

Introduction
Columnstore indexes were a significant addition in SQL Server 2012, greatly improving the performance of report-style queries on large data sets. Common OLAP operations such as sums, counts, and other statistical analysis were previously very expensive and would often need to read much of a table’s data into memory before being able to complete those calculations.
This new feature came with many limitations, though. Some of the most noticeable were:
- Many data types were not supported, such as binary, unique identifier, and decimals with precision > 18.
- Only nonclustered columnstore indexes were allowed - you could not create a clustered columnstore index.
- Columnstore indexes could never be written. In order to change any underlying data, the index would need to be disabled and rebuilt or dropped and re-added.
- Some operators were not fully supported when using a columnstore index, such as a LEFT JOIN or UNION ALL.
SQL Server 2014 resolved all of the above issues, as well as included many architectural improvements that increased query performance without any need for our intervention.
This tutorial will walk through the creation and usage of columnstore indexes on a SQL Server 2014 instance and illustrate some of the significant changes along the way.
Creating and Using Columnstore Indexes
Using the AdventureWorks2012 database, we will populate a new table based on Person.Person with a much larger volume of data than is shipped by default with this table. We’ll call this new table dbo.People:
-- Create a new table to store large amounts of data from Person.Person
CREATE TABLE dbo.People(
BusinessEntityID int NOT NULL,
PersonType nchar(2) NOT NULL,
NameStyle dbo.NameStyle NOT NULL,
Title nvarchar(8) NULL,
FirstName dbo.Name NOT NULL,
MiddleName dbo.Name NULL,
LastName dbo.Name NOT NULL,
Suffix nvarchar(10) NULL,
EmailPromotion int NOT NULL,
ModifiedDate datetime NOT NULL,
CONSTRAINT PK_People_BusinessEntityID PRIMARY KEY CLUSTERED
(BusinessEntityID ASC))
GO
-- Populate the new table with 100x the data from Person.Person
INSERT INTO dbo.People
( BusinessEntityID ,
PersonType ,
NameStyle ,
Title ,
FirstName ,
MiddleName ,
LastName ,
Suffix ,
EmailPromotion ,
ModifiedDate
)
SELECT
ROW_NUMBER() OVER (ORDER BY BusinessEntityID) + ISNULL((SELECT MAX(BusinessEntityID) FROM dbo.People), 0),
PersonType ,
NameStyle ,
Title ,
FirstName ,
MiddleName ,
LastName ,
Suffix ,
EmailPromotion ,
ModifiedDate
FROM Person.Person
GO 100 -- Do this 100 times --- end result is 1,997,200 rows in dbo.People
-- Create a standard nonclustered index on ModifiedDate and MiddleName. This will be used to compare/contrast performance with a
-- Nonclustered columnstore index shortly.
CREATE NONCLUSTERED INDEX NCI_People
ON dbo.People
(ModifiedDate)
INCLUDE (MiddleName)Now that we have our new schema and data set up, let’s run a baseline test of a simple query against this table:
-- Test query against our new data set & nonclustered index w/ performance stats from my desktop SQL Server instance:
-- Index Seek/Aggregate, 13.7724 CPU, 5 scans, 5259 logical reads, 227ms
SELECT
MiddleName,
COUNT(PersonType),
COUNT(EmailPromotion)
FROM dbo.People
WHERE ModifiedDate > '1/1/2005'
GROUP BY MiddleNameOur query takes a moment to run and uses our new nonclustered index:

Table 'People'. Scan count 5, logical reads 9950, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
The resulting execution plan is as efficient as it gets for this query, but we did get quite a few reads as part of this operation.
Now, we’ll add a columnstore index to our new table. The syntax is almost identical to that used in the creation of a standard nonclustered index:
CREATE NONCLUSTERED COLUMNSTORE INDEX CSI_People ON dbo.People (MiddleName, PersonType, EmailPromotion, ModifiedDate) GO
Running the same test query again, we can see a definitive performance improvement:

Table 'People'. Scan count 4, logical reads 3368, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
In addition to a simpler execution plan and less reads, the execution time dropped to 1/5 of what it previously was.
There are a number of reasons why a columnstore index can provide superior performance. In addition, there are circumstances when columnstore indexes are far more useful and others where they would provide no improvement or not be used by the query optimizer. Microsoft has a relatively straight-forward introduction to their architecture, benefits, and best practices here:
http://msdn.microsoft.com/en-us/library/gg492088.aspx
New Features in SQL Server 2014
Now that we have introduced a simple example of how to create & use a columnstore index, we can investigate the changes between SQL Server 2012 and SQL Server 2014.
Clustered Columnstore Indexes: Readable AND Writable!
The biggest limitation in SQL Server 2012 was that we could not update any underlying data in a table with a columnstore index. Starting in SQL Server 2014, we can create a clustered columnstore index on a table, which allows our columnstore index and the underlying data structure to become one and the same, and therefore allow for DML to make changes to our data.
Note: Clustered columnstore indexes are only supported in Enterprise, Developer, and Evaluation editions of SQL Server.
If we tried to run any insert, update, delete, or merge in SQL Server 2012 or 2014 using the table with our nonclustered columnstore index, we would receive the following error:
Msg 35330, Level 15, State 1, Line 6
UPDATE statement failed because data cannot be updated in a table with a columnstore index. Consider disabling the columnstore index before issuing the UPDATE statement, then rebuilding the columnstore index after UPDATE is complete.
In order to illustrate this new feature, we will take our table from above and remove all existing indexes on it:
DROP INDEX CSI_People ON dbo.People DROP INDEX NCI_People ON dbo.People ALTER TABLE dbo.People DROP CONSTRAINT PK_People_BusinessEntityID GO
Once these have been removed, a clustered columnstore index will be added:
CREATE CLUSTERED COLUMNSTORE INDEX CSI_People ON dbo.People GO
When creating a clustered columnstore index, there is no need to specify key columns. In fact, if you try to do so, the command will fail with an error:
CREATE CLUSTERED COLUMNSTORE INDEX CSI_People ON dbo.People (MiddleName, PersonType, EmailPromotion, ModifiedDate) GO
Run this SQL and you’ll immediately receive the following error:
Msg 35335, Level 15, State 1, Line 116
CREATE INDEX statement failed because specifying a key list is not allowed when creating a clustered columnstore index. Create the clustered columnstore index without specifying a key list.
Since a clustered columnstore index describes the physical structure of our data storage, all columns in the table are included be default. This is the reason why key columns cannot be specified in the index definition above. In addition, since the underlying data is not structured in the same manner as a standard table, the table cannot have any other indexes on it aside from the clustered columnstore index. Also, since the clustered columnstore index describes the underlying data in the table, the lack of a need for additional nonclustered indexes coupled with the inherent compression in the columnstore index can result in significant disk space savings.
Now that we have our clustered columnstore index in place, we can test an UPDATE statement to illustrate how we can write to the underlying data successfully:
UPDATE dbo.people SET middlename = 'n' WHERE businessentityid = 3
This SQL takes a few seconds to execute and results in a suboptimal execution plan with some hefty reads:

Table 'People'. Scan count 2, logical reads 3006, physical reads 7, read-ahead reads 860, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Now that we have removed our old clustered and nonclustered indexes from this table, a full table scan is required to find the single row that the query is trying to update. Columnstore indexes are built for aggregate queries across large volumes of data, so a query that tries to select or update on a row-by-row basis will be painfully inefficient.
An INSERT into our table can be fast, though, if we keep it simple:
INSERT INTO dbo.People
( BusinessEntityID ,
PersonType ,
NameStyle ,
Title ,
FirstName ,
MiddleName ,
LastName ,
Suffix ,
EmailPromotion ,
ModifiedDate
)
SELECT
0,
PersonType ,
NameStyle ,
Title ,
FirstName ,
MiddleName ,
LastName ,
Suffix ,
EmailPromotion ,
ModifiedDate
FROM Person.Person
WHERE Person.BusinessEntityID = 1 
Table 'Person'. Scan count 0, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Since columnstore indexes were developed and optimized for use in data warehouse/reporting environments, deleting, merging into, and updating existing data is going to be habitually slow since there are no indexes to help speed those searches along. Inserts will generally be very fast as we can ignore the rest of the table as part of the operation, update the clustered index, and be on our merry way!
If there is any need to perform extensive updates on existing data in a table with a columnstore index, it may be faster to remove the index and add standard nonclustered indexes to facilitate the operation. When complete, the columnstore index can be added back to the table so that future reporting-based read operations can be suitably efficient.
More Operators = More Options
One of the most powerful features of columnstore indexes was the introduction of batch processing. Traditionally, SQL Server queries operate on rows of data. Rows are organized on pages and queries will return rows of data at a time. Complex reporting queries often operate on large sets of data, calculating sums, counts, or other analysis across many (or all) rows in the table.
Since columnstore indexes store data based on columns and not rows, we can return results across many rows at once in a single batch. SQL Server 2012 had many restrictions on batch processing, though. Many operations, such as outer joins, UNION ALL, and NOT IN resulted in execution plans that could not be batch processed and would either execute using row mode processing or a mix of both (if possible), or perform inconsistently based on the underlying data.
We can verify the mode used via the properties in the execution plan:
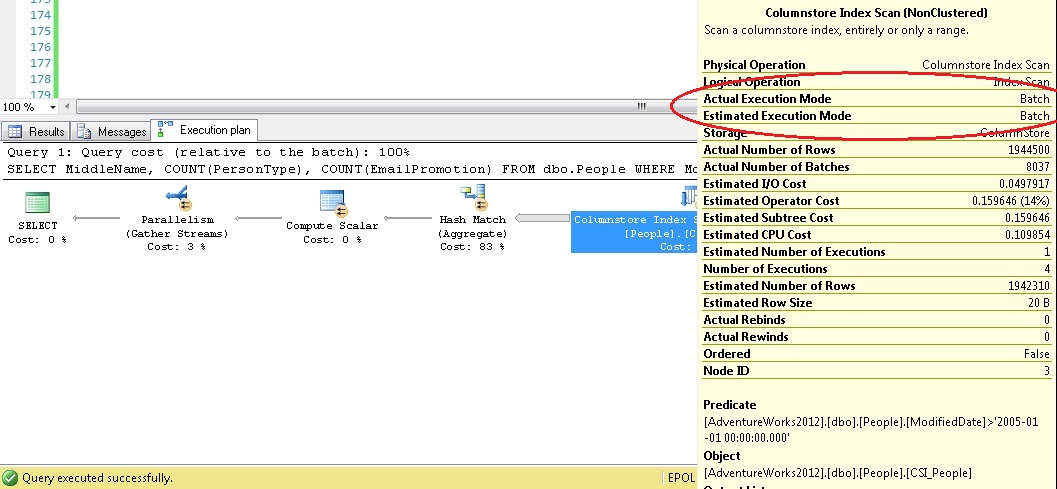
Let’s create a simple example of the difference in behavior between SQL Server 2012 and 2014:
DROP INDEX CSI_People ON dbo.People GO CREATE NONCLUSTERED COLUMNSTORE INDEX CSI_People ON dbo.People (LastName) GO SELECT DISTINCT LastName FROM dbo.People WHERE LastName NOT IN (SELECT LastName FROM Person.Person) ORDER BY People.LastName
Executing this TSQL in SQL Server 2012 results in the following execution plan:
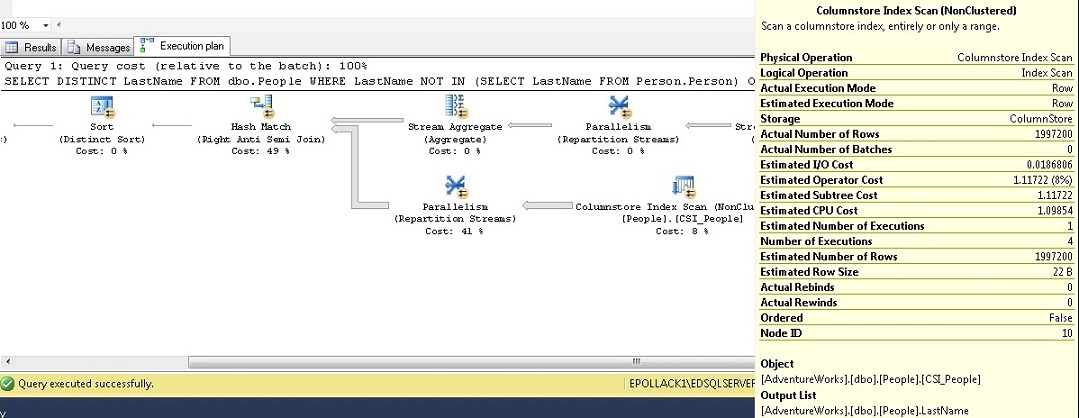
Note that the actual execution mode is “Row” and not “Batch” as we were hoping for. For SQL Server 2012, Microsoft had recommendations on ways to rewrite queries in order to take advantage of batch processing, but it was not always possible or efficient to do so.
Running the exact same query over the same data set in SQL Server 2014 returns this execution plan:
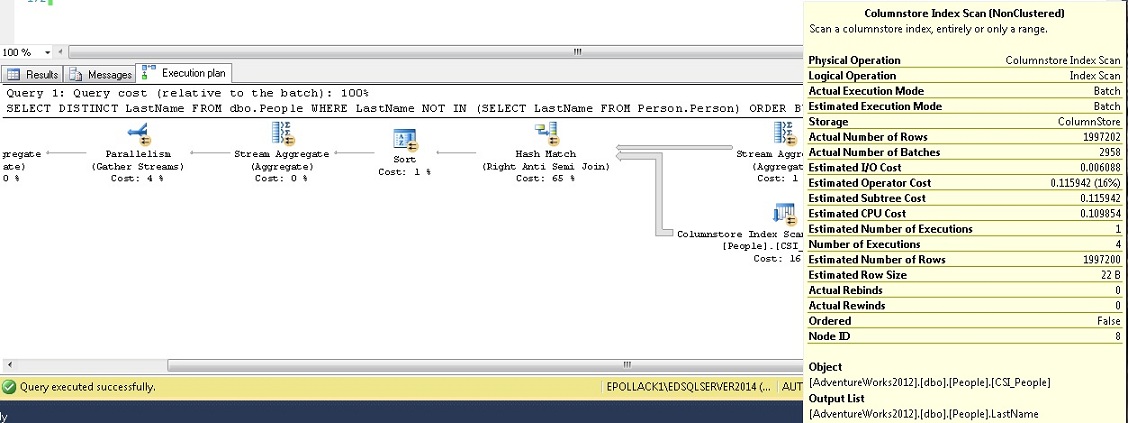
This time, batch mode was used, and we can confirm that I/O and CPU utilization were noticeably less for this operator as a result.
Additional Notes
There are a number of other optimizations and improvements in SQL Server 2014 with regards to columnstore indexes that are worth noting here:
Data Types
In SQL Server 2012, you could not include the following data types in a columnstore index: binary, varbinary, ntext, text, image, varchar(max), nvarchar(max), uniqueidentifier, rowversion, timestamp, sql_variant, decimal/numeric with greater than 18 digits of precision, datetimeoffset with a scale greater than 2, CLR types, and XML.
In SQL Server 2014, all data types can be used in a columnstore index, except for: ntext, text, image, varchar(max), nvarchar(max), rowversion, timestamp, sql_variant, CLR types, and XML. This is a significant improvement, and it is generally unlikely that you will have reasons to report on or analyze these particular data types in a data warehouse environment.
Writing to a Clustered Columnstore Index
Technically, a columnstore index cannot be written directly. The compression algorithm used on the underlying data is complex enough that DML queries to change this data could be very slow if changes were written immediately. To facilitate the writable nature of clustered columnstore indexes, a Delta Store and Delete Bitmap are used in conjunction with the index itself.
Whenever an insert, update, merge, or insert statement is executed, those changes are put into a row-oriented (B-Tree) Delta Store and Delete Bitmap. Deletions are recorded in the Delete Bitmap, and signify rows to be excluded from the result sets returned by SQL Server. Inserts are recorded in the Delta Store as additional data to be included in result sets. An update statement is broken into a delete and insert and handled just as described. A merge statement will be broken down into its corresponding insert, update, and delete statements, which are then processed separately.
When a query is executed against the index, data is retrieved as discussed previously, but it will have to take into account the Delta Store and Delete Bitmap as needed to ensure that the results are up-to-date and accurate.
A background process runs asynchronously to merge the Delta Store and Delete Bitmap with the column store, ensuring that these change tables never grow too large and that reads on the column store are not blocked or slowed down by this cleanup process.
Columnstore Archiving
In SQL Server 2014, a columnstore index can be rebuilt with further data compression than is provided by default. This compression is enabled per index or partition and is intended to offer further savings to disk utilization for data that is rarely accessed. Adding this additional level of compression to an index can be achieved with the following TSQL:
ALTER INDEX CSI_People ON dbo.People REBUILD WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
The compression on a columnstore index can be returned to its original level by changing from COLUMNSTORE_ARCHIVE to COLUMNSTORE:
ALTER INDEX CSI_People ON dbo.People REBUILD WITH (DATA_COMPRESSION = COLUMNSTORE)
This additional compression will reduce read/write performance, so it should only be considered in cases where data is infrequently used. A good use-case for this compression would be a partition with old, archived data that is very rarely reported on anymore.
Conclusion
SQL Server 2014 greatly improved upon columnstore indexes by increasing support for new data types, new operators, writable indexes, and new storage improvements. In addition, the query optimizer was improved to generate better query plans given a table with a columnstore index.
While the optimizations and improvements seen in the above examples are not unbelievably immense, they underscore how significant gains can be the larger a data set gets. In huge data warehouse environments, gains of 10x-100x have been consistently reported by users that took advantage of columnstore indexes.
As with any new features, thorough testing should be conducted prior to adopting them, but for those already using columnstore indexes, SQL Server 2014 offers consistent improvements with no downside. For anyone not yet using columnstore indexes, these new enhancements are likely the reason to research and start implementing them in environments that previously may not have benefitted fully from their usage.
