
This stairway series was started in 2015. As such, the focus was on SQL Server 2012 and SQL Server 2014 only. When SQL Server 2016 was released, with lots of improvements in the columnstore technology, I decided to finish the planned levels with the original focus on SQL Server 2012 and 2014, and add one extra level with a brief overview of the improvements available in SQL Server 2016.
The amount of change is huge: more than enough for a full stairway series of its own. So in this level I can only touch on the many changes, to give you a glimpse of what to expect. If you currently work with columnstore indexes on SQL Server 2016, or if you are considering or preparing for an upgrade to SQL Server 2016, then I absolutely recommend reading the excellent series of blog posts that Niko Neugebauer has written, covering columnstore indexes in far more detail and far more depth than in this stairway. It is a long series: currently 104 (!!) posts and still growing, but definitely worth reading. The first 53 posts focus on columnstore indexes in SQL Server 2014; posts 54 and up are dedicated to SQL Server 2016.
For the demos in this level, I will once more use Microsoft’s ContosoRetailDW demo database. You can download the .BAK file from http://www.microsoft.com/en-us/download/details.aspx?id=18279. This is a database backup file that you then can restore to your SQL Server 2016 instance if you want to follow along.
Compatibility level
To prevent backwards compatibility issues, most of the improvements are only available when the database compatibility level is set to 130. Since we want to look at all those new features in this level, we will start by setting the database compatibility level:
USE [master]; go ALTER DATABASE ContosoRetailDW SET COMPATIBILITY_LEVEL = 130;
Listing 13-1: Increase the compatibility level to activate new features
Note that not all improvements depend on the compatibility level; if you do not run the code above then some of the demos in this level will still work; others will fail.
Nonclustered columnstore index
As discussed in the previous level, both clustered and nonclustered columnstore indexes have their pros and cons. But in SQL Server 2014, the nonclustered columnstore index still made the table read-only, and that limitation often is a showstopper for the nonclustered version. In SQL Server 2016, this restriction is now finally lifted. Both the clustered as well as the nonclustered version of the columnstore index now fully support updates to the underlying table.
Another improvement in SQL Server 2016 that may be relevant to some specific workloads is that nonclustered columnstore indexes can now be created with a filter. The ability to define a filter for a traditional rowstore index was introduced a long time ago, in SQL Server 2008; the effect is that only rows matching the filter are included in the index. This reduces the size of the index (saving disk space and speeding up index scans), but of course limits its use to only queries that need only rows included in the index. Typically, filtered indexes are used for tables that contain lots of data that is rarely ever needed in queries but cannot be permanently archived or deleted.
The code below shows these two new features. Assuming that almost all queries are for data in 2008 or newer, and since that subset of the data is large enough to warrant using a columnstore index, we create a nonclustered columnstore that includes data from 2008 only. We then update some rows in this set, to demonstrate that the nonclustered columnstore index no longer makes the data read only.
USE ContosoRetailDW;
go
CREATE NONCLUSTERED COLUMNSTORE INDEX NCI_FactOnlineSales
ON dbo.FactOnlineSales (OnlineSalesKey,
DateKey,
StoreKey,
ProductKey,
PromotionKey,
CurrencyKey,
CustomerKey,
SalesOrderNumber,
SalesOrderLineNumber,
SalesQuantity,
SalesAmount,
ReturnQuantity,
ReturnAmount,
DiscountQuantity,
DiscountAmount,
TotalCost,
UnitCost,
UnitPrice,
ETLLoadID,
LoadDate,
UpdateDate)
WHERE DateKey >= '20080101';
UPDATE dbo.FactOnlineSales
SET ReturnQuantity = 1,
ReturnAmount = 268.5
WHERE DateKey = '20090408';
Listing 13-2: Nonclustered columnstore index is now updatable and can be filtered
With these improvements, it is now fair to say that the nonclustered columnstore index is finally ready for prime time. It was a great feature since its introduction in SQL Server 2012 but the read only limitation always required workarounds; now you can finally choose this type of index without having to work around the limitations. But be aware: all the caveats that apply to updating the clustered columnstore index since SQL Server 2014 apply to the now updatable nonclustered columnstore index as well.
The ability to filter nonclustered columnstore indexes enables some use cases that were previously impossible to implement. For instance, if you know that recent data (e.g. orders placed in the last month) is subject to lots of changes while older data tends to be stable, you can choose to create a filtered nonclustered columnstore index on just the older data, while using filtered rowstore indexes on the recent data. This does require manual work to periodically rebuild the indexes with a more recent threshold in the filter.
Clustered columnstore index
Where, before SQL Server 2016, the nonclustered columnstore index was crippled by not being updatable, the clustered columnstore had other problems. Its lack of support for constraints meant that every update done to the data came with the risk of entering inconsistent data into the database. Not being able to create additional nonclustered rowstore indexes meant that the increased performance for data warehouse style queries came at the price of decreased performance for lookups and other OLTP-style work.
As you can see when you run the code below, these limitations have now been lifted. The clustered columnstore index now can easily be combined with constraints, and additional nonclustered (rowstore) indexes can be created to get better performance for very selective queries.
USE ContosoRetailDW;
go
-- Drop nonclustered columnstore created in previous listing
DROP INDEX NCI_FactOnlineSales
ON dbo.FactOnlineSales;
-- Drop existing clustered index (and the constraint it supports)
ALTER TABLE dbo.FactOnlineSales
DROP CONSTRAINT PK_FactOnlineSales_SalesKey;
-- Create a clustered columnstore index
CREATE CLUSTERED COLUMNSTORE INDEX CCI_FactOnlineSales
ON dbo.FactOnlineSales;
-- Recreate primary key (now using a nonclustered index)
ALTER TABLE dbo.FactOnlineSales
ADD CONSTRAINT PK_FactOnlineSales_SalesKey
PRIMARY KEY NONCLUSTERED (OnlineSalesKey);
-- Create an extra nonclustered index
CREATE NONCLUSTERED INDEX ix_FactOnlineSales_ProductKey
ON dbo.FactOnlineSales(ProductKey);
-- Show that foreign keys are still there, and still enabled
SELECT [name],
OBJECT_NAME(referenced_object_id) AS [Referenced table],
is_disabled
FROM sys.foreign_keys
WHERE parent_object_id = OBJECT_ID('dbo.FactOnlineSales');
Listing 13-3: Clustered columnstore indexes with constraints and other indexes
As you can see, I had to drop the nonclustered columnstore index before I could create the clustered columnstore index. It is not permitted on any version of SQL Server to have more than one columnstore index on the same table. It is also not permitted to have multiple clustered indexes, regardless of whether they are rowstore or columnstore, so I had to drop the primary key constraint and its supporting clustered index as well. However, after creating the clustered columnstore index I was able to recreate the constraint (supported by a nonclustered rowstore index) and then create an additional nonclustered index. And the final query shows that I did all this without ever having to drop or disable the existing foreign key constraints, as can be seen in the output below
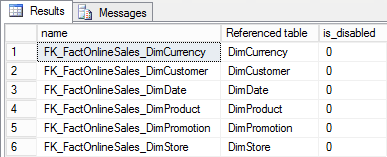
Figure 13-1: Foreign key constraints on a table with a clustered columnstore index
In SQL Server 2014, the updatability of the clustered columnstore came at a price: no other indexes and no constraints were possible. Now that SQL Server 2016 removes these limitations, I can say without hesitation that the columnstore feature has now finally reached maturity.
Columnstore indexes on memory optimized tables
Memory optimized tables (also known by the feature’s code name, Hekaton) were first introduced in SQL Server 2014 and, also, hugely improved in SQL Server 2016. The Hekaton feature was introduced in order to give high volume OLTP applications a performance boost comparable to what columnstore indexes did for data warehousing and reporting. All the table data is stored in memory, the amount of logging (which is still on disk) is minimized, all data structures are optimized to benefit from being stored in memory, and all data access uses a fully lock- and latch-free method so that concurrent connections never block each other. (If you want to know more about this feature, I recommend Kalen Delaney’s whitepaper).
This feature might seem to be as far removed from columnstore indexes as it gets, but in SQL Server 2016, Microsoft enabled us to create a clustered columnstore index on a memory-optimized table. This columnstore index itself will be memory-optimized as well: it is completely stored in memory; and the data structure is very similar to that of a disk-based columnstore index, with some small modifications to minimize the impact on OLTP performance.
The code in listing 13-4 shows how to create a columnstore index on a memory-optimized table. The first part of the code sets up a special filegroup for memory-optimized tables in the sample database. This is a one-time task only; once the filegroup exists you can create as many memory-optimized tables, with or without a columnstore index, as you wish.
USE ContosoRetailDW;
go
-- Create a filegroup for memory-optimized tables
ALTER DATABASE ContosoRetailDW
ADD FILEGROUP Contoso_MO
CONTAINS MEMORY_OPTIMIZED_DATA;
ALTER DATABASE ContosoRetailDW
ADD FILE (NAME = 'Contoso_MemOpt',
FILENAME = 'F:\DATA\Contoso_MemOpt') -- Change path name for your systemm!
TO FILEGROUP Contoso_MO;
go
CREATE TABLE dbo.MemOptDemo
(KeyCol int NOT NULL,
DataCol int NOT NULL,
CONSTRAINT PK_MemOptDemo
PRIMARY KEY NONCLUSTERED HASH (KeyCol)
WITH (BUCKET_COUNT = 65536))
WITH (MEMORY_OPTIMIZED = ON);
ALTER TABLE dbo.MemOptDemo
ADD INDEX csix_MemOptDemo CLUSTERED COLUMNSTORE
Listing 13-4: Creating a memory-optimized table with a columnstore index
In the code above, I have chosen to create the clustered columnstore index in a separate ALTER TABLE statement. It is also possible to define the index as part of the CREATE TABLE statement, as was required with all indexes on memory-optimized tables in SQL Server 2014.
Note, however, that a memory-optimized table with a clustered columnstore index does not allow any further schema modifications. So if you plan to also create multiple regular memory-optimized indexes on the table, make sure to create the clustered columnstore index last!
Real-time operational analytics
All three of the improvements for columnstore indexes mentioned above are targeted towards the same goal, dubbed “real-time operational analytics” by Microsoft marketing. A very short summary of what this term encompasses is a shift away from the classic distinction of OLTP and data warehouse Traditionally we set up two databases: a purely transactional database optimized for the concurrency and performance needs of an OLTP workload, and a data warehouse optimized for the speed of reporting and analytics. ETL jobs run at set intervals to bring the data in the data warehouse up to date, but immediately after that the data warehouse starts to fall behind until the ETL job runs again.
With real-time operational analytics, you use a new architecture. Just a single database, designed to handle both highly concurrent OLTP workloads and large scale analytics queries without paying the penalty of having two separate database servers, with separate storage, separate license costs, ETL jobs to copy the data, and lag in the reports. The various options we have in SQL Server 2016 to combine columnstore indexes (for the analytical queries) with traditional rowstore and even memory-optimized indexes (for the OLTP workload) facilitate such an architecture.
The assumption here is that the traditional data warehouse got its data from a single SQL Server OLTP database. In more complex scenarios where the data warehouse is fed from a variety of sources, and the ETL jobs include business logic to handle inconsistent or even conflicting versions of the truth from those versions, you will still need the separate data warehouse if only to serve as a single version of the truth for the business reports. But even in that case, you can benefit from some of the improvements to change your ETL feeds from a periodic big job to a continuous near-realtime processing of changes.
There is, of course, no free lunch. Running this type of mixed workload on a single database will always give you lower performance for both OLTP and analytics as compared to having two separate databases. But when you are prepared to pay that price, you are rewarded by some nice benefits as well: reports and dashboards created by analytics always draw from the most current real-time data. Plus, you also save a lot in server, storage, and licensing cost.
Specifically, for nonclustered columnstore indexes, you can exercise control over how much the columnstore index affects OLTP performance by creating a filtered nonclustered columnstore index. Let’s say, for example, that you have an order entry system where each order passes through multiple stages. In the first stages the order data is “hot”: it changes frequently and you like to avoid the overhead associated with modifying data in a columnstore index (as described in level 6 of this series). But once the order is final, you do want to have the benefit of a columnstore index. In that case, you could create a nonclustered columnstore index with a filter on the Status column.
There are also scenarios where you do not have a simple filter to separate the hot data out from the rest. In that case, you can achieve a similar benefit by using the new “compression delay” feature. This option forces SQL Server to wait at least the specified time before compressing data in closed rowgroups. So if you know that most of the changes to an order row will take place within an hour after order entry, you could set the compression delay to 60 minutes. Changes made within that period will always operate on an open or closed delta store. If changes are made after that time, then the data might already be in compressed format, resulting in some extra overhead to process the change. But if you chose the compression delay wisely, then this should only happen rarely. The code in listing 13-5 shows how you can set up such a compression delay.
USE ContosoRetailDW;
go
-- Drop clustered columnstore created in a previous listing
DROP INDEX CCI_FactOnlineSales
ON dbo.FactOnlineSales;
-- Create a nomclustered columnstore index with 60 minutes compression delay
CREATE NONCLUSTERED COLUMNSTORE INDEX NCI_FactOnlineSales
ON dbo.FactOnlineSales (OnlineSalesKey,
DateKey,
StoreKey,
ProductKey,
PromotionKey,
CurrencyKey,
CustomerKey,
SalesOrderNumber,
SalesOrderLineNumber,
SalesQuantity,
SalesAmount,
ReturnQuantity,
ReturnAmount,
DiscountQuantity,
DiscountAmount,
TotalCost,
UnitCost,
UnitPrice,
ETLLoadID,
LoadDate,
UpdateDate)
WITH (COMPRESSION_DELAY = 60);
Listing 13-5: Creating a nonclustered columnstore index with compression delay
One additional benefit of using a compression delay over using a filtered nonclustered columnstore index is that with the compression delay, all data is still included in and visible through the index. The compression delay will increase the amount of data in deltastore rowgroups, so accessing that data will be a bit slower, but that should still be just a tiny fraction of the total data in the table. When you place a filter on an index, then that index simply can no longer be used on any query that might need to access some data not included in the filter.
Batch mode
In addition to all the functionality improvements mentioned above, there have also been a lot of performance improvements relating to columnstore indexes in SQL Server 2016. I do not want to go over all of them, but I do want to point at the improvements made specifically to batch mode execution. In levels 10 and 11 I covered several query constructs that would prevent batch mode in SQL Server 2012, and sometimes in SQL Server 2014 as well. All of them have now been fixed. Every single example I presented in those levels will now run in batch mode without requiring any form of rewrite. However, in some cases the alternative version of the query does still perform better, so if you want the best possible performance it is still recommended to try the rewrite patterns and choose the best performing form for every query you write.
Probably the biggest news in SQL Server 2016 is the addition of batch mode support for the Sort operators and the introduction of a new operator, Window Aggregate, that enables SQL Server to evaluate the OVER clause in batch mode. Another very important step forward is that batch mode no longer requires the execution plan to be parallel.
Allowing batch mode in a serial plan is a much bigger deal than some people think. It is of course safe to assume that every server that runs SQL Server with sufficient data to benefit from columnstore indexes runs on multiple CPUs, but that does not guarantee parallel execution. Just reading the data from a columnstore index is often sufficient to lower the estimated cost of the execution plan to below the cost threshold for parallelism, especially if that threshold has been configured at a higher than default value. On SQL Server 2012 and 2014 that would result in a plan that runs serially, on just a single node and in row mode, which can cause queries that do less work to actually take more time than queries that do much more complex operations on much more data. On SQL Server 2016, the query will continue to run in batch mode even when it is estimated to be too cheap for parallel execution, so the performance drop will be far lower.
Pushdown
The final set of improvements that I will mention are similar in name but quite dissimilar in function: “string predicate pushdown” and “aggregate pushdown”. Let’s start with the first: String predicate pushdown. To see this in action, run the code in listing 13-6 and look at the actual execution plan.
USE ContosoRetailDW; go SELECT StoreKey, MIN(SalesOrderNumber), MAX(SalesOrderNumber) FROM dbo.FactOnlineSales WHERE SalesOrderNumber LIKE N'200912%' GROUP BY StoreKey;
Listing 13-6: Filtering the fact table on a string column
What you see as the actual execution plan depends on which version of SQL Server you run this on. Figure 13-2 shows the execution plan for SQL Server 2014:

Figure 13-2: String filtering on SQL Server 2014
The screenshot above clearly shows that the string filter is not pushed down into the scan like filters on other columns would be. The Columnstore Index Scan reads and returns all 12.6 million rows from the fact table, and the Filter operator than applies the LIKE test and reduces the data amount to the approximately 480,000 rows we need. Running the exact same query on SQL Server 2016 results in faster execution and a slightly simpler execution plan, as shown in figure 13-3: there is no separate Filter operator, because the LIKE condition has been pushed into the Columnstore Index Scan (which you can see when you look at its properties, but is also evident by the fact that now only the 480,000 needed rows are returned from this operator).

Figure 13-3: String filtering on SQL Server 2016
This string predicate pushdown reduces the complexity of the plan and eliminates the overhead of sending millions of unneeded rows from one operator to the next. But it also enables an internal optimization that saves lot of processor time. You may remember, from the start of the series, that columnstore indexes always use dictionaries for string columns. The actual string value is stored in the dictionary and assigned a numeric token, and the compressed rowgroups only store the token value (using the dictionary entry to translate the token back to the original string value when reading data). Because the Columnstore Index Scan is in the unique position of having access to the underlying storage structures, it can access the dictionary directly. So when a string filter is pushed down into a Columnstore Index Scan, it will at first not access the data at all, but only look at the dictionaries for that column, comparing every dictionary entry to the string filter. If it matches, the corresponding token value is added to an internal list. Once this is completed this internal list holds all token values of strings matching the filter. Finally, the actual segments are scanned; at this point the engine only has to match on these token values, instead of doing the original string comparison for each row in the table.
This method saves time because, typically, the number of distinct strings in a dictionary is far less than the number of rows (because strings repeated in the table are stored only once in the dictionary). Doing a string comparison is relatively expensive: even a “simple” equality check can be hard (because of string length and collation issues); a LIKE pattern as in our example query adds more complexity. The tokens that represent the dictionary entries are numbers, which are far easier to compare. So by applying the (expensive) string filter only on the (relatively small) dictionary and doing a (much cheaper) numeric comparison on all the rows in the table, we usually save time.
Though the term “aggregate pushdown” sounds similar to “string predicate pushdown”, it is actually a different process. With string predicate pushdown, unneeded rows are filtered out during the scan so that the operators in the execution plan have far to process less data. With aggregate pushdown, part of the actual processing is offloaded onto the scan operator. You can see this in action when you run the code in listing 13-7:
USE ContosoRetailDW; go SELECT StoreKey, SUM(SalesAmount) FROM dbo.FactOnlineSales WHERE DateKey > '20080101' GROUP BY StoreKey;
Listing 13-7: An example of simple aggregation
When you execute the query above on a SQL Server 2014 instance and look at the actual execution plan, you will see no surprises at all: a Columnstore Index Scan operator that reads all 12.6 million rows, filters on DateKey, and returns the 8.6 million matching rows to a Hash Match (Aggregate) operator where the aggregation is done. On my test system, this query runs in approximately 50 milliseconds, taking a total of 140 milliseconds CPU time.
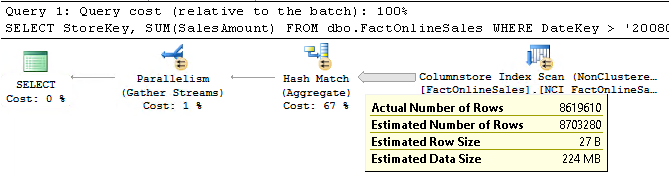
Figure 13-4: Simple aggregation on SQL Server 2014
On SQL Server 2016, this same query runs a lot faster: only 30 milliseconds elapsed time and only 60 milliseconds of CPU time on my test system. The execution plan on SQL Server 2016 can be surprising, and even misleading. As shown in figure 13-5, one might think that the estimation is completely wrong. Only about 45 thousand rows appear to be returned from the Columnstore Index Scan operator, instead of the estimated 86 million.
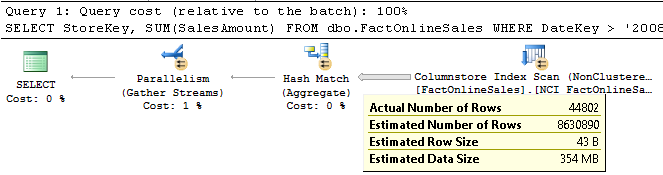
Figure 13-5: Simple aggregation on SQL Server 2016
And yet the query does return the same result on SQL Server 2016 as on SQL Server 2014, the sum of all 86 million sales since January 1st, 2008. This is a sign of aggregate pushdown, and a further sign can be found by looking at the properties of the Columnstore Index Scan operator itself, as shown in figure 13-6. (The properties relevant for this discussion have been highlighted):
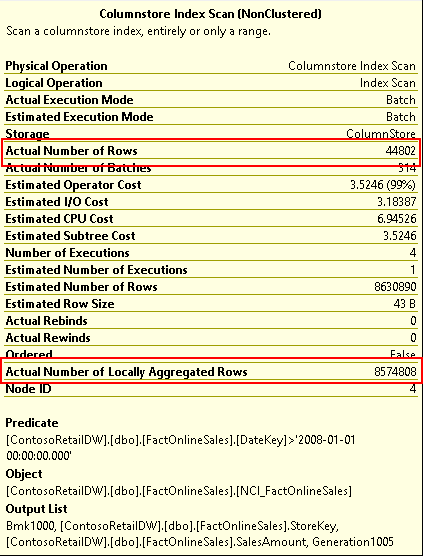
Figure 13-6: Properties of the Columnstore Index Scan operator
The properties shown here confirm what we already saw in figure 13-5: only 45 thousand rows were returned to the Hash Match (Aggregate) operator. However we do see a new property, “Actual Number of Locally Aggregated Rows”, where the remaining 8.5 million rows are now reported. Adding up these two numbers results in the exact same number of rows that was returned to the Hash Match (Aggregate) operator on SQL Server 2014.
These numbers can give you a first clue of what is happening, but they do not tell the whole story. Pushing down the aggregate means that the Clustered Index Scan operator “knows” that we need aggregates only, not individual rows. So it will still scan and filter all rows as normal, but instead of returning them all to the calling operator it will internally keep track of the aggregations.
Any rows that, for whatever reason, cannot be aggregated locally inside the scan operator are still passed to the Hash Match (Aggregate) operator, where they are aggregated in the normal way. This applies to data in uncompressed (open or closed) rowgroups, but the example above shows that this can also apply to some of the data in compressed rowgroups. The Hash Match (Aggregate) operator aggregates those rows the same way it always does, and then combines those results with the aggregated results it receives from the scan operator (using a second data stream that is not visible in the execution plan).
Aggregate pushdown can only be used if several conditions are met. Only the most common aggregate functions are supported (SUM, AVG, MIN, MAX, COUNT, and COUNT_BIG), the storage size of the column being aggregated cannot exceed 8 bytes, and the aggregate function has to operate directly on the column, not on any expression (no matter how simple).
Conclusion
When Microsoft released the first version of columnstore indexes in SQL Server 2012, it was a feature with great promise but too many limitations for wide spread usage. That changed in SQL Server 2014 when all the biggest pain points were addressed; with that version using columnstore indexes for data warehouses and reporting databases became a very viable option.
SQL Server 2016 once again upped the ante. Even more limitations were lifted, and some incredible further performance improvements were added. For data warehousing and reporting, I now consider columnstore indexes a fully mature feature. If you are running on SQL Server 2016 and you have large BI workloads, you probably miss out if you do not create columnstore indexes on your largest tables.
The introduction of real-time operational analytics is also a game changer. Being able to combine OLTP and reporting/analytics on the same database can make a huge difference: no need for a separate copy of the data, and the ability to have dashboards and reports that are fully real-time. However, this specific use of the columnstore technology is fairly new, so you should expect to experience some hiccups if you consider implementing it.
And that concludes the Stairway to Columnstore Indexes. At this point I want to thank my editors, Niko Neugebauer and Kalen Delaney, for keeping me straight. I also want to thank Tony Davis for giving me the opportunity to investigate and write about this fascinating new technology. But most of all, I want to thank you, the audience. I hope you liked the series, and I hope that some of my enthusiasm for columnstore indexes rubbed off on you.
And now get to work and start optimizing those workloads!
