

Introduction
I have long had a dislike of Entity-Attribute-Value models within RDBMS's based on my experience trouble-shooting and supporting them in various forms over my career. The premise of such a model is that they offer huge flexibility as objects that would usually require extensive physical modelling can be represented simply by records within a generic schema.
My experience is that the promised flexibility of such models is illusive and more than offset by the penalties and inconveniences they incur. With the rise of NOSQL solutions, native handling of XML within SQL Server and polyglot data solutions the limited number of appropriate use cases is dwindling still further.
I should like to achieve a couple of things with this article
- To outline where I think EAV models may still offer some benefit
- To give concrete reasons why I have such antipathy for them within RDBMS's
What is an Entity-Attribute-Value model?
These come in various levels of sophistication. At their simplest they may represent little more than a key-value pair with an additional field to denote the type of value being stored. At their most complex a fully fledged Entity-Attribute-Value/Class-Relational model will attempt to handle domain and referential integrity rules, business data rules such as optionality and cardinality and other metadata.
In other words after a lot of programming effort they mimic the facilities that come out-of-the-box when using an RDBMS in normal relational form.
In his article "When the fever over, and one's work is done" Phil Factor described his EAV implementation as resembling the SQL Server system tables and that has certainly been my experience.
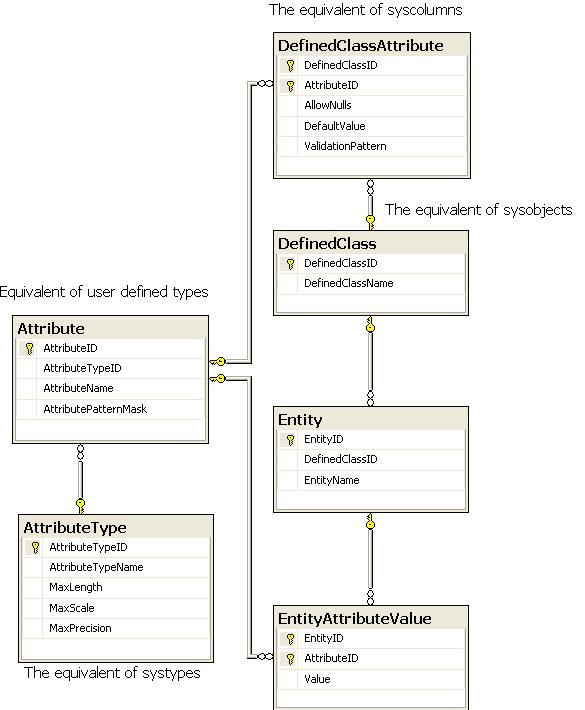
The overarching idea is that rather than have a complex physical data model to represent objects what you have is a much simpler physical model but the rules and structure of the objects are held in metadata.
Let us suppose that you are in the business of selling shirts. As an oversimplification your product table may look something like the following example:-
| Field name | Data Type | Description |
|---|---|---|
| ProductID | BIGINT | Primary and surrogate key for the product |
| ProductSKU | VARCHAR(15) | Unique business key for the product |
| ProductName | VARCHAR(50) | Short friendly name for the product |
| SizeID | SMALLINT | Refers to the ProductSize table |
| ProductDescription | VARCHAR(MAX) | Full marketing description of the product. |
| ProductPrice | DECIMAL(6,2) | The selling price of the product. |
In an EAV model a particular product would be the entity, the fields would be the attributes and the field values would be as presented.
Where are Entity-Attribute-Value models appropriate?
Although this article will provide details of a number of failings of EAV models it is worth remembering that such models came into being as a solution for a particular set of use cases.
- A large number of data classes with very little in common in terms of their attributes.
- A small number of attributes per object.
- Fluid business requirements or difficulty pinning down data requirements making traditional data modelling difficult or impractical.
- Rate of change within an entity is low being limited to inserts and deletes.
- Interaction with objects in the model is largely at the entity level, that is the entire entity is retrieved, little if any filtering is performed at the attribute level.
- The priority is to get the IT facility to deliver business value to market at the earliest opportunity and refactor the database as soon as business value has been demonstrated. There are two implicit requirements in the preceding statement.
- The business supports and actively embraces the need for refactoring inefficient code.
- The business genuinely needs rapid change.
- Downstream processing of data within the model can be achieved in a timely fashion to support dependent business processes.
- Where there is limited customer interaction and a very tightly defined data use case for data within the model.
I would expect a minimum of two of these use cases to be operating in conjunction. The examples below outline some uses for the EAV models.
Application Configuration Settings
Think of these as a centrally stored equivalent of the .NET web.config or app.config files.
- Entity = Setting name
- Attribute = Setting type to define the domain integrity of the value.
- Value = The setting itself
It may be that a centralised store keeps the configuration to a simple key value pair arrangement. The use of an attribute to define data type is simply a metadata entry to act as an aide memoir for the developer when populating the various settings.
Typically the data in a centralised database settings store has a very strict and simple mechanical access pattern. The majority of data changes, additions or deletions will occur when software is released and therefore any problems will be thrashed out during normal software testing.
A couple of stored procedures that demonstrate this within SQL Server are sp_configure and sp_dboption.
Surveys and questionnaires
Modelling a questionnaire/survey system within an RDBMS would be difficult to support without an EAV model. The characteristics that make this use case a good fit for an EAV model are as follows:-
- Every survey is specific for its intended purpose with little commonality between them in terms of their questions
- A survey is likely to be short, that is to have few questions.
- Surveys are principally data collection mechanisms with result interpretation and analysis being carried out as an offline process.
So what we have is:
- A entity is an instance of a survey
- An attribute represents a question
- A value represents an answer
Product review systems
Let us suppose that you have a product range where the products themselves have a wide variety of attributes. Each category of product can be given a star rating on a number of facets.
In this case the text body of a review can be held in a traditional data model but the various star ratings for a particular product can be held in an EAV model. This hybrid usage demonstrates that, as with all things database related, it is not a case of EAV always being wrong and relational modelling always being right.
The characteristics that make a star rating system suitable for EAV modelling are as follows:-
- Commonality of reviews can be built into a physical relational model
- The scoring attributes can be highly specific to a product category
- Traffic volumes in reviews systems tends to be low
- Data changes are limited to inserts or deletes. Deletes being either for reasons of obsolescence or moderation.
- Review scores limited to a simple scale therefore data validation can be represented as simple rules.
Product catalogue systems
It is in this area that I feel that the inclusion of native XML handling and the emergence of NOSQL key-document stores has rendered EAV models obsolete.
I have worked on a number of web based shopping cart products that handled products using a hybrid relational/EAV design. The idea was that all products have a large number of common attributes irrespective of business. Where a particular business demanded a specific set of attributes these were handled by the EAV model.
This worked well as the attributes within the EAV model were generally "information only" attributes. The customer could not filter or sort by these attributes and in the majority of cases they wouldn't have wanted to in any case. In truth the additional attributes were mainly to provide a means of providing structured content for product characteristics that the marketing department wished to draw attention to.
Prototype systems
These systems are the equivalent of concept cars in a national motor show. They are designed to present a favourable view of a prototype system in order to gain funding or project sponsortship for the real thing. In my experience prototype systems using such models are demonstrated by technical sales personnel to demonstrate a well-rehearsed product demonstration path. The most joyous of happy paths.
Just as a Ford Focus trimmed with humming bird feathers and frameless doors is unlikely to survive the harsh realities of production environments so the EAV model is only useful to gauge the reaction of intended customers.
As a tool to thrash out customer requirements the EAV model can be extremely useful.
The weaknesses of Entity-Attribute-Value designs
My personal antipathy towards EAV models is that to reach the point where it supports the facilities that are present in traditional relational models the amount of work involved is so high that it hasn't actually saved any time or money. The complexity of the metadata required to support the model is such that it is never likely to do so either.
The following points outline my specific concerns
Data quality
If the Entity-Attribute-Value model is to be truly generic then that means that the "value" field has to be generic and untyped which usually means it has to be some form of string or variant.
Whereas a traditional database design will use strongly typed fields so only data that complies with those strong types may be entered into those fields.
- Only dates can be entered into a DATETIME field
- Only integers can be entered into an integer field.
This is implicit in the use of these types and the rules cannot be violated.
This protection can only exist with explicit additional coding within the EAV model.
Of course one solution may be to have separate EAV tables for each datatype. This is fine if you are using a small number of data types but the more rigorous your data quality requirements the more unwieldy this becomes. It rapidly reaches the stage where you have to know the type of data in order to know i which table it will reside.
Domain integrity
In addition to the domain integrity implicit in the data type an RDBMS can enforce other data quality rules by means of CHECK constraints and UNIQUE constraints.
For example, DateOfBirth field may be protected from having future dates entered into it.
CHECK(DateOfBirth<CURRENT_TIMESTAMP)
An email address can enforce the need for an @ symbol followed by a dot at some point in the string.
An integer field may have a permissible range of values. A decimal value may have a specific number of decimal places.
Again, such enforcement would require explicit additional coding external to the EAV model.
The risk of not doing so is that a value that is expected to be a numeric is persisted in form that cannot be interpreted as a numeric value.
A requirement for uniqueness can be particularly challenging where a traditional unique constraint would cover two or more fields as this now requires two or more records to work in conjunction with each other.
Data referential integrity
One of the key strengths of an RDBMS is in the enforcement of foreign keys. Where a foreign key is active it is impossible to enter an invalid value in a field that references a foreign key.
Again, where it is possible, such enforcement would require explicit coding with the EAV model. This level of sophistication is complex and the effort required to do so should not be underestimated. This is where a full blown EAV/CR (Entity-Attribute-Value/Class-Relational) implementation becomes necessary.
Sorting of data
Data in an EAV model is implicitly a string or untyped value. Where the sort criteria is for a numeric value then there is a requirement for casting the value to the desired type or storing the value is a specific way to support string sorting.
To give an example why this is necessary consider sorting the values 1,3,5,7,9 & 11.
As strings, the sort would result in 1, 11, 3,5,7 & 9
You could choose to avoid casting values and storing numbers in zero-padded format (01, 03, 05, 07,09,11) but this means you now have a mix of presentation and content. In addition you would have to consider what to do if requirements change. What happens if the number of decimal places or positions to the left of the decimal place change? Do you have to recode all your values?
Filtering data
If data within the EAV model is required to participate in filtering then the retrieval of the appropriate dataset becomes exponentially complex with the addition of terms.
Consider retrieving red XL shirts. The retrieval would require first that all products with the following attribute values be retrieved.
- Colour attribute=red
- Product type attribute = shirt
- Size attribute = xl
Any product where the number of qualifying attributes = 3 would then be retrieved (with all relevant attributes)
To illustrate the complexity imagine that we now wish to retrieve blue blouses size 16. We can no-longer count on merely choosing the qualifying attributes and ensuring that there are 3 for every product. Doing so would result in blue shirts, red XL blouses.
One option is to use an external search engine and populate it with data from the EAV model. Depending on the frequency of data change and the search index population schedule this may be a workable option but the following points must be borne in mind:-
- Duplication of data as data resides in both the database and the search engine
- Time disconnects between data changes in the EAV model and their appearance in the search engine. It can be extremely offputting for the customer to see a product in their search results only to receive a message informing them that the product is expired or out of stock.
- Increased compute resource consumption during population. Heavy reads on the data in the EAV model plus heavy CPU utilisation when generating the search index.
Data types
A 1 byte unsigned integer can hold the values 0-255.
An EAV model holds such a value as a string. Within SQL Server this would be a VARCHAR or NVARCHAR data type.
- Values greater than 99 would require 3 bytes for the data alone.
- The VARCHAR/NVARCHAR data types have a storage overhead because they also have a pointer to indicate when the end of their variable length characters end.
DATETIME datatypes hold data down to the millisecond for a cost of 8 bytes.
2011-07-24T11:23:00.392 = 23 bytes (plus the varchar overhead).
Record Structure
In the example of red xl shirts a traditional table design would be as follows
Field | Datatype | Comment |
|---|---|---|
ProductID | INTEGER NOT NULL | Primary key |
ProductName | VARCHAR(50) NOT NULL | |
Size | CHAR(2) NOT NULL | |
Colour | SMALLINT NOT NULL | Foreign key to a colours table |
ProductType | SMALLINT NOT NULL | Foreign key to a product type table. |
Excluding the product name a record would be 10 bytes.
In the EAV world the ProductID would have to be repeated for the 3 attributes (3 x 4 = 12 bytes) plus the attribute identifier (assume a SMALLINT at 2 bytes making 6 bytes) plus the value itself making an additional 6 bytes across all 3 attributes.
This would be 24 bytes excluding the penalty of using VARCHARs.
However, it is worth noting that EAV models have the option to exclude attributes where there is no value thus there is no storage overhead for NULL values within an EAV model
Locking/Blocking activity
If multiple elements are affected by a transaction then in an EAV world this would involve attempting to protect several records with each record representing an attribute.
The risk of lock escalation and subsequent blocking of other processes needs to be considered.
Increased calls to the database
In a traditional table structure the insert of a record represents the entire element.
For an EAV model each attribute for the element represents an insert, that is, an insert per field.
The means by which domain/relational integrity must also be considered. One data architect I was acquainted with was a huge fan of EAV models and when issues of domain/referential integrity and other data quality issues was raised suggested that the EAV model be protected by triggers.
If you are not a fan of triggers in tradititional relational high load OLTP system then the thought of a trigger on a table where the equivalent of every field is a record is not going to convert you to their use.
Hierarchal attributes
A normalised design may have a chain of tables to represent the data estate. CTOs have tech leads have developers and other child relationships.
In an EAV world, if these items exist within the EAV model then the model has to incorporate a “Parent” attribute.
As the ParentID attribute will be a string and the record to which is refers will be some form of integer then a lot of casting will have to take place in order to resolve the hierarchy.
Data profiling
3rd party data profiling tools general inspect a table and provide basic statistics
- List of discreet values
- Count of discreet values
- Count of values
- Count of null values
- Min/Max values
- Patterns
Poor quality data from profiles is usually immediately apparent to the human eye.
In addition these tools can provide correlation statistics between fields. Returning to the shirt/blouse example a profiler is likely to spot a relationship between
- Gender = Male, Product Type = Shirt
- Gender = Female, Product Type = Blouse
If the majority of attributes are represented by the EAV model then such profiling activity becomes difficult at best.
One option is to use views to present the data from the EAV model in a more traditional form however this is an expensive operation at the best of times and when coupled to an expensive process such as data profiling the EAV model is going to come under severe strain.
Data analysis
Analytics tools such as SAS are set up to use data in traditional table structures. For data persisted into an EAV model to be of use it will be necessary to invest significant resource in building ETL jobs to translate the data into a usable format. These jobs are likely to expensive in terms of the following
- IO
- CPU
- Memory
- Intermediate storage
Again, using views to presenting the data from the EAV model in a more useable relational form is an option but if you are having to do this it does beg the question as to what benefits the EAV model is really giving.
Materialised views
When views are used against an EAV model they are effectively pivoting data. I have seen certain agile books recommending EAV designs with materialised views. In SQL Server the nearest thing to a materialised view is an indexed view however there are some pretty severe restrictions on what can and cannot be done within an indexed view so these are of limited used.
Poor disciplines and rigour
This is not strictly speaking a weakness of an EAV model but in the necessity for self-discipline on the part of the implementers and business demanding implementation.
Implemented with sufficient governance an EAV model can actually facilitate the mindset to think about attributes (with their data validation rule sets) as enterprise wide attributes.
Without sufficient governance it is far easier to hide poorly defined attributes within an EAV structure. As all values are inherently generic in type there is nothing physical to prevent data of an inappropriate type being entered into the table.
Partitioning strategy
One of the key benefits of partitioning has been the huge reduction in IO and the time taken when purging or reindexing large volumes of data
Partitioning of data is done using a partition function usually on a field or computed column within the table to be partitioned. In an EAV model the field is actually a record therefore partitioning becomes invalid.
Coupled with the size of the principal EAV table this is a major disadvantage for large systems.
Data dictionary
The description of fields/attributes within tables in a database gives significant information about the corporate data asset. Tools such as Red-Gate SQLDoc can extract this metadata and publish it in a form designed for ease of consumption.
To produce the same functionality in an EAV model the EAV design must not only include a facility to record metadata but in addition bespoke work must be undertaken to support publishing of that metadata.
Purge strategy
If data within the EAV model has defined life-cycle then the means by which that data is purged and/or archived has to be considered.
If the appropriate date attribute is held within the EAV construct then the purge job will suffer from the same issues as experienced when filtering.
Ultimately in high capacity systems the purge jobs themselves pose a threat to business continuity.
Bulk loading data
It is usual to disable constraints and indexes when bulk loading into staging tables however domain integrity rules still apply. You cannot stuff a string into an integer field, a date must be a date etc.
Bulk loading an EAV model bypassing all constraints will be extremely fast however if the post reconcilliation checks are thorough and comprehensive they are likely to incur a high performance hit on the model.
Data model clarity
A schema diagram of a database with its relationships and constraints can be a useful communication tool and can reveal much of what is going on within a physical data model. This is lost with an EAV model as all you will get is a physical model of the EAV system itself.
This is of particular concern to data analysts who need to understand the way in which the data model works in order to make best use of it. When coupled with the complexity of querying an EAV model this can pose a significant barrier to gaining real business value and insight from data.
The importance of the communication aspect of a good schema diagram should not be underestimated particularly as agile development is all about collaboration with the business. I have found that non-IT business users find a high level schema diagram useful to outline concepts and spot gaps in requirements.
Security
Data governance and compliance burdens seem to be increasing year on year. The need to secure data appropriately is a common requirement however with an EAV model artefacts that would normally be separate tables and now lumped together.
It could be argued that this concern can be mitigated by having bespoke stored procedures, each with their own security context however as soon as this approach is taken you are moving away from the generic nature of the EAV model thus generating code you would have had to write in a traditional relational design.
Conclusion
A colleague of mine was studying for a masters degree in BI. One of the professors described EAV designs as write-only. Obviously such a description is an exageration but the comment was made to prove the general point about the difficulty of getting data out of an EAV design.
I would like to leave you with a final thought. The generic nature of an EAV model is such that there can only be a limited number of ways to produce one that is optimally designed. This being the case where are the reference patterns, books and white papers on EAV?

