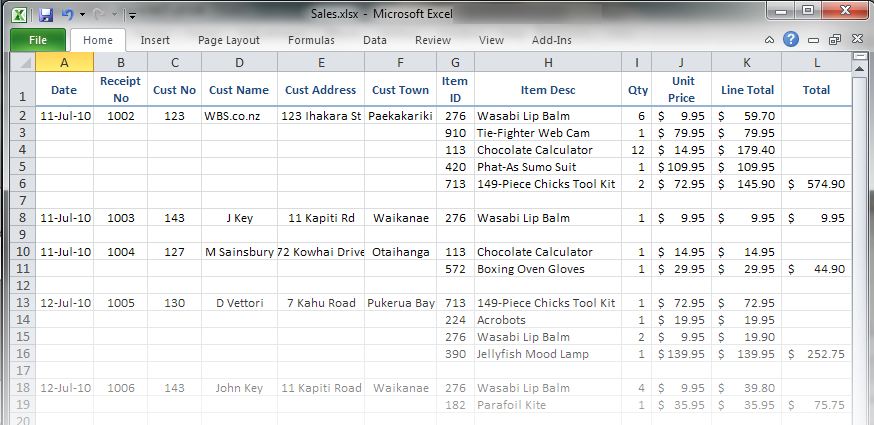
This was much better. Bob could now see a lot more information all at once, and he quickly found ways to filter the data, add calculations, and copy bits to new sheets so he could look at his data in different ways.
Even Spreadsheets Have Limitations
As much as Bob loved his spreadsheet, it still had its problems. He found himself copy-and-pasting a lot. Product descriptions and customer addresses were particularly tiresome. He sometimes couldn't be bothered with that when entering new data, which resulted in slightly different spellings and inconsistent abbreviations.
His spreadsheet also quite often required a fair amount of work to answer his questions. Sometimes, he found himself giving up completely. He realised he wasn't a spreadsheet expert, by any means, but it was still frustrating.
Discussing the situation one evening with his friend Alice, she suggested that perhaps what Bob needed was a database - something like Access, perhaps. She explained that databases were much better at answering the sorts of questions Bob had, and they typically required much less copy-and-pasting.
This sounded good to Bob, but he found that his edition of the Office suite (Home & Business) did not include Access. He briefly considered buying Access separately, or downloading a trial edition, but Alice pointed him instead to a product called SQL Server.
The Express Edition is free, she said, and it comes with something called a Query Optimizer, which Bob thought was a great idea. After all, no-one wants to write sub-optimal queries do they?
When Alice mentioned that this Query Optimizer thing had been worked on by a guy called Conor Cunningham, after he left the Access team, Bob was completely sold on the idea. If he was going to replace his spreadsheet with a database, he might as well use one where the developers had learned from their past mistakes!
A Spreadsheet in SQL Server
Bob downloaded SQL Server 2008 Express Edition and quickly created a Sales table:
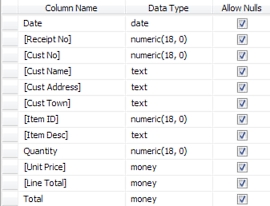
Bob wasn't quite sure he had made the right choices in the Data Type column, but he figured he would ask Alice about that later. He started copying data across from his spreadsheet:
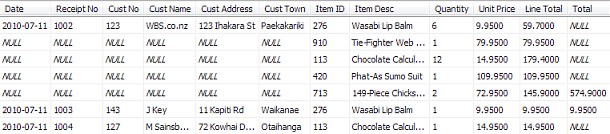
That didn't seem nearly as neat as his spreadsheet - there were all these NULL things, where his spreadsheet just left a blank space. Worse, when Bob used the query designer to show information for customer 123, it showed the wrong results:
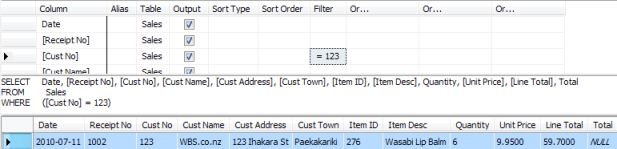
There should be five items not one! Bob thought the problem might be related to those odd-looking NULLs in his table. He decided to get rid of them by copying information from other rows:
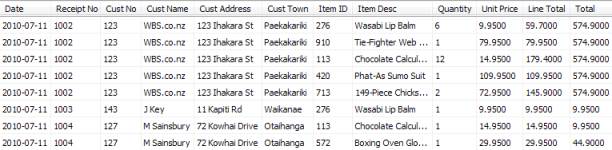
Making these changes meant that Bob's query now returned the correct five rows, but he was far from happy. Using a database seemed to mean he did rather more copy-and-paste than he ever needed to do with his trusty spreadsheet.
The Problem with Duplication
When Bob next saw Alice, he took his laptop along to show what he had done, and expressed his disappointment at the need for so much duplication. What Bob would really like, he explained, was to record each piece of information from his receipts once.
Alice agreed that the duplication was a big problem. Not only did Bob spend a lot of time entering the same information over and over again, the duplicates wasted a lot of space, and introduced the possibility of conflicting information: if Bob made a mistake, and two rows ended up disagreeing about a customer's address, which one should be believed?
Another, more subtle problem, was that there was no neat way for Bob to record information about products he had not sold yet, or customers that had not yet been issued with a receipt.
A Little Design Theory
Alice had briefly studied database design at university, and while that was some time ago now, she agreed to help Bob with his problems as best she could. She explained that although database design was still regarded by many as more art than science, there were some core principles that might be usefully applied.
Her first idea was to use more than one table, with each table representing a single type of real-world thing. This meant recognising that receipts, customers, and product items were fundamentally different things, and each should be stored in its own table.
Bob agreed that this seemed like an idea worth pursuing. Intuitively, it made sense to him that his database should mirror the real world as much as possible, though he was intrigued to see how it would work in practice. Bob had never much enjoyed theory - he wasn't much of an academic - so Alice agreed to try to explain what she was doing in practical terms.
Normalization
Alice explained that the idea of breaking up one large table into several to reduce duplication is called normalization. Bob raised an eyebrow, and Alice took the hint - she would try to cut out the technical jargon from here on in. She picked up a printed copy of Bob's table, and added some shading to show what she had in mind:

She used green to highlight receipt-related columns, orange for customer information, and purple for data which applied to products. Alice said that the red columns showed a more subtle type of duplication: their values could be calculated from other columns in the table, so they didn't represent anything new. Bob could see this was true, and was all in favour of removing duplication wherever they could.
With that agreed, Alice set about creating the three new tables, one each for Receipts, Customers, and Products. As she typed, Bob asked her about the mysterious data types he had encountered earlier. Alice explained that each column had to have a data type, and it was important to choose an appropriate one from the wide range offered by SQL Server.
Generally speaking, Alice said she would choose the most compact type that could contain all values the column would ever need to hold. Bob had a quick look at the list of data types, and quickly realized that his initial choices had been less than ideal! He was particularly embarrassed about choosing the text data type,because there was a big warning on the Microsoft web site discouraging its use.
The Three Tables
The first version of Alice's design looked like this:
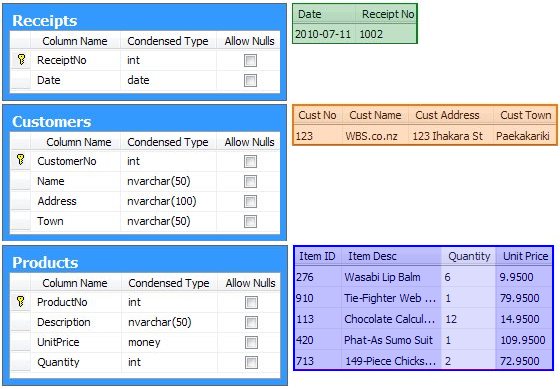
Bob noticed two things: Alice had used more appropriate data types, and the new design had allowed her to untick all the 'Allow Nulls' boxes. He was quite pleased about that second change, because he had no idea what a NULL was, and he had certainly never seen one on a real receipt!
Bob agreed that the three table design removed a lot of the duplication. He could now make a single entry per receipt in the Receipts table, one entry per customer in the Customers table, and one entry per product in the Products table. This was definitely progress!
Keys and Uniqueness
Alice said that no table should ever contain duplicate rows, and there should always be something called a primary key to enforce that. Seeing Bob's puzzled expression, Alice pointed to the little golden key symbols in her diagram. The primary key, she explained, is a column (or a minimal combination of columns) with values that are different for each row in the table.
SQL Server would enforce the key's uniqueness, so anyone trying to enter a new row with a duplicate key would receive an error message. Bob thought this was a very useful idea, and made a note to never create a table without also adding a primary key.
Alice also mentioned that additional uniqueness constraints should be placed on each table to guarantee that everything that is unique in the real world is unique in the database too. When Bob asked what she meant by this, she pointed out that it was still possible to add duplicate information to the Customers table, for example, as long as a different customer number was used.
If Bob wanted to make sure that a real-world customer only ever had one customer number, Alice would need to add another unique key to the table. She told Bob that although each table could only have a single primary key, a practically unlimited number of additional keys could be added to help guard against logical inconsistencies or data-entry mistakes.
Bob decided that he was happy with just the primary key on the customer number for the time being; he only had a small number of customers, and he was sure that his pocket notebook only contained a single customer number for each real-world person. Alice said that was OK for now, but they should look at the issue again in the very near future. Bob was happy with that.
One other thing was still puzzling Bob: in Alice's diagram, why does the Quantity column in the Products table have slightly different shading?
Dependencies on Keys
Alice explained that an important part of table design is to ensure that each column in a table states a single fact about a key, and that was not the case with the Quantity column. Bob's eyes glazed over slightly when she said that, so Alice gave an example:
In the Customers table, she said, notice how each column contains a single fact about a single customer (identified by the primary key: CustomerNo). Now look at the Products table: the Description and UnitPrice columns each state a single fact about a particular product (again identified by the primary key: ProductNo).
The Quantity column is a bit different, remarked Alice. The quantity of product does not depend solely on ProductNo - the quantity will often be different for the same product on different receipts. So, the quantity is determined by a combination of ProductNo and ReceiptNo - not ProductNo alone.
Bob asked if Alice could just change the primary key on the Products table to include both the ProductNo and ReceiptNo columns. She said no, because then the other columns (Description and UnitPrice) would depend on just part of the new key. It was essential, she said, for each column in a table to depend on a key, the whole key, and nothing but the key.
This all sounded rather technical to Bob, but he grasped the basic idea. The question was, what should he do about the troublesome Quantity column? It seemed not to belong in the Products table at all - it appeared to belong in a table with ReceiptNo and ProductNo as a primary key, but they didn't have one of those! Not yet, said Alice, and smiled.
Table Relationships
Before we find a permanent home for the Quantity column, said Alice, we need to look at how the tables we already have relate to each other. After all, we will need to find a way to link them together if we ever want to ask questions about more than one type of thing (customer, receipt and product).
Bob said he had been wondering about that: it was all very well dividing his table up into three, but how could he match the rows up? How could he see which receipts belonged to which customer, for example?
Alice replied by asking him to look at the Customers and Receipts tables. These tables were an example of a one-to-many relationship, she said. One customer might have many receipts, but each receipt only ever related to one customer. Bob confirmed that this was indeed true, but wondered how that helped.
One-to-Many Relationships
Modelling a one-to-many relationship between two tables was easy, said Alice. All they had to do was to add something to each row of the Receipts table, linking back to the parent customer. Bob thought about this, and asked if this pointer would just be the customer's primary key. Alice confirmed that he was correct, and updated her design accordingly:
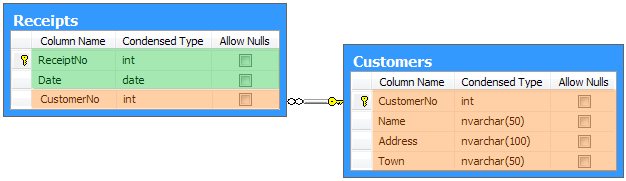
Alice explained that the new CustomerNo column in the Receipts table was known as a foreign key. Bob noticed that the new column did not break Alice's rule (columns should state a single fact about the whole key). Each row in the Receipts table was indeed associated with a single customer.
Alice drew Bob's attention to the new connecting line in her diagram, which she said represented a foreign key relationship. SQL Server would enforce this relationship, similar to the way it enforced primary key uniqueness. The practical consequence was that Bob could not add a receipt to his database without first creating a customer record for it to link to.
Bob thought this was a very cool feature - SQL Server would make sure he could not add information that didn't link up properly.
Many-to-Many Relationships
Alice now turned to the task of linking the Receipts and Products tables. The link between these tables was going to be a bit different because each product could appear on many different receipts, and each receipt could contain many different products. This, she said, was known as a many-to-many relationship.
Bob started thinking about how they might add foreign keys to each table to represent this kind of link, and it made his head hurt almost immediately. Each table would need to hold a variable number of foreign keys in each row - was that even possible?
Alice said that to model this relationship correctly, she would need to add another table to the design. She called this a bridge table, and it would sit between the Products and Receipts tables
She explained that bridge tables were necessary whenever two tables had a many-to-many logical relationship. Because the new table modelled the link between the Receipts and Products tables, its primary key would be a combination of the primary keys of the related tables (she called this a compound key).
Bob wasn't sure about this at all, but Alice seemed to know what she was talking about, so he waited to see how this new idea would look before passing judgement.
An Improved Design
Alice called the new table ReceiptProducts, and added it to the overall design:
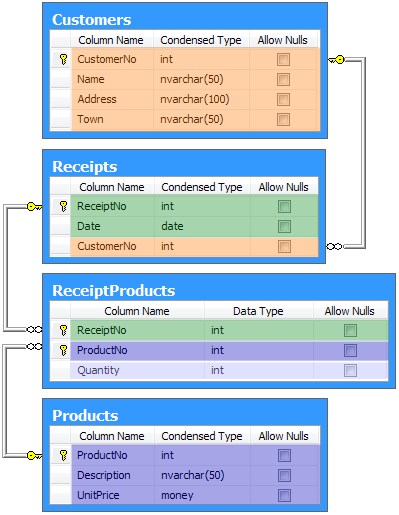
The Customers and Receipts tables had not changed, but Bob noticed that the problematic Quantity column had found a home in ReceiptProducts. He remembered that the Quantity column was a single fact about a receipt/product combination, so it made sense to see it in a table with that combination as its primary key.
Bob also saw that the new table was linked by two one-to-many foreign key relationships: one to the Receipts table, and one to the Products table. These new foreign key relationships ensured that Bob could not accidentally add a Quantity without first entering a related product and receipt.
Entering Data
Returning home for the evening, Bob found that the new design made it easy to add new information in a logical order, and without the duplication he was used to.
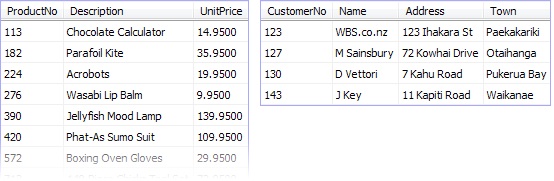
He started by adding a complete list of products to the Products table. He was happy that he would only have to enter the descriptions and prices once, and working from his price list made the task quick and easy. Whenever Bob lost his place and tried to enter a product for a second time, SQL Server replied with an error message, which Bob found very reassuring.
Next, Bob reached for his notebook and started adding customer information to the Customers table. Again, this was quick and easy, and the information only needed to be typed in once.
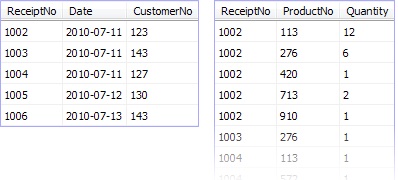
When he came to add data to the Receipts table, Bob was relieved to be able to refer to the customer by number, rather than retyping the name, address, and town information each time as he used to with the spreadsheet. The ReceiptProducts table was just as easy; he just needed to link products to receipts and enter the quantity.
Writing Queries
Though he started off using the visual query designer in Management Studio, Bob quickly picked up the basics of the T-SQL query language. The relationship diagram Alice had given him made it easy to see how his tables should be joined together, and Bob quickly found himself preferring the SELECT, JOIN, and WHERE syntax over the designer.
Bob was delighted to find that his database could answer a range of questions about his business. He thanked Alice for helping him understand some of the fundamentals of database design - and particularly how to avoid duplication.
A Continuing Process
Alice said that removing duplication was a great start, but that the design was still far from finished. Bob said that he felt as if his brain was full for the moment, so they agreed to meet up again in a few days to see how Bob was getting along with his database, and to give Alice a chance to explain what further improvements she thought were needed, and why.
Summary
- Every table needs at least one key to uniquely identify each row
- Additional keys should be defined to enforce uniqueness seen in the real world
- Use appropriate column data types
- Each column in a table should state a single fact about the whole of the key
- Break tables that violate that rule into logical parts, based on real-world objects where possible
- Enforce one-to-many relationships using foreign keys and constraints
- Model many-to-many relationships using bridge tables
If you have more of an interest in the theory behind database design than Bob did, take a look at the articles on database normalization on Wikipedia.
Alice and Bob will return.
© 2011 Paul White
Blog: sqlblog.com/blogs/paul_white
Twitter: @SQL_Kiwi
Email: SQLkiwi@gmail.com

