In our daily life, we use the statistics to take the decision. In the same way SQL server optimizer use the statistics to choose the right query plan. if the statistics are wrong or outdated , SQL server might choose a wrong query plan. In this post, let us try to understand the different aspects of statistics.
The query optimizer use the statistics to determine the rows returned in each step.The estimated rows information in the execution plan is calculated based on the statistics available on the columns.The statistics gives the distribution of data with in the column.With out statistics, the query optimizer can not be determine the efficiency of different plan.By using the information stored in the statistics , the query optimizer can make right choice in accessing the data.
Statistics are created automatically when we define the indexes.Apart from this statistics are getting created when a column is referenced in a query as part of where condition, in the group by clause or join criteria. To happen the auto creation of statistics, the AUTO_CREATE_STATISTICS setting in database level should be enabled. By default this setting is enabled.Apart from these , statistics can be created using the CREATE STATISTICS command.
Every statistics in SQL server stores information about density vector and Histogram (data distribution). Let us try to understand both before we discuss more about statistics.
Density:Density is the ratio of unique values with in the given column or a set of columns.
The formula to calculate density is : 1/Number of distinct values for a column or set of column
Density measure the uniqueness of column or selectivity of column.Density can have value between 0 and 1. If the column has density value 1, it means all the records has same value in that column and less selectivity. Higher the density lower the selectivity. If the column has density value 0.003, that means there are 1/0.003=333 distinct values in that column.
Let us consider a sample. I am going to create a table with two indexes using the below script.
USE mydb
GO
SELECT * INTO SalesOrderDetail FROM AdventureWorks2008.Sales.SalesOrderDetail
CREATE UNIQUE CLUSTERED INDEX ix_SalesOrderDetailID ON SalesOrderDetail(SalesOrderDetailID)
CREATE NONCLUSTERED INDEX ix_productid ON SalesOrderDetail(productid)
Let us see how the statistics will looks like for these two indexes. The below command will show the details of statistics associated with the clustered index Ix_SalesOrderDetailID.
DBCC SHOW_STATISTICS('dbo.SalesOrderDetail', 'ix_SalesOrderDetailID')
The output will have three sections: statistics header,density vector and Histogram. Let us concentrate only on the first two sections.
In the first section (Statistics header)
- Name : The name of the index
- Updated : Tells the date and time of last statistics update
- Rows: The number of rows in the index.This is the number of rows in the indexes not in the table(in case of filtered index)
- Rows Sampled: The number of entries that were sampled to generate the statistics. While creating an index , it will go for a full scan.
- Steps: The number of steps in the histogram (the third section . we will discuss it later)
- Density : This value is not used in SQL server 2008 and exists for backward compatibility
- Average Key Length : The average length of index key
- String Index: The statistics include string summery statistics or not string summery statistics is the Information about the frequency distribution of substrings is maintained for character columns. This helps the optimizer better estimate the selectivity of conditions that use the LIKE operator.
- Filter Expression: The expression used to create filtered index
- Unfiltered Rows: The number of rows in the underlying table.If it is filtered index , the value of this column will be greater than the value in the Rows column.
We can get information only about header using 'WITH STAT_HEADER' along with DBCC SHOW_STATISTICS
In the next section, density vector, we have only one record as we have one column in our index.
All Density column gives the density value of the column SalesOrderDetailsId (1/Number of distinct values for a column or set of column). The All density column show the value 8.242868E-06 = 0.000008242868. That means the column SalesOrderDetailsId has 1/0.000008242868 =121317 unique values.This value is equivalent to
SELECT COUNT(DISTINCT SalesOrderDetailID ) FROM SalesOrderDetail
We can get information only about density vector using 'WITH DENSITY_VECTOR' along with DBCC SHOW_STATISTICS.
Let us see the density vector of the non clustered index ix_productid
DBCC SHOW_STATISTICS('dbo.SalesOrderDetail', 'ix_productid') WITH DENSITY_VECTOR
You can see two rows in the density vector even if the the non clustered index is on single column. This is because the clustered index key is part of non clustered index (Read More). The first row says, the density value of the column ProductID is 0.003759399. In other words there are 1/0.003759399 =266 distinct values in the productID column.The output of the below query proves that is true.
SELECT COUNT(DISTINCT ProductID) FROM dbo.SalesOrderDetail
The second row says, the density of the combination of the columns ProductID and SalesOrderDetailID is 0.000008242868. In other words there are 121317 distinct combination of ProductID and SalesOrderDetailID which is equivalent to the total number of records in the table.
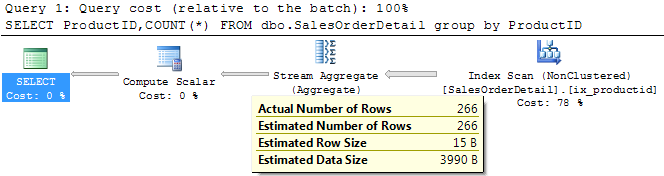
Where is density value is used ? Let us look into the execution plan of the below query.
SELECT ProductID,COUNT(*) FROM dbo.SalesOrderDetail GROUP BY ProductID
If you look into the execution plan, in the output of aggregate operator , the estimated number of rows value is 266. It is nothing but the distinct values available in the ProductID column which can be easily calculated from the density vector. But how we can prove that query optimizer use this value to calculate the estimated number of rows? Let us create another copy of this table with out any indexes and statistics.
USE mydb
GO
SELECT * INTO SalesOrderDetail_NoStats FROM SalesOrderDetail
The output of the below query tells us there is no statistics associated with this table.
EXEC SP_HELPSTATS 'SalesOrderDetail_NoStats', 'ALL'
Let us see estimated execution plan of the grouping query on this new table.
SELECT ProductID,COUNT(*) FROM dbo.SalesOrderDetail_NoStats GROUP BY ProductID
Again the optimizer estimated 266 rows in the output of the aggregate operator with out having any index or statistics. Let us again check the statistics associated with this table.
EXEC SP_HELPSTATS 'SalesOrderDetail_NoStats', 'ALL'

Yes, while estimating the plan , SQL server created a statistics on the productID column to help optimizer to choose the right execution plan. Let us see the details of this statistics.
DBCC SHOW_STATISTICS('dbo.SalesOrderDetail_NoStats', '_WA_Sys_00000005_32E0915F')
In the header section, you can notice that the value in the Rows Sampled is less than the value of the Rows. This is because SQL server will not scan the entire table instead it will use only a sample of the table while creating auto statistics.We will discuss about the sampling in detail in the later post. In short on a non indexed fields, the statistics help the optimizer to determine estimated number of record in each operation,what kind of join is appropriate and the order of the processing in the plan.
Let us stop this post here and will discuss about the histogram in the next post.
If you liked this post, do like my page on FaceBook