

Introduction
For normal transactional and snapshot replication, an existing identity
property on a published table is not transferred to the subscriber. This is
simply because it would never be required, as the subscriber is not intended to
insert rows him/herself. Merge replication however is intended for independent,
disconnected access to data, so in this case the identity property is
transferred. The question therefore is how to manage the identity ranges and
ensure there is no overlap in identity values on synchronization. Basically,
there are 2 options - automatic and manual range management. SQL Server can
automatically manage identity ranges in merge replication but this has a
reputation for sometimes becoming problematic. Although it is true that when the
range runs out before synchronization takes place there can be complications, in
most cases this can be simply avoided: typically the identity attribute applies
to an integer datatype, and as these can range from -2,147,483,648
through 2,147,483,647 then really unless you have an incredibly big number of
subscribers, selecting a large range of values per subscriber should ensure that
there is never any need for a range to run out. Nevertheless, it is often a
question asked on newsgroups of how to manually administer the identity ranges
and so take the matter entirely into your own hands. This article explains
step-by-step how to practically implement such an algorithm.
(1) The NoSync Method
Firstly select the algorithm you'll use to ensure each node's range won't overlap. There
are several methods to chose from (see
Michael Hotek's site). For example, lets assume you have a publisher and 3
subscribers. The publisher can have positive even numbers, the first subscriber
positive odd numbers, the second subscriber negative even numbers and the third
subscriber negative odd numbers. Using this method, each node has roughly one
billion possible entries.
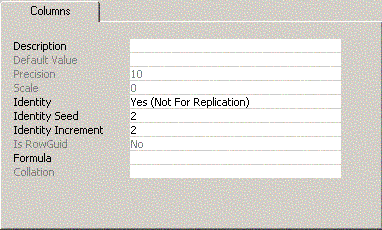
Once the algorithm is selected, make sure the seed (2)
and increment (2) are set correctly at the publisher before publishing the
table.
If you try to change the identity value later on at the
publisher or the subscriber this will result in the error message below. This
applies at the publisher as soon as the table is published,
even before there is a subscriber:
'tCompany' table
- Unable to modify table.
ODBC error: [Microsoft][ODBC SQL Server
Driver][SQL Server]Cannot drop the table 'dbo.tCompany' because it is being used
for replication.
Now publish the table using merge replication. Be sure
to leave the Identity Range checkbox on the article properties blank to allow
manual control of the identity range.
Next transfer the table to the subscriber. You can use
DTS, backup/restore, BCP, linked servers - whatever you find useful. The table
can only be transferred once it has a uniqueidentifier column having the rowguid
attribute, or you'll get the error below on synchronization:
Error: Invalid column name 'rowguidcol'.
As long as the order in this article is followed, this
error can't occur, as either the table already has the rowguid. or publishing
the table will add one to the table.
Next, on the subscriber reset the current identity
value and the seed. Why is this necessary? Consider the case if there are 4
records:
| ID | Company | rowguid |
| 1 | HP | {5B9D38B2-5089-4C42-816B-48D0157ADA34} |
| 2 | DH | {5A17C1B2-C045-4279-87BE-38F5F4959C0B} |
| 3 | IBM | {B2FF82DA-5384-42AF-92F0-4029A5908395} |
| 4 | Microsoft | {AB637574-7EBF-4950-9865-5378166BEB96} |
If the publisher has a seed = 2 and increment = 2 and the first
subscriber has seed = 1 and increment = 2, in either case the next record will
have an ID of 6. This is because the current identity value is 4 so in both
cases the next value is 4 + 2. So,
DBCC CHECKIDENT (tCompany,RESEED, 5)
needs to be run on the subscriber to start things off correctly. This
could be done using a post-snapshot script, but as the seed and increment must
be changed manually then having one extra manual step is the easiest solution.
Actually this step can be done on its own, and the seed
and increment on the subscriber left the same as that on the publisher i.e. in
this example the identity value is going up in twos, so resetting the current
identity value is sufficient. However this can be a little confusing from the
administration point of view and it's preferable later on to be able to have a
look at the seed and increment settings on a table to determine the intended
demarcation.
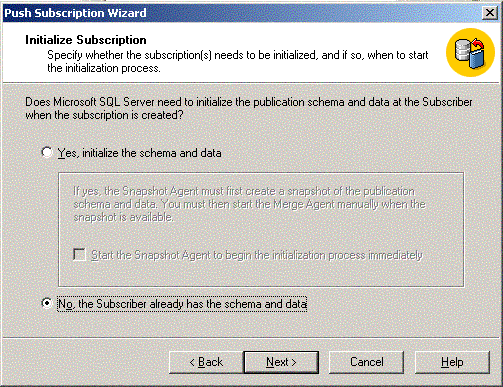
Finally do a nosync initialization. If you're doing this through scripts
this is sp_addsubscription
with @sync_type=none, or through the GUI select the option
below.
As with any merge nosync initialization, there is a
price to pay - any other articles added must also be nosync ones. With this in
mind, you might want to isolate this article, and any associated ones into their
own publication.
(2)Using @creation_script in sp_addmergearticle
The second method is not
fully supported by the GUI. It involves defining a separate script to create the
table on the subscriber
exec sp_addmergearticle @publication = N'TestIdentitiesXXX', @article = N'tCompany', @source_owner = N'dbo', @source_object = N'tCompany', @type = N'table', @description = null, @column_tracking = N'true', @pre_creation_cmd = N'drop', @creation_script = 'C:\misc\tCompany.sql', @schema_option = 0x00, @article_resolver = null, @subset_filterclause = null, @vertical_partition = N'false', @destination_owner = N'dbo', @auto_identity_range = N'false', @verify_resolver_signature = 0, @allow_interactive_resolver = N'false', @fast_multicol_updateproc = N'true', @check_permissions = 0
The arguments are much as
per usual, with the exception of @creation_script which defines the file used to
create the table, and the @schema_option which forces the aforementioned file to be used. The script
itself (C:\misc\tCompany.sql) is a simple create table script generated by
enterprise manager on the publisher, but with the identity seed altered relative
to the publisher:
[ID] [int] IDENTITY (2, 2) NOT FOR REPLICATION NOT NULL
Once again, after
initialization the current identity value will need altering to reseed the
starting point.
After the snapshot agent
has run, the text file is transferred to the repldata share. This file can be
edited by hand to modify the identity attributes before each subscriber
initializes. Such changes can theoretically be made using a system stored
procedure to make changes to an existing article's details -
sp_changemergearticle. However, once one subscriber has synchronized, changing
the creation script using this method will invalidate this subscription and
you'll be obliged to reinitialize all other subscribers (@force_invalidate_snapshot
= 1 and @force_reinit_subscription = 1) so in practice the file can only be
altered manually.
Any further articles can
be added to this publication as per usual.
Conclusions
Two alternative methods
are presented to allow manual identity range management. The first is easier to
set up using graphical tools than the second. However the second method allows
for more flexible addition of new articles to an existing publication.
Paul Ibison, December 2004, http://ssisblog.replicationanswers.com/
