Reading the title, most of you are probably thinking: What does database synchronization have to do with the Software Development Life Cycle (SDLC)? Stick around, because I'll get to that in just a minute. First, let me give a quick introduction to SDLC for those one or two developers out there who, by an impossible twist of fate, may have never heard of SDLC in their working experience. SDLC is a multi-phase process which ensures that good software is supplied to the customers. The term 'good software' has quite a broad definition but generally, 'good software' implies software that meets the requirements, has been tested thoroughly and has minimal errors. SDLC has a number of variations, but usually the software will go through these 5 stages:
- Requirement analysis
- Design
- Implementation / Development
- Testing
- Maintenance
Since the synchronization process is fairly straightforward and more or less the same in most of the scenarios, I'll first explain the other scenario in which database synchronization is necessary and then demonstrate how it's done and how to automate it.
The other, very important stage where database synchronization might take place in, is maintenance. In this stage, this process is done in both directions. First of all, for every bug fix or new feature, schema changes and lookup data are transferred from the development environment to the testing and then the live one. This process is the same as the one in the testing stage. Secondly, to make sure that the software is working correctly, quality assurance is performed. Quality assurance can have its own environment or it can use the testing environment. One thing is for certain though, it needs to have data that is as close as possible to the live data. Obviously, no type of data satisfies this condition better than the live data itself. By using xSQL Data Compare, these live data can be transferred to the quality assurance environment where they can then be used as needed.
Without further ado, let's proceed to a demonstration of schema and data synchronization. I'll be using the AdventureWorks2012 database in this demo. I made a copy of this database (AdventureWorksCopy) which will be used as the testing environment's database. Suppose this database belongs to a company that has decided to extend its medical and dental benefits to the employee families. Obviously, they will want to have some data in the system for the employee's family members. To do this, a table called EmployeeDependant is added to the HumanResources schema in the development database which has records for the employee's families. Of course, before this feature can be published it needs to be tested, which means that the schema changes need to be transferred to AdventureWorksCopy. There are 4 very simple steps to this process.
- Add the databases in xSQL Schema Compare.
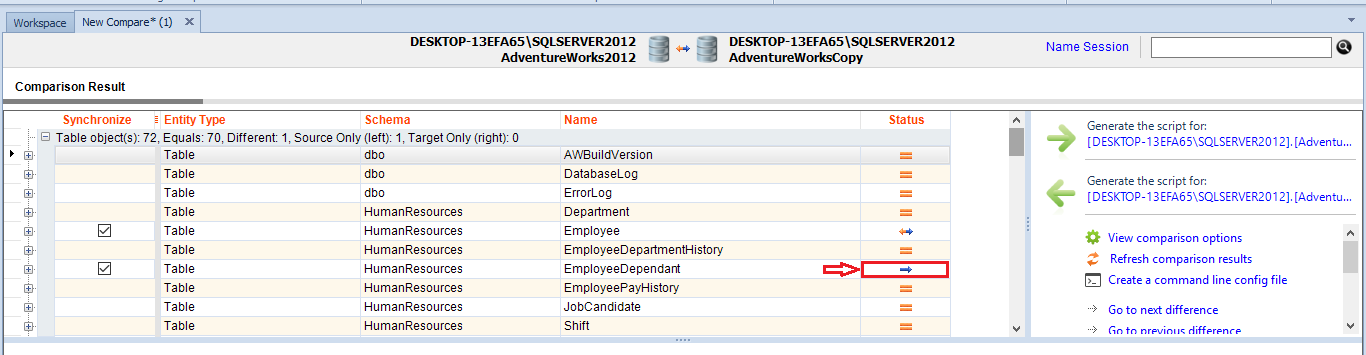
- Compare AdventureWorks2012 with AdventureWorksCopy. The comparison reveals that there is a table EmployeeDependant in AdventureWorks2012 that does not exist in AdventureWorksCopy (note the one-way arrow to the right).

- Generate the synchronization script.
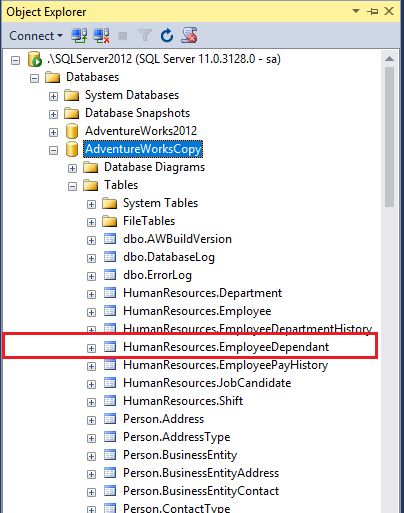
- Execute the script. By opening the database in SSMS I can see that the EmployeeDependant table is added to the AdventureWorksCopy database.
The new EmployeeDependant table has a column named 'RelationshipWithEmployee'. Instead of it being a simple VARCHAR column it's better to have it as a foreign key to a 'Relationships' table. The records in this table will probably never change (there is a fixed number of relationship types in a family), so it can be used as an example of the lookup data that may need to be transferred from the development environment to the testing one. Doing this synchronization with xSQL Data Compare is, again, a very straightforward process. Before I show this process' steps, here is a screen shot of the data in the Relationships table that will be transferred to the AdventureWorksCopy database:

To add these data to the Relationships table in AdventureWorksCopy database do the following:
- Add the databases to xSQL Data Compare.
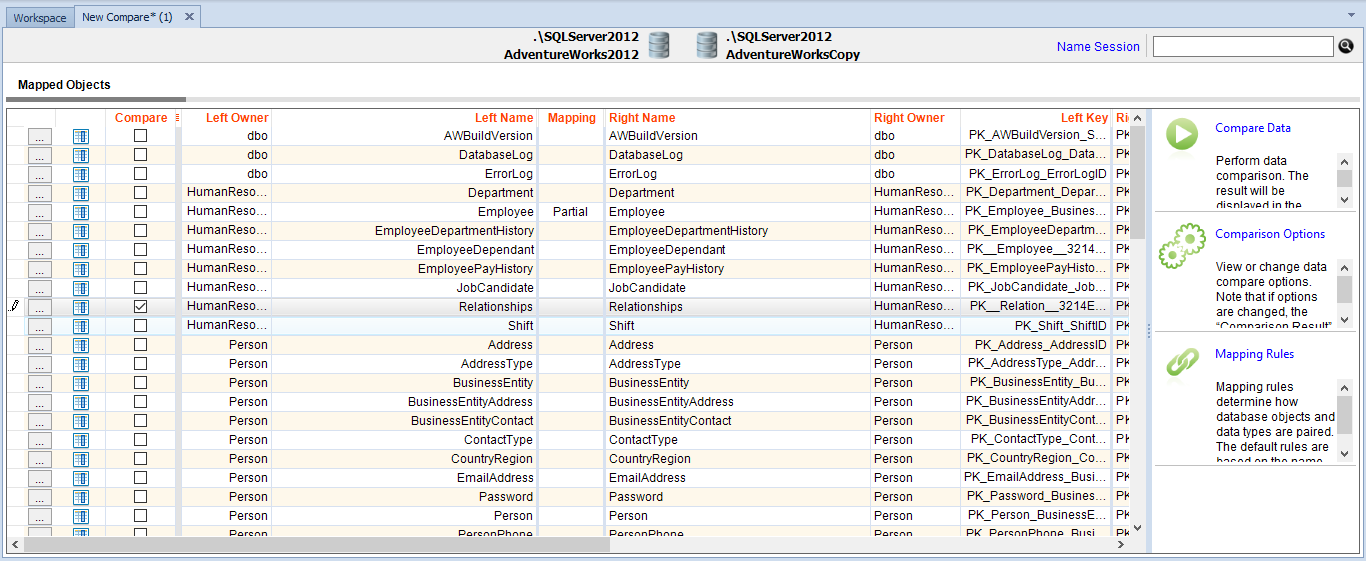
- Choose the objects that need to be compared. In this case, only the Relationships table will be synchronized, so only that table will be selected from the objects to be compared.
- Compare the tables
- Generate the synchronization script for the AdventureWorksCopy database, Here is the script that is generated:
SET XACT_ABORT ON;
SET ARITHABORT ON;
SET NUMERIC_ROUNDABORT OFF;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
BEGIN TRANSACTION;
/*-- -Insert(s): [HumanResources].[Relationships] */
SET IDENTITY_INSERT [HumanResources].[Relationships] ON;
INSERT INTO [HumanResources].[Relationships] ([Id],[RelationshipName]) VALUES(1,'Spouse');
INSERT INTO [HumanResources].[Relationships] ([Id],[RelationshipName]) VALUES(2,'Sibling');
INSERT INTO [HumanResources].[Relationships] ([Id],[RelationshipName]) VALUES(3,'Parent');
INSERT INTO [HumanResources].[Relationships] ([Id],[RelationshipName]) VALUES(4,'Child');
SET IDENTITY_INSERT [HumanResources].[Relationships] OFF;
COMMIT TRANSACTION; - Excecute the script. After execution, if a select query is run on the Relationships table AdventureWorksCopy database, it will display the following data:

Using a similar process to the one in this demo you can copy the data in the live database in the Quality Assurance database and run any tests that you need.
In most cases, these tasks are repetitive. For example, an organization might have the practice of synchronizing the live data with quality assurance every 3 days. Instead of doing this manually every time, you can just generate a XML configuration file for xSQL Data Compare Command Line by clicking the button in the picture below and then, using Windows Scheduler, schedule the comparison to be run periodically with that XML file as an argument.