

 |
| http://www.flickr.com/photos/_barney/5177975707/ |
Hello Dear Reader, yesterday I posed the question to you what are Statistics? We could get down and dirty of how the internals of SQL Server use Statistics (and we will), but first let’s talk about the concept because it is at heart a very simple one.
In America we are in my favorite season, Fall. The weather is cool but not to cold. The leaves turn beautiful colors, the smell of wood burning in a fire place, fire pit, or the general smokey scent that goes with the great out doors this time of year always springs to mind.
 Unfortunately we are also in my least favorite time of the every 4 years, Election Season. But Election Season does tie nicely into our subject of the day. Statistics are nothing but POLLS! In election season they say things like, “Do you like this Candidate? Do you like this particular issue? Do you believe they kill puppies when people aren’t looking?”, and we get a break down of Yes, No, and Undecided.
Unfortunately we are also in my least favorite time of the every 4 years, Election Season. But Election Season does tie nicely into our subject of the day. Statistics are nothing but POLLS! In election season they say things like, “Do you like this Candidate? Do you like this particular issue? Do you believe they kill puppies when people aren’t looking?”, and we get a break down of Yes, No, and Undecided.In SQL Server Statistics are SQL’s way of Polling our Data.
GATHERING STATISTICS:
SQL Server: “I See you are a column Called First Name”
Registered Column: “Yes I am”
SQL Server: “Mind if I ask you a few questions (QUERIES) and create a Poll based off of how you answer?”
Registered Column: “Go Right Ahead”

Breaking New Folks Registered Column has 28% of his data between Alex and David, only 5% between David and Nick, and a WHOPPING 77% between Opie and Zachary!
USING STATISTICS:
Now the next time we ask a question (QUERY) we (THE QUERY OPIMIZER) have an expected number of people in a particular demographic (VALUE RANGE). We know if our candidate wants to know how all the Opie’s through Zachary’s will answer a question (QUERY), we can plan on how to best collect that information (AKA HOW THE QUERY OPTIMIZER CREATES A QUERY PLAN). We can then figure out how many people we need to send out (WORK THAT NEEDS TO BE DONE SORT, SPOOLS, HASH’s) in order to collect that data. For example we need less people to collect data from David to Nick (NESTED LOOP JOIN) than we do to collect data from Opie to Zachary (HASH JOIN).
OUT OF DATE STATISTICS:
Now that we have our Poll, the next time we have a question (QUERY), the folks on the new screen will say, our expected result was 77% when we selected the range of Opie’s and Zachary’s however we found that only 58% actually resided there.
Our population was moving (DATA WAS BEING UPDATED/INSERTED/DELETED) and our Statistics were not up to date. If we had a plan to collect our data (QUERY PLAN) using a lot of people to go out in the community and collect polls we may have sent out to many and over allocated our resources (PICKED A BAD PLAN IE HASH JOIN INSTEAD OF NESTED LOOP). If we still had 77% of Opie’s to Zachary’s our polling plan (ESTIMATED ROWS RETURNED)
would be good, but it wasn’t (ACTUAL ROWS RETURNED).
UPDATING STATITICS:
So our Statistics were out of wack on our poll. Something was off. If we had a big plant closure in our town or a big company laid off a lot of people (PURGE PROCESS ON A TABLE), then we would expect some population shift. If we knew 20% of people (20% OF ROWS IN A TABLE) were going to be laid off we could expect some would move in with other family members or move to find new work. We would probably send people out in the community to get new polls (AUTO UPDATE STATITICS) and find out what the new data was for. We found 58% Alex and David, 25% between David and Nick, and 17% between Opie and Zachary
Regeneration of Statistics causes us to re-think our plan to Poll Opie’s to Zachary’s (QUERY RECOMPLIATION TO GET A NEW QUERY PLAN) in order to send the right amount of people out to ask questions (QUERY) to get our candidate some information (GET OUR DATA). Now we see that we need much less people (NESTED LOOP JOIN) to poll Opie thru Zachary than we previously did (MERGE JOIN) and our polling plan (QUERY PLAN) reflects that.
GETTING INTERNAL
 |
| http://www.flickr.com/photos/photo645a/3995665841/ |
Now that we have a general idea of how things work let’s spell it out a purely in SQL Server Language. Clustered Indexes and Non Clustered Indexes automatically have statistics generated for their key columns. However there are more columns in a table than just indexed columns.
SQL places those Statistics in an object named a Histogram. A Histogram contains entries (will only ever have a max of 200) that show data values spread over a range. This allows the Query Optimizer when constructing a plan to say, “Statistics, I’m going to run this query on this table how many rows can I expect to get back?” and then plan accordingly.
We have the following table named Students with columns StudentID, SSN, FirstName, LastName, MiddileIntial, BirthDate, and Gender. Clustered Index on StudentID (no debate in indexes right now this is just a demo J).
*All of the code to create a Students table along with other and generate random data was uploaded to my resources page yesterday as a part of my Trimming Indexes Getting Your Database In Shape presentation. Download that code and play around with it however you like!
create table students(
studentID int identity(100000,1)
,ssn char(9)
,FirstName varchar(50)
,MiddileInitial char(1)
,LastName varchar(100)
,BirthDate datetime
,Gender char(1)
,constraint pk_students_studentID primarykey clustered (studentID)
)
If we insert a couple rows into this table (*go get the code!) and then go look at SSMS.

We see that we have statistics created for my primary key. If you right click on the Statistics and open them up and then click on Details you will see a whole host of information. You can see when the statistics were generated, when they were last updated and what the range is.
You can see that my Average Length is 4. That is because my Primary Key on column StudentID is an INT or a 4 byte fixed length value. You can see in my range what my RANGE_HI_KEY is to my RANGE_ROWS.
For my 200 different samples you can see how many rows fall in that data DISTINCT RANGE ROWS.
If I said to the Query Optimizer
SELECT
studentid
FROM
dbo.students
WHERE
studentid between104030 and 108969
I would expect to get back 4940 rows, BUT my statistics are OUT OF DATE and do not refelect that. So when I execute my query, and include actual execution plan, this is what I get back.
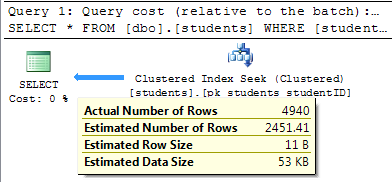
My options at this point are to update my statistics.
UPDATE STATISTICS dbo.students pk_students_studentIDWITH FULLSCAN
And now my query plan looks like this.
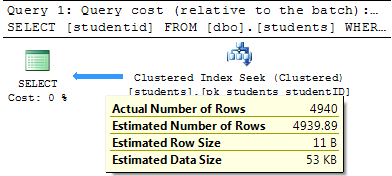
As you can see the Optimizer expected the number of results it got back. In my Query Plan (a simple trivial one), the statistics did not shift my outcome. But had I joined on the Courses table or the Grades table it could have completely changed my plan.
TWITTER IT UP

So the question on twitter yesterday that spawned all of this was should I delete old statistics? My answer to that is no. You should update them. The Histogram is not normally a big space consuming object. They are not like unused Indexes. Unused indexes occur IO, they must be maintained as the base structure is updated. This costs your system. Statistics just off the query optimizer a path, if the statistics are old and the range is still valid leave them be.
Whenever a query comes along you will save the optimizer the trouble of regenerating them. Because if they are not there we have to create them, but that is an example for another day.
As always Thanks for stopping by!
Thanks,
Brad
