

I was discussing Cardinality Estimation with a colleague recently and the question came up, what cardinality does SQL Server use if you’re selecting from a column where there are no statistics available? I’ve discovered there are a few algorithms in play depending on how you’re querying the table. In this post we’ll look at where we have a predicate looking for a fixed value.
(If you want the short answer, it’s the fourth root of n cubed before SQL 2014 and the square root of n after that.)
This scenario can occur if you have AUTO CREATE STATISTICS turned off for your database, which we don’t recommend you do, but which you might choose to do anyway, and if you query a table with a predicate against a column with no index defined against it.
Let’s look at example. I’m using SQL Server 2012 for this investigation, and to start with am querying the AdventureWorks2012 database.
I’ve taken the following preparatory steps:
- Set AUTO CREATE STATISTICS OFF for the database
- Remove the Index on the LastName column for the Person.Person table
- Removed any ad-hoc statistics that existed against the table
Then I run a simple query, with the Actual Execution Plan turned on:
SELECT * FROM Person.Person p WHERE p.LastName = 'Fox';
I only get one result out as there is only one Fox (Ms. Dorothy J.). Let’s look at the execution plan:

A clustered index scan as we might expect as I’ve removed any useful indexes from the table. You’ll notice there is a warning. If we view the tooltip you’ll see SQL warns us about the lack of statistics:
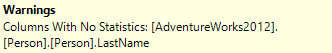
If we look at the estimated and actual row-counts we’ll see how that has affected us:
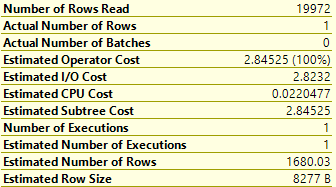
In the absence of any useful information – it knows the number of rows in the table but that is about it – SQL has estimated that there will be 1680 Foxes in the table. A bit of playing shows that we get the same estimate whatever value we search for.
If I turn AUTO CREATE STATISTICS on and run the query again then SQL generate a Statistics object against the LastName column and comes up with an estimate of 2.3 rows – which is a lot closer.
This matters a lot once you start running more complicated queries. The incorrect estimate is likely to affect the choice of plan that the optimizer makes, and may also affect the amount of memory it requests in order to run the query. Let’s look at a quick example of how the plan changes if we join the above query to another table.
First, without statistics (so I have to turn AUTO CREATE off again, and remove the statistics that got created):
SET STATISTICS IO ON; SELECT e.EmailAddress FROM Person.Person p INNER JOIN Person.EmailAddress e ON p.BusinessEntityID = e.BusinessEntityID WHERE LastName = 'Fox';
Here’s the execution plan:
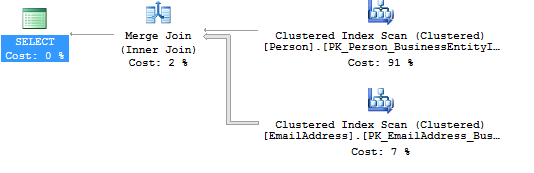
You can see I’ve got a Merge Join as SQL thinks I’m expecting 1680 rows from the top table. A Nested Loops join would generally be better when I only expect one or two rows from that table.
I’ve also captured the IO so I can see how expensive the query was:
Table ‘EmailAddress’. Scan count 1, logical reads 10, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Person’. Scan count 1, logical reads 3818, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Let’s look at the behaviour of the same query with statistics creation enabled:
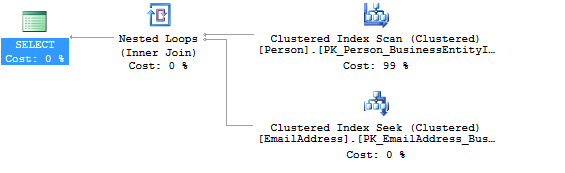
You can see we now have the desired Nested Loops join and the Clustered Index Scan on the EmailAddress table has been changed to a Seek.
The IO output is below:
Table ‘EmailAddress’. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table ‘Person’. Scan count 1, logical reads 3818, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
There’s not much difference in the overall IO, but you can see the Reads for the EmailAddress table have dropped from 10 to 2 due to the change from the Scan to the Seek. If the table was a lot bigger then we could see a large difference here.
So where does that estimate come from?
I thought I’d have a play and see if I could work out how SQL decided on that estimate of 1680 rows. I did some googling and found a suggestion that it might be a straight 9% of the total number of rows in the table, but that doesn’t quite add up and when I compared the same query pattern against a few tables I found I got a different ratio depending on the amount of rows in the table.
So I pumped rows incrementally into a fresh table and looked at the estimate and what the ratio was as the number of rows increased. Here’s my SQL for that:
--Create a Horrible Heap for my testing CREATE TABLE dbo.TestStats(TestVal INT NOT NULL, TestText VARCHAR(255) NULL); --Insert a bunch of rows using dodgy old-style cross joins INSERT INTO TestStats SELECT TOP 1 --Amount of rows I'm going to insert 1 , 'blah' FROM sys.objects a, sys.objects b, sys.objects c, sys.objects d, sys.objects e; --Clear the plan cache so SQL generated a new estimate DBCC freeproccache; --Query the table, then I go check the execution plan generated --for the estimated number of rows SELECT * FROM dbo.TestStats WHERE TestVal = 1;
(One thing to note was that I got the same answers whether I was querying the text column or the integer column – SQL seems to use the same algorithm for both.)
I started to notice a pattern quite quickly, that the ratio halved when the number of rows went up by a factor of 16. I then restarted my test, targeting my row-counts to be where the estimated number of rows would be a nice round number. You can see that in the table below:
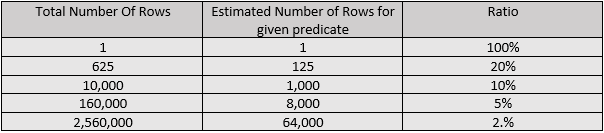
I then attempted to work out a formula for that. Rather than take you through the shoddy process of mathematics that led me to an answer, I’ll just tell you that the formula came out as:
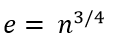
Where e is the estimated number of rows for a given predicate value, and n is the total number of rows in the table. I checked that against the full set of results I’d gathered and it held true across all values of n I’d tested.
To check it finally against my original query – the Person.Person table had 19,972 rows. I put that through the calculator with the formula and get 1680.027. If we look back at the original estimate you’ll see that SQL stated 1680.03 – so that is all good.
As I mentioned earlier I was using SQL Server 2012 for this test, and a new Cardinality Estimator came into effect in SQL 2014. So I thought I’d run the test again with SQL 2016 and see if the results changed:
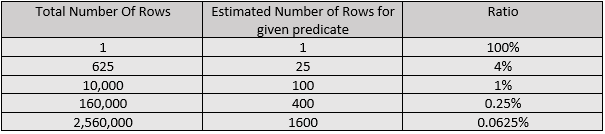
We can see the estimated rows drop off a lot quicker here. Clearly Microsoft have decided to lower the estimate. Actually it is now just the square root of the total number of rows.
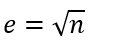
Hopefully you’re not in the scenario where you regularly have queries running without the appropriate statistics to support them. The above comparison though shows us that if you have such a query its behaviour could dramatically change if you upgrade your SQL Server version to 2104 or higher. It could become better or it could become a lot worse.
There are a lot of changes like this that came in with the new version of the Cardinality Estimator in 2014. Places where underlying assumptions have been adjusted to make better guesses about the number of rows that will be returned by an operator. But they are still guesses based on the same information – there is no new data being captured in the Statistics to better inform the process. Of course Microsoft has made these changes to try and better model data out in the wild – but they are still fixed assumptions, which means sometimes they will be better and sometimes they will be worse.
One thing I should re-iterate is that these formulae we’ve discovered above are for a fairly specific querying pattern. There’s no guarantee that the calculation will be the same for a similar – but different query. It might be interesting to explore that further in a later post.
Also there may be other information in your database – such as constraints – that SQL can use to educate its guesses.
The main takeaway from all of this though, should of course be:
MAKE SURE AUTO CREATE STATISTICS IS TURNED ON FOR YOUR DATABASES!

![]()
