

There were a stack of errors overnight in the DB123 database on SQL01, including one horror show error:
--
Log Name: Application
Source: MSSQLSERVER
Date: 5/24/2018 12:49:39 AM
Event ID: 3314
Task Category: Server
Level: Error
Keywords: Classic
User: N/A
Computer: SQL01.client99.com
Description:
During undoing of a logged operation in database 'DB123', an error occurred at log record ID (195237:96178:4). Typically, the specific failure is logged previously as an error in the Windows Event Log service. Restore the database or file from a backup, or repair the database.
--
|

The catch is that when I checked the server, the database was online.
Say what?
--
It started with the LOG drive filling generating a long string of 9002’s:
--
Log Name: Application
Source: MSSQLSERVER
Date: 5/24/2018 12:49:39 AM
Event ID: 9002
Task Category: Server
Level: Error
Keywords: Classic
User: N/A
Computer: SQL01.client99.com
Description:
The transaction log for database 'DB123' is full due to 'ACTIVE_TRANSACTION'.
--
Followed by a “crash” including the horror show error:
--
Log Name: Application
Source: MSSQLSERVER
Date: 5/24/2018 12:49:39 AM
Event ID: 9001
Task Category: Server
Level: Error
Keywords: Classic
User: N/A
Computer: SQL01.client99.com
Description:
The log for database 'DB123' is not available. Check the event log for related error messages. Resolve any errors and restart the database.
--
Log Name: Application
Source: MSSQLSERVER
Date: 5/24/2018 12:49:39 AM
Event ID: 3314
Task Category: Server
Level: Error
Keywords: Classic
User: N/A
Computer: SQL01.client99.com
Description:
During undoing of a logged operation in database 'DB123', an error occurred at log record ID (195237:96178:4). Typically, the specific failure is logged previously as an error in the Windows Event Log service. Restore the database or file from a backup, or repair the database.
--
…which seems scary, but then the database seemed to magically recover on its own:
--
Log Name: Application
Source: MSSQLSERVER
Date: 5/24/2018 12:49:41 AM
Event ID: 17137
Task Category: Server
Level: Information
Keywords: Classic
User: N/A
Computer: SQL01.client99.com
Description:
Starting up database 'DB123'.
--
Log Name: Application
Source: MSSQLSERVER
Date: 5/24/2018 12:49:45 AM
Event ID: 3450
Task Category: Server
Level: Information
Keywords: Classic
User: N/A
Computer: SQL01.client99.com
Description:
Recovery of database 'DB123' (5) is 0%% complete (approximately 4502 seconds remain). Phase 1 of 3. This is an informational message only. No user action is required.
--
There was a huge string of Error 18456 (login failures) since DB123 was unavailable during regular recovery, followed eventually by:
--
Log Name: Application
Source: MSSQLSERVER
Date: 5/24/2018 1:08:12 AM
Event ID: 3421
Task Category: Server
Level: Information
Keywords: Classic
User: N/A
Computer: SQL01.client99.com
Description:
Recovery completed for database DB123 (database ID 5) in 1107 second(s) (analysis 52027 ms, redo 238039 ms, undo 700990 ms.) This is an informational message only. No user action is required.
--
…and all was well.
 |
| http://www.thingsmadefromletters.com/wp-content/uploads/2013/10/whut-i-dont-understand-this.jpg |
I went looking for similar situations and found this:
In this situation the drive filled and the database crashed, going through recovery once there was additional free space on the drive, which sounded exactly like the situation here.
In short, there was no actual corruption crash, just insufficient disk space.
--
Using the default trace query described here, I checked for autogrowths, and here was what they looked like:
EventName | DatabaseName | FileName | ApplicationName | HostName | LoginName | Duration | TextData |
Log File Auto Grow | DB123 | DB123_log | .Net SqlClient Data Provider | WEB05 | WebLogin01 | 1013000 | NULL |
Log File Auto Grow | DB123 | DB123_log | .Net SqlClient Data Provider | WEB05 | WebLogin01 | 920000 | NULL |
Log File Auto Grow | DB123 | DB123_log | .Net SqlClient Data Provider | WEB05 | WebLogin01 | 873000 | NULL |
Log File Auto Grow | DB123 | DB123_log | .Net SqlClient Data Provider | WEB05 | WebLogin01 | 1083000 | NULL |
Log File Auto Grow | DB123 | DB123_log | .Net SqlClient Data Provider | WEB05 | WebLogin01 | 646000 | NULL |
Log File Auto Grow | DB123 | DB123_log | Ivanti | WEB05 | WebLogin01 | 903000 | NULL |
Log File Auto Grow | DB123 | DB123_log | .Net SqlClient Data Provider | WEB05 | WebLogin01 | 880000 | NULL |
Log File Auto Grow | DB123 | DB123_log | .Net SqlClient Data Provider | WEB05 | WebLogin01 | 846000 | NULL |
Log File Auto Grow | DB123 | DB123_log | .Net SqlClient Data Provider | WEB05 | WebLogin01 | 1176000 | NULL |
Log File Auto Grow | DB123 | DB123_log | .Net SqlClient Data Provider | WEB05 | WebLogin01 | 846000 | NULL |
Log File Auto Grow | DB123 | DB123_log | .Net SqlClient Data Provider | WEB05 | WebLogin01 | 1416000 | NULL |
Since the TEXTDATA is NULL I can’t say what process caused the growths for sure, but they started at 12:22am local server time.
I could tell the client that since they came from the .NET provider they aren’t caused by Index/Statistics maintenance or anything else internal.
--
To try to run down what might be causing the autogrowths I set up an Extended Events session to capture statement completion events (rpc_completed, sp_statement_completed, and sql_batchcompleted) to see what was actually running during the time slice. Sure enough there was a smoking gun:
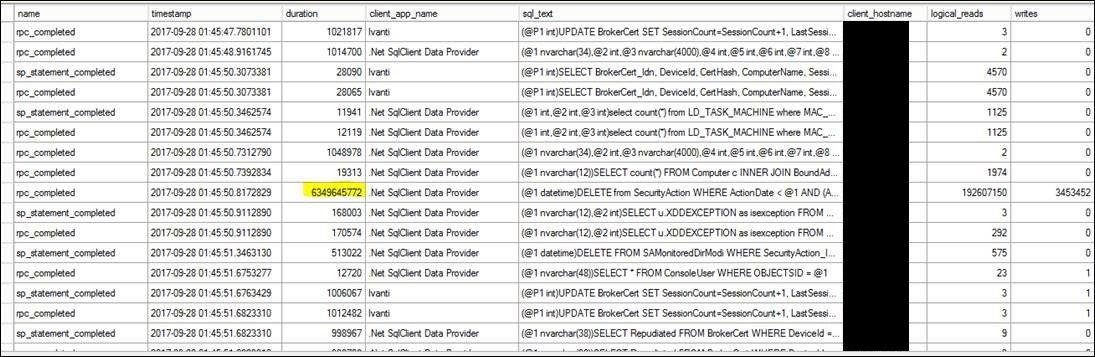
Check out the row near the middle with a very large duration, logical_reads count, *and* writes count.
 |
| https://steemitimages.com/DQmarWgB1ztrx628DTGpkteJeKiU3waad9YRtm5jVedJxws/problem.jpg |
Durations in SQL 2012 Extended Events are in microseconds – a very small unit.
The catch is the duration for this statement is 6,349,645,772 (6 billion) microseconds…105.83 minutes!
--
The DB123 database is in SIMPLE recovery (note - when I find this I question it – isn’t point-in-time recovery important? – but that is another discussion). The relevance here is that in SIMPLE recovery, LOG backups are irrelevant (and actually *can’t* be run) – once a transaction or batch completes the LDF/LOG file space is marked available for re-use, meaning that *usually* the LDF file doesn’t grow very large. (usually!)
A database in SIMPLE recovery growing large LDF/LOG files almost always mean a long-running unit of work or accidentally open transactions (a BEGIN TRAN with no subsequent CLOSE TRAN) – looking at the errors in the SQL Error Log last night, the 9002 log file full errors stopped at 1:45:51am server time, which means the offending unit of work ended then one way or another (crash or success).
Sure enough when I filtered the XEvents event file to things with a duration > 100 microseconds and then scanned down to 1:45:00 I quickly saw the row shown above. Note this doesn’t mean the unit of work was excessively large in CPU/RAM/IO/etc. (and in fact the query errored out due to lack of LOG space) but the excessive duration made all of the tiny units of work over the previous 105 minutes have to persist in the transaction LDF/LOG file until this unit of work completed, preventing all of the LOG from that time to be marked for re-use until this statement ended.
--
The query in question is this:
--
exec sp_executesql N'DELETE from SecurityAction
WHERE ActionDate < @1 AND
(ActionCode != 102 AND ActionCode != 103 AND ActionCode != 129
AND ActionCode != 130)',N'@1 datetime',@1='2017-09-14 00:00:00'
--
Stripping off the sp_executesql wrapper and the parameter replacement turns it into this:
--
DELETE from SecurityAction
WHERE ActionDate < '2017-09-14 00:00:00'
AND
(
ActionCode != 102
AND ActionCode != 103
AND ActionCode != 129
AND ActionCode != 130
)
--
Checking out DB123.dbo.SecurityAction, the table is 13GB with 14 million rows. Looking at a random TOP 1000 rows I see rows that would satisfy this query that are at least 7 months old (from February 2017) and there may be even older rows – I didn’t want to spend the resources to run an ORDER BY query to find the absolute oldest. I don’t know if this means this individual statement has been failing for a long time or maybe this DELETE statement is a recent addition to the overnight processes and has been failing since then.
The DELETE looks like it must be a scheduled/regular operation from a .NET application running on WEB05 since we are seeing it each night in a similar time window.
The immediate term action they chose was to run a batched DELETE to purge this table down – once it has been purged down maybe the nightly operation will run with a short enough duration to not break the universe.
I told them it should be able to be handled with a TOP DELETE something like this:
--
WHILE 1=1
BEGIN
DELETE TOP (10000) from SecurityAction
WHERE ActionDate < '2017-09-14 00:00:00'
AND
(
ActionCode != 102
AND ActionCode != 103
AND ActionCode != 129
AND ActionCode != 130
)
END
--
This would DELETE rows in 10,000 row batches; wrapping it in the WHILE 1=1 allows the batch to run over and over without ending. Once there are no more rows to satisfy the criteria the query *WILL CONTINUE TO RUN* but will simply delete -0- rows each time, and then when the user is ready to stop the batch they simply cancel it.
You could write a WHILE clause that actually checks for the existence of rows that meet the criteria, but in this case there were so many rows that meet the criteria that running the check itself is more intensive than simply allowing the DELETE to run over and over.
It took several hours of running the "batched" loop, but eventually the table got down from 14 million rows to 900,000 rows without growing the LDF file past 2GB!
 |
| https://memegenerator.net/img/instances/80336841/booyah.jpg |
--
Lesson #1 - don't run giant deletes without considering the impact.
Lesson #2 (and maybe the more important) - "horror show" errors aren't always a horror show - always investigate fully!
--
Hope this helps!
