

It seems that most developers underestimate performance degradation when using sub queries as column expressions in comparison to using joins to retrieve a large dataset. The difference is minimal when the outer SELECT statement will return just a couple of rows but it is more noticeable when the SELECT statement returns thousands of rows. The best way to demonstrate this is to try it out and analyze the execution plans of both.
Test Scenario
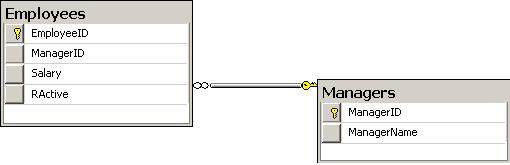
I've used a simple two table database using the typical Managers - Employees tables, where multiple employees can be linked to the same Manager.
The attached scripts will create both tables together with the data population. The managers table will contain 3 rows, while 50001 rows will reside in the employees table.
Editor: How did you get this, might show some code and explain what this means
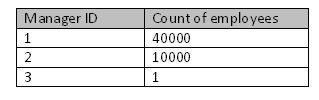
The following SQL will count the number of records for each distinct manager ID
Select COUNT(*),ManagerID From Employees Group By ManagerID Order By ManagerID
and this the result, displaying the records distribution.
The script will also create a non-clustered covering index (ix_Employees) on the employee table on the ManagerID column to eliminate any Key Lookups.
Running the Tests
Now for the actual test, I've written a simple query to retrieve all employees for a particular manager, returning also the manager name. This will involve scanning the employee table for the selected ManagerID and linking to the Managers table to retrieve the Manager Name.

For the above tests 1 & 2, there was no difference in performance; both returned 1 row as expected with identical query cost.
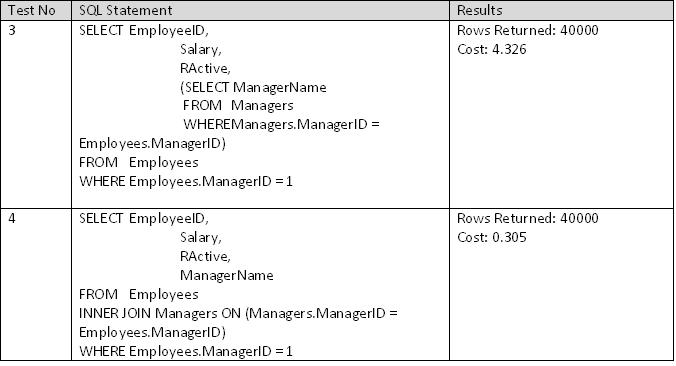
However the performance difference becomes more obvious when more rows are returned as in Tests 3 & 4. The number of rows returned for these tests is 40000.
Analyze the Results
Let's investigate what happened by analyzing the execution plans. In the first two tests, an Index Seek was performed on the Employees table to locate ManagerID 3, which returned one row, and then this output was joined to the Manager table to retrieve the Manager Name.
Execution plans for Tests 1 & 2.
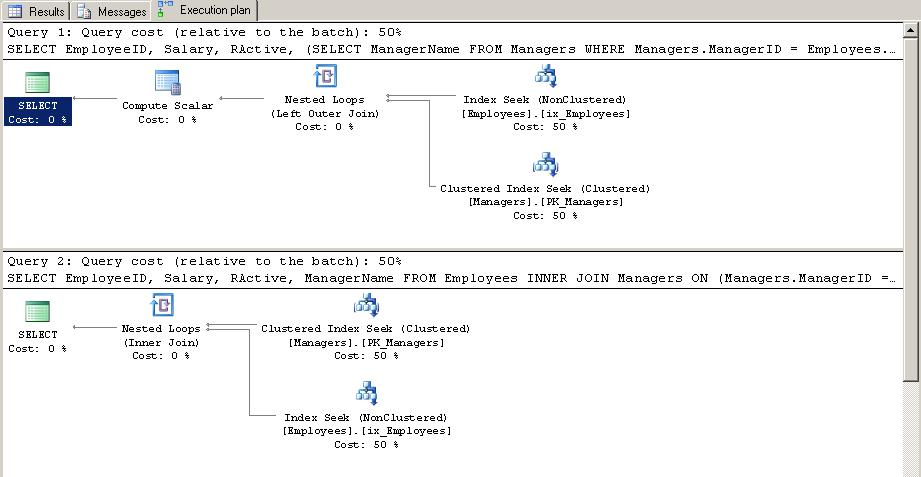
Execution plans for Tests 3 & 4.
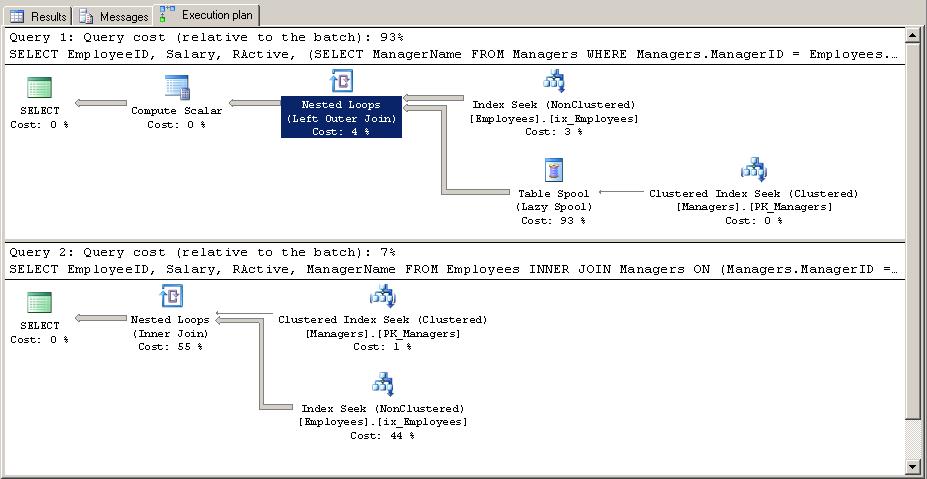
Although the same queries performed identically when retrieving one row, the result is much different now as the query cost suggests. This is because, when executing the query using the sub query expression (Test 3), the query optimizer introduced a table spool operator as a temporary lookup table for the selected manager and each row returned from the Employee table was evaluated x times, i.e. 40000 times in this case.
Only one row was passed from the Clustered Index Seek on the Managers table to the Table Spool Operator. However, the cost for this operator is 93% of the total cost. Expanding the properties for this operator, it's interesting to notice the actual Rebind and Rewinds counts, whose summation equals the total number of rows returned or the number of lookups performed on the temporary table to retrieve the manager name.
--> The table spool operator is a hidden table in tempdb which is used for query processing. This operator will physically create a temporary table, thus more IO is involved, resulting in slower processing, resulting in a larger query cost.
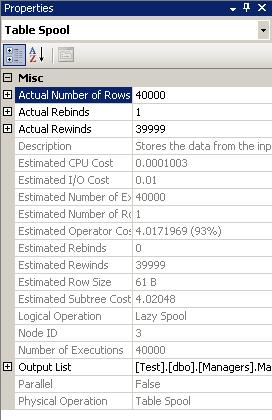
What happened here was that the Table Spool Operator was populated with the Manager name for ID 1 (Estimated No of Rows = 1), and the sub query expression used this operator to evaluate the Manager name for the 40000 rows returned (Rebind count = 1, Rewind count = 39999).
--> It's outside the aim of this article to explain in detail the Rebind and Rewind counts, however a very good explanation can be found in the book I've mentioned at the end of this article.
Conclusion
The aim of this article is to demonstrate that although both methods do return the correct results, and both work almost identically when returning a small number of rows, it's always wise to first verify in what circumstances the queries will be used since as demonstrated, when the number of rows returned is large, one solution will work better than the other.
References
Sub query fundamentals: http://msdn.microsoft.com/en-us/library/ms189575.aspx
Table Spool Operator: http://msdn.microsoft.com/en-us/library/ms181032.aspx
An Excellent description of SQL Server execution plans can be found in the book 'Dissecting SQL Server Execution Plans' by Grant Fritchey (Published by Simple-Talk Publishing).
