

Most of us are aware of Statistics in SQL Server and its purpose. But still, just to get started, statistics store information on the distribution of data in a column(s), which helps the query optimizer pick the right query plans. Effectively, it helps to answer questions like "how many rows with value 25 on column "Age" or how many more than 15 etc..
This post will get little in depth on how statistics are actually stored in the database. Statistics are actually stored as "histograms" ( https://en.wikipedia.org/wiki/Histogram). One may take a look at histogram used in statistics by expanding a commonly queried table in your database, expand statistics -> properties -> Click on "Details" tab.

This post will get little in depth on how statistics are actually stored in the database. Statistics are actually stored as "histograms" ( https://en.wikipedia.org/wiki/Histogram). One may take a look at histogram used in statistics by expanding a commonly queried table in your database, expand statistics -> properties -> Click on "Details" tab.
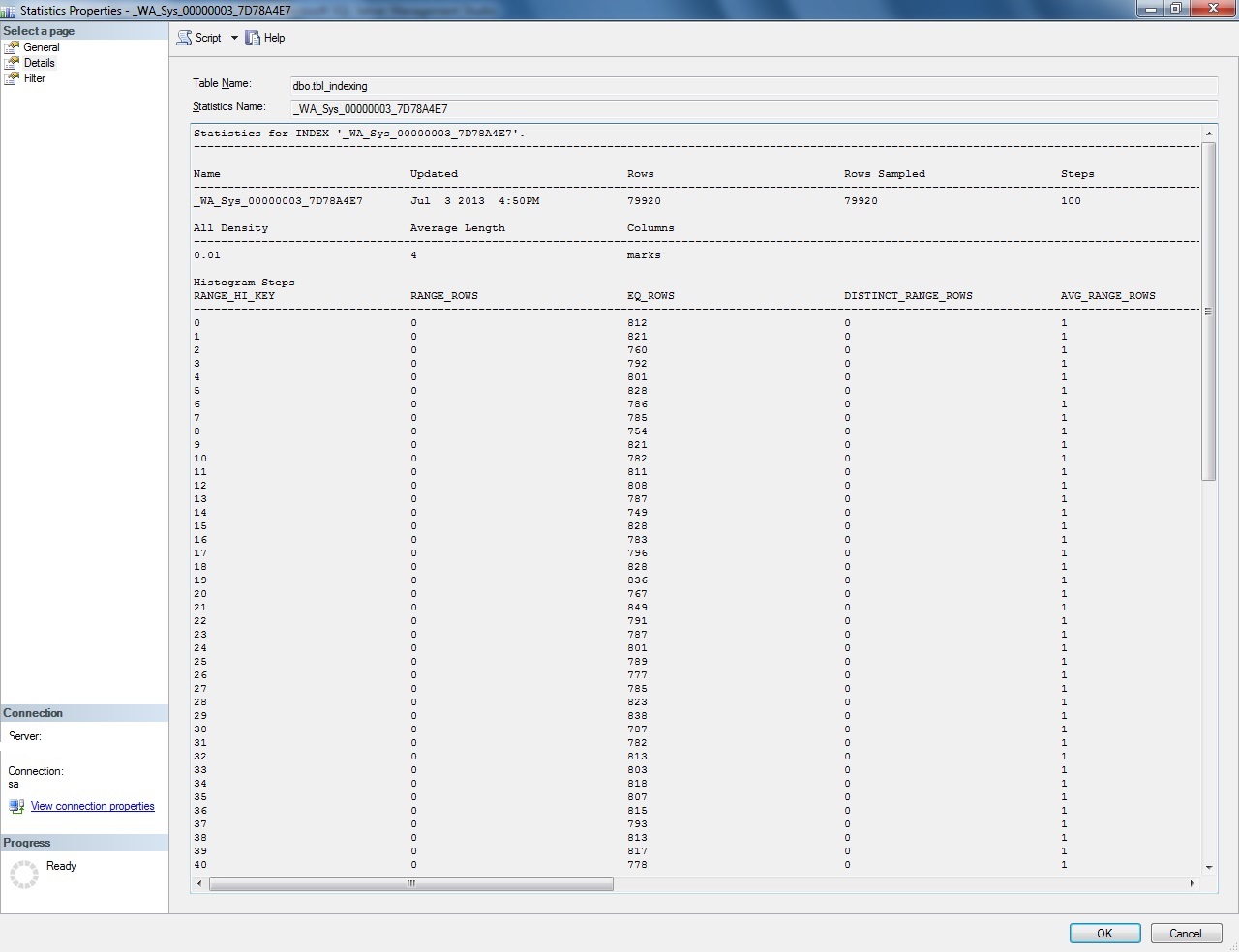
Interesting part of the image above is the histogram steps. One would notice that histogram steps contain entries for selected values in the column. Basically what histogram steps intend to convey is the number of rows that exist for a particular or range of values.
For example, for a column containing
marks, it attempts to say
0 - 10 there are 15 rows
10 - 30 - there are 45 rows
50 - 80 - there are 60 rows
80 - 100 - there are 20 rows and so on..
Observe RANGE_HI_KEY column. It indicates the highest value in the range. Each row represents the range starting from the ending of previous row ( Previous row RANGE HI KEY value ) to the value in RANGE_HIGH_KEY. For example the second row "" indicates distribution between x to y
- RANGE_ROWS Column indicate the total number of rows in the range ( Previous hi key to current hi key )
- DISTINCT_RANGE_ROWS indicate how many among them are distinct
- AVG_RANGE_ROWS indicate the average row returned per distinct value
- EQ_ROWS indicate total the number of rows for the range hi key value alone.
The most important part is number of steps in the histogram are fixed to 200. Meaning the histogram will have maximum of 200 entries / rows irrespective of number of rows the table. Even if there are 1 million rows, 200 entries will describe the column's data distribution.
So, why this post on statistics? 🙂 Armed with this knowledge, let us dive into deeper concepts like cardinality estimator and how it has changed in SQL 2014 in upcoming posts.
?
![]()
