

SQL Server covering indexes have gain much attention for performance tuning for SELECT statements, but little has been said on their effect on the UPDATE statement. This paper will discuss these factors and show potential performance enhancements for specific instances.
The scripts below show performance for a covering index for a SELECT statement using the AdventureWorks2017 database and then extend that index to show potential performance benefits for UPDATE statements as well.
Consider the following T-SQL statement:
USE AdventureWorks2017
GO
SET STATISTICS IO,TIME ON --poor man's profiler; I use all the time for performance tuning
GO
SELECT SalesOrderID, AccountNumber, CustomerID
FROM Sales.SalesOrderHeader
WHERE SalesPersonID = 277
ORDER BY 1
GO
SET STATISTICS IO,TIME OFF
GO
-- (473 row(s) affected)
-- query cost = 0.545; 689 logical reads
And yields a query plan:

Figure 1: Clustered Index Scan (© 2018 | ByrdNest Consulting)
Note the clustered index scan with a total query cost of 0.545. The original index, IX_SalesOrderHeader_SalesPersonID, is based on a single column of SalesPersonID. If we run the same query with a different SalesPersonID:
SET STATISTICS IO,TIME ON
GO
SELECT SalesOrderID, AccountNumber, CustomerID --note index seek (IX_SalesOrderHeader_SalesPersonID),
FROM Sales.SalesOrderHeader -- but resulting Key Lookup
WHERE SalesPersonID = 285
ORDER BY 1
GO
SET STATISTICS IO,TIME OFF
GO
--(16 row(s) affected)
--query cost = 0.052; 50 logical reads
With a Query plan of
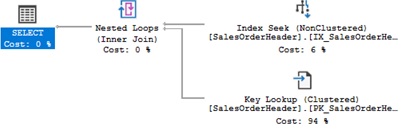
Figure 2: Key Lookup (© 2018 | ByrdNest Consulting)
Strange; same query but different query plans. The reason is primarily the size (number of rows) in the result sets. The first query returned 473 rows and the second query returned 16 rows. In the first query, the compiler decided (from the statistics) that it was better to do a clustered index scan because of the larger result set.
In the second query, the compiler (again, from statistics) decided that an index seek on SalesPersonID with a resulting lookup on the clustered index was better performing. This is a prime example of what might happen in a stored procedure with parameter sniffing – only in a stored procedure the query plan (whichever it might be) sticks around for a while.
But, let’s get back to covering indexes. If we go back and add the key lookup output parameters with an INCLUDE clause we can now get a single index that includes all the columns needed for the query.
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_SalesPersonID ON Sales.SalesOrderHeader
([SalesPersonID] ASC)
INCLUDE (AccountNumber, CustomerID)
WITH (DROP_EXISTING = ON, ONLINE = ON, DATA_COMPRESSION = ROW)
GO
The column SalesOrderID (PK) is not needed since it is automatically added to the index. So, now running the first SELECT we get:
SET STATISTICS IO,TIME ON
GO
SELECT SalesOrderID, AccountNumber, CustomerID --now index seek (because the index is "covering")
FROM Sales.SalesOrderHeader
WHERE SalesPersonID = 277
ORDER BY 1
GO
SET STATISTICS IO,TIME OFF
GO
--(473 row(s) affected)
--query cost = 0.005; 5 logical reads
with a query plan of

Figure 3: Index Seek (© 2018 | ByrdNest Consulting)
Wow, quite an improvement: 689 logical page reads down to 5 and query cost from 0.545 down to 0.005.
Rerunning Query 2 we get
SET STATISTICS IO,TIME ON
GO
SELECT SalesOrderID, AccountNumber, CustomerID
FROM Sales.SalesOrderHeader
WHERE SalesPersonID = 285
ORDER BY 1
GO
SET STATISTICS IO,TIME OFF
GO
--(16 row(s) affected)
--query cost = 0.005; 3 logical reads
with the same query plan as above. Note the query dropped from 50 logical page reads down to 3. This is a great example of how a covering index can greatly benefit a SELECT query. Note both queries used the same query plan.
There are many WOMs (word of mouth) about indexes and their utilization, but sufficed to say you should still keep indexes (especially in OLTP systems) narrow in width. You don’t want to create a covering index that essentially reorders the clustered index (whole table).
So, we now have a covering index based on SalesPersonID. Let’s now look at a similar (in logic) T-SQL UPDATE statement:
UPDATE soh
SET AccountNumber = AccountNumber + '*',
RevisionNumber = RevisionNumber + 1,
ModifiedDate = GETDATE()
FROM Sales.SalesOrderHeader soh
JOIN Sales.SalesPerson sp
ON sp.BusinessEntityID = soh.SalesPersonID
WHERE sp.TerritoryID = 1;
GO
--Clustered Index scan on IX_SalesOrderHeader_SalesPersonID (60% of query plan)
-- (Output = SalesOrderID, RevisionNumber, AccountNumber, SalesPersonID)
--Total Query cost = 9.01
with an estimated query plan of

Figure 4: QueryPlan Clustered Index (© 2018 | ByrdNest Consulting)
where the numbers in green (above) come from the estimated query plan. Note that there are Clustered Index scans on both tables and that the scan on SalesOrderHeader is 60% of the query plan cost.
This update statement has 2 additional columns not in the covering index: RevisionNumber and ModifiedDate. If we revise the covering index as
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_SalesPersonID ON Sales.SalesOrderHeader
([SalesPersonID] ASC)
INCLUDE (AccountNumber, CustomerID, RevisionNumber, ModifiedDate)
WITH (DROP_EXISTING = ON, ONLINE = ON, DATA_COMPRESSION = ROW)
GO
And rerun the same UPDATE statement above we get an index seek: IX_SalesOrderHeader_SalesPersonID, with a query cost = 6%, and an overall query plan cost = 0.146. The estimated query plan is:

Figure 5: QueryPlan Index Seek (© 2018 | ByrdNest Consulting)
Now there is an index seek on Sales.SalesOrderHeader with the seek only 6% on the total query plan and the total query plan cost dropping from 9.01 to 0.146. Now let’s look at another UPDATE, but first revert back to the original covering index:
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_SalesPersonID ON Sales.SalesOrderHeader
([SalesPersonID] ASC)
INCLUDE (AccountNumber, CustomerID)
WITH (DROP_EXISTING = ON, ONLINE = ON, DATA_COMPRESSION = ROW)
GO
This second UPDATE statement is still on Sales.SalesOrderHeader:
UPDATE soh
SET AccountNumber = AccountNumber + '*',
RevisionNumber = RevisionNumber + 1,
ModifiedDate = GETDATE()
FROM Sales.SalesOrderHeader soh
WHERE SalesPersonID in (275,280,285,290)
GO
--now we get a clustered index scan on PK_SalesOrderHeader with Query Plan = 74%
--Overall query plan cost is 0.731
and with the original covering index has an estimated query plan

Figure 6: QueryPlan Update Clustered Index Scan (© 2018 | ByrdNest Consulting)
This time it is asking for a revised index with INCLUDE (RevisionNumber,AccountNumber). If we apply the same covering index as we did for the first update:
CREATE NONCLUSTERED INDEX IX_SalesOrderHeader_SalesPersonID ON Sales.SalesOrderHeader
([SalesPersonID] ASC)
INCLUDE (AccountNumber, CustomerID,RevisionNumber, ModifiedDate)
WITH (DROP_EXISTING = ON, ONLINE = ON, DATA_COMPRESSION = ROW)
GO
And rerun the 2nd UPDATE query we get a NonClustered Index seek on IX_SalesOrderHeader_SalesPersonID (query cost 4%) and an overall query plan cost is 0.149

Figure 7: QueryPlan Update Index Seek (© 2018 | ByrdNest Consulting)
where we see an overall query plan cost drop from 0.731 to 0.149 and the clustered index scan taking 74% of the query cost dropping to an index seek costing only 4% of the overall query cost for the Sales.SalesOrderHeader table
Conclusions
So now we have a covering index that improves performance for both SELECT and Update statements.
Generally covering indexes not only help SELECT query performance, but as shown can help UPDATE performance. Although not shown here, I ran into a client scenario using the KEY lookup (as described in the SELECT example above) for an UPDATE statement that was having deadlock issues due to a concurrency as well as a double lookup on the applicable table. Adding a covering index resolved that problem also. In any case, as Microsoft always says: “Test, Test, Test!”


