

Introduction
In my prior article, Using FULL JOINs to Compare Datasets, I described a technique to compare two queries to determine the exact data differences between them. In this second article I'll describe how to use this differential query technique not only to synchronize between a source and destination table - but also to create a point-in-time, "effective dated" change history of the destination table. First, some background.
A common pattern in data warehousing is a "slowly changing dimension," or SCD, which is a dimension that tracks data changes over time. There are multiple ways to track these changes, which vary by the amount of history to track and the method by which it's tracked. In a type-2 SCD, each time a tracked dimension attribute changes, a new version of the record is created to capture this change. For example, if a customer gets married on Nov 13, reports that include marital status should show them as single up until Nov 12, but married on Nov 13 or later. These changes are tracked by inserting a new dimension record with the same natural key and a new surrogate (i.e., identity) key each time there's a change. Each dimension record version has starting and ending effective-date timestamps, thereby creating a point-in-time archive of the evolution of that dimensional data element. Any fact tables that link to that dimension will reference the surrogate key, targeting the exact point-in-time version of the dimension that made sense at the time the fact record occurred.
But the practice of storing point-in-time changes does not need to be limited to dimensions! Row version history can also be applied to data warehouse fact tables, albeit with a slightly different approach. Instead of storing different whole versions of fact records as they evolve through time, store only the differential records that adjust the facts from before to after. With this technique, fact table rows are never updated or deleted--only new rows are inserted. For example, if a sales fact measure value coming from the source system starts at value 10 and is later adjusted to 12, the data warehouse needs to reflect this change by inserting a new row of value 2. This approach of inserting differential records can handle source record INSERTs, UPDATEs, and DELETEs, all using the same differential query that compares source to destination.
Example
To illustrate this approach, I'll use an example of a business that tracks sales figures for a retail store. Let's assume this store has an extremely simple data warehouse with three main dimension tables: dim.SalesPerson, dim.Product and dim.Date, plus one fact table stored at the grain of order items: fact.OrderDetail. Data from the point of sale terminals is uploaded hourly to the data warehouse into a staging table called staging.SalesDetailSource. Once the staging table is refreshed, any changes must be pushed to the fact table, which will store the effective-dated history of all sales figures.
The accompanying SQL script file contains all the code necessary to recreate these results for yourself. Let's look at the initial state of the system:
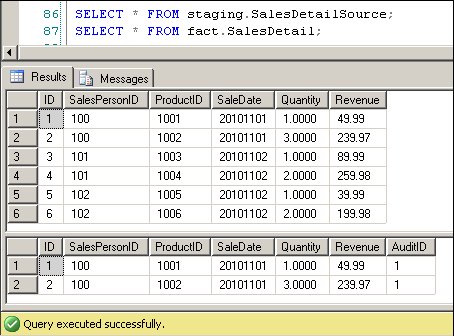
Initially, the staging table has records for both Nov 1 and 2 (dates are stored as integer smart keys), but the fact table has records for Nov 1 only. Now let's use the full join technique to query for the exact differences between the staging and fact tables within a tolerance of 1 cent.
DECLARE @Tolerance DECIMAL(3,2); SET @Tolerance = 0.01; WITH SRC AS ( SELECT SalesPersonID, ProductID, SaleDate, SUM(Quantity) AS Quantity, SUM(Revenue) AS Revenue FROM staging.SalesDetailSource GROUP BY SalesPersonID, ProductID, SaleDate ), DEST AS ( SELECT SalesPersonID, ProductID, SaleDate, SUM(Quantity) AS Quantity, SUM(Revenue) AS Revenue FROM fact.SalesDetail GROUP BY SalesPersonID, ProductID, SaleDate ), DIFFS AS ( SELECT COALESCE(S.SalesPersonID, D.SalesPersonID) AS SalesPersonID, COALESCE(S.ProductID, D.ProductID) AS ProductID, COALESCE(S.SaleDate, D.SaleDate) AS SaleDate, ISNULL(D.Quantity,0) - ISNULL(S.Quantity,0) AS Quantity, ISNULL(D.Revenue,0) - ISNULL(S.Revenue,0) AS Revenue FROM SRC S FULL JOIN DEST D ON S.SalesPersonID = D.SalesPersonID ANDS.ProductID = D.ProductID AND S.SaleDate = D.SaleDate ) SELECT * FROM DIFFS WHERE ABS(Quantity) > @Tolerance ORABS(Revenue) > @Tolerance
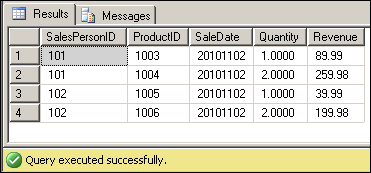
Sure enough, the 4 new values from Nov 2 are identified as differences. Notice how I have to compare aggregates (GROUP BYs) - not line item details - from the source and destination. This is because there could be multiple records for the same dimensional combination, and we don't want to over-join the datasets.
Next, let's restructure the SELECT query into an INSERT query to push the differential records, thereby bringing the fact table into sync.
--First Differential Insert DECLARE @Tolerance DECIMAL(3,2); SET @Tolerance = 0.01; DECLARE @AuditID INT; --Insert the new Audit record before loading data INSERT INTO dim.Audit(CreateDate) VALUES (GETDATE()); SET @AuditID = SCOPE_IDENTITY(); WITH SRC AS ( SELECT SalesPersonID, ProductID, SaleDate, SUM(Quantity) AS Quantity, SUM(Revenue) AS Revenue FROM staging.SalesDetailSource GROUP BY SalesPersonID, ProductID, SaleDate ), DEST AS ( SELECT SalesPersonID, ProductID, SaleDate, SUM(Quantity) AS Quantity, SUM(Revenue) AS Revenue FROM fact.SalesDetail GROUP BY SalesPersonID, ProductID, SaleDate ), DIFFS AS ( SELECT COALESCE(S.SalesPersonID, D.SalesPersonID) AS SalesPersonID, COALESCE(S.ProductID, D.ProductID) AS ProductID, COALESCE(S.SaleDate, D.SaleDate) AS SaleDate, ISNULL(S.Quantity,0) - ISNULL(D.Quantity,0) AS Quantity, ISNULL(S.Revenue,0) - ISNULL(D.Revenue,0) AS Revenue FROM SRC S FULL JOIN DEST D ON S.SalesPersonID = D.SalesPersonID ANDS.ProductID = D.ProductID AND S.SaleDate = D.SaleDate ) INSERT INTO fact.SalesDetail (SalesPersonID, ProductID, SaleDate, Quantity, Revenue, AuditID) SELECT SalesPersonID, ProductID, SaleDate, Quantity, Revenue, @AuditID FROM DIFFS WHERE ABS(Quantity) > @Tolerance ORABS(Revenue) > @Tolerance ; --Update the Audit record with information about this data load UPDATE dim.Audit SET NumRecords = @@RowCount WHERE AuditID = @AuditID;
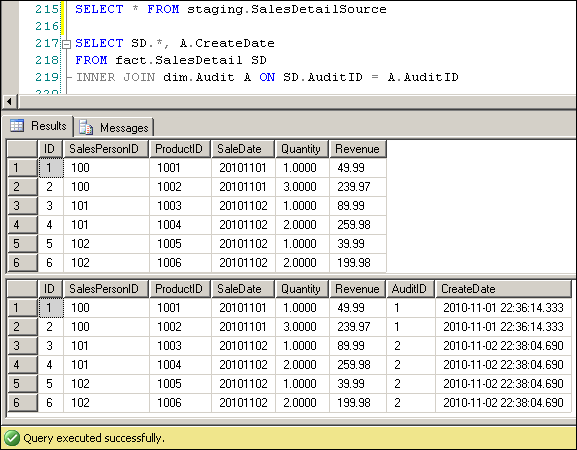
Now the fact table is synchronized with the staging table. At this point, if we ran the same differential SELECT query again, it would return zero records.
Notice the "AuditID" column at the end of the fact table. This column is a reference to the Audit dimension, which is added to this data warehouse to track the exact time of the data load. Other descriptive information, such as the load start time, load end time, number of records, min and max dates, data quality flags, etc., can be stored in this table as well.
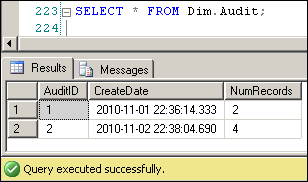
By adding the AuditID field directly to the SalesDetail table, we've enabled the ability to link each fact record to the timestamp of its arrival, which allows us to recreate a point-in-time snapshot. This is the key to the technique - it's what powers the "effective date" reporting behind it. I'll expand on this concept below.
But first, let's see what happens when a fact measure value is changed. Let's say that the revenue of productID 1006 was incorrectly entered as $199.98, when it should have been $179.98. The record is updated in the source to reflect $179.98, creating a $20 revenue discrepancy between the source and destination.
Run the differential insert algorithm again, and watch what happens:
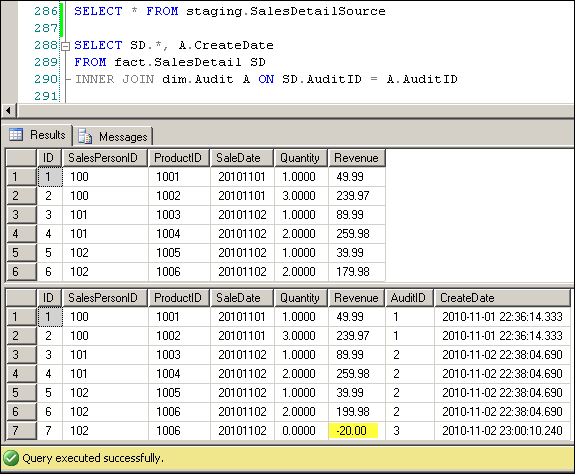
The -20.00 adjustment record is automatically inserted by the differential algorithm. Note that any queries against the fact table need to sum the measures to arrive at the final values, as these entries are additive.
Next, let's change a dimension ID to see what happens. Dimension updates get a slightly different treatment: the original record is completely removed and replaced with the updated record, as the FULL JOIN includes the dimension column itself. By way of example, let's say that product 1004 on Nov 2 was incorrectly attributed to SalesPerson 101 when it should have been SalesPerson 100. Update the source record.
UPDATE staging.SalesDetailSource SET SalesPersonID = 100 WHERE ProductID = 1004 AND SalesPersonID = 101 AND SaleDate = 20101102;
Now rerun the differential query. Then, run the following report:
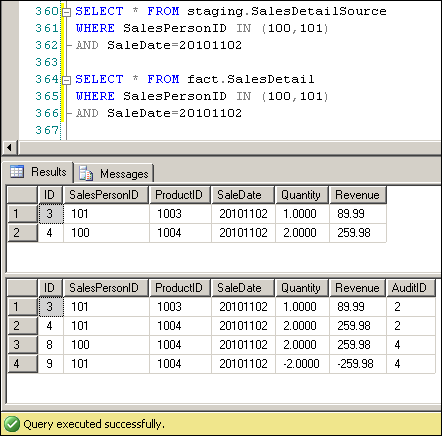
The sale of productID 1004 was taken away from salesperson 100 and allocated to 101, as expected.
Finally, if a DELETE is issued against the staging table, the mechanics work just like this dimensional update: only an offsetting record is inserted into the fact table to remove the deleted entry.
Wrap Up
So why go through the hassle of comparing datasets instead of just issuing a TRUNCATE and INSERT to refresh the whole table? The main benefit is realized when the AuditID values are used to recreate a point-in-time snapshot. When we query the table without an AuditID filter, it would reflect all data that is known, up to and including the last data extraction. But by querying using an AuditID filter (e.g. AuditID <= 3), we can effectively wind back the clock and recreate a report as of a particular point in time. To illustrate, let's look back at the salesperson modification example.
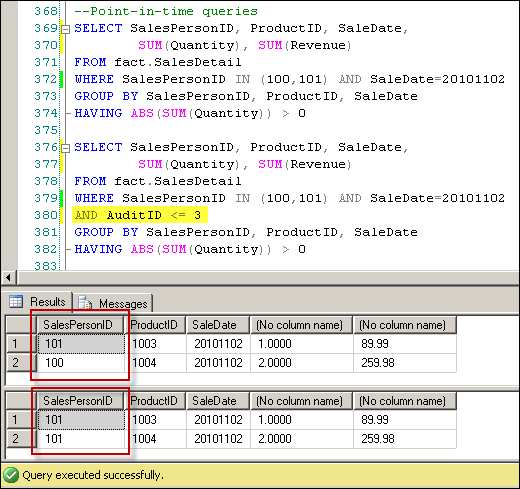
Let's say that Audit point 3 was Nov 2nd at 6:00 PM and Audit point 4 was Nov 3rd at 8:00 AM. Thus, the item's salesperson allocation was not adjusted until the next day, and if a report was printed on the night of Nov 2, it would still attribute the sale to sales person 101. If the same report was printed during the day on Nov 3, it will include the adjustment added in Audit ID 4 and attribute the revenue to sales person 100. Using AuditIDs, we can recreate this sequence of events exactly - and easily reconcile to reports generated at different times. A data load approach based on TRUNCATE and INSERT statements makes this impossible, as the detailed history of adjustments is lost on every data refresh.
Furthermore, the technique allows two or more departments to agree on a close/lock point for a given time period so that everyone is seeing the same values returned - taking timing issues out of the equation when numbers don't match. If a particular AuditID that closes a day / month is stored in a different table, reports that join to that table as part of the date filter will always arrive at the agreed-upon "closed" value.
Another benefit of this approach is that by inserting differential records only - and never updating or deleting existing records - data uptime stays at 100%, contention (blocking) on the table is potentially reduced, and transaction log volume is decreased dramatically.
One limitation of this approach is that it can be difficult to implement against large datasets. It simply may not be feasible to compare two multi gigabyte-sized tables in memory using a differential comparison query. One way to mitigate this is to divide the data into to smaller subsections such as months and differentially insert one month at a time. An even better way is to remove these differential queries altogether and replace them with incremental updates gathered via Change Data Capture (CDC), a feature introduced in SQL Server 2008 Enterprise Edition. I'll cover that technique in my third and final article in this series. Stay tuned!
