
This Stairway covers the details of SQL Server transactional and merge replication, from understanding the basic terminology and methodology of setting up replication, to describing how it works and how the basic replication processes can be monitored. To make the most of this article, you'll need an understanding of SQL Server data modification operations and fluency with using SQL Server Management Studio (SSMS). Level 5 assumes you are familiar with the contents of Levels 1-4.
Previous levels of this Stairway discussed how to set up replication in a multi-server environment. The terms distributor, publisher and subscriber were introduced and explained together with the distribution database, the publication database and the subscription database. Also the Replication agents were briefly described. This level is concerned with the replication agent: what it is, and what role it plays in the transactional replication process.
Agents and Jobs
Transactional replication is not executed by the SQL Server Database Engine itself. Instead it is driven by several external services. These services are referred to as the SQL Server Replication Agents.
The agents are the Snapshot Agent, the Log-Reader Agent and the Distribution Agent. Bidirectional replication also utilizes the Queue-Reader Agent. The Queue-Reader Agent is used to apply changes that were made on a subscriber to the publisher. For more information on the Queue-Reader Agent check out Books Online.
The agents are Windows programs that connect to the servers involved in your replication scenario and facilitate the data movement. In a standard installation of replication, the agent processes are executed by the SQL Server Agent. SQL Server Agent has a separate job step type for each replication agent type.
Besides the replication agent jobs, there are a few additional jobs that get created during the setup of transactional replication. Those jobs are mainly tasked with cleanup and problem detection duties. More details about each of these jobs will be discussed below.
The Jobs get created at various steps during the setup of replication. The following sections describe which job is created as part of which step.
Local Distribution
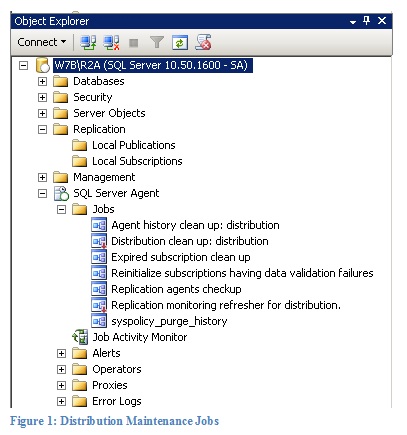
When you setup a server to be a distributor several jobs get created. Figure 1 shows the complete list. Only the syspolicy_purge_history is not part of replication. All other jobs shown in Figure 1are maintenance jobs created by replication.
Remote Distribution
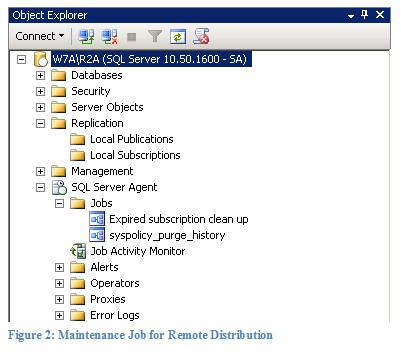
When you setup remote distribution on a publisher, only one maintenance job is created. It is shown in Figure 2. It is tasked with removing the metadata of expired subscriptions on the publisher.
Publication
The next step in a replication install is to create a publication. That creates two new jobs on the distributor and none on the publisher. The result is shown in Figure 3. These two jobs, “W7A\R2A-ReplA-1” and “W7A\R2A-ReplA-MyFirstPublication-1” represent the Log Reader and the Snapshot Agent.

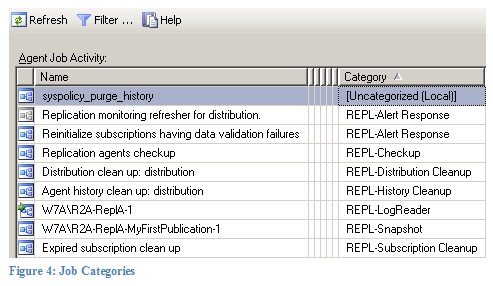
You can tell which job represents which replication agent by looking at the category column in the SQL Server Agent Job Activity Monitor. This is shown in Figure 4.
Push Subscription
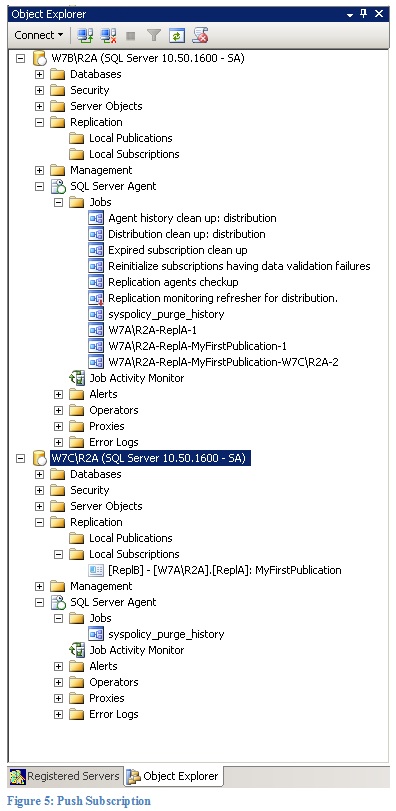
For each subscriber one additional job is created. This job represents the distribution agent. In case of a push subscription the job is created on the distributor. You can see an example in Figure 5. The name of the distribution agent job here is “W7A\R2A-ReplA-MyFirstPublication-W7C\R2A-2”. In Figure 5 you can also see that in case of a push subscription no replication job is created on the subscriber. All Agents live on the distributor in this subscription model.
Pull Subscription
In case of a pull subscription the distribution agent lives on the subscriber. Therefore the last job is created there too. A pull subscription setup is shown in Figure 6. Here the name of distribution agent job is “W7A\R2A-ReplA-MyFirstPublication-W7C\R2A-ReplB-3E02694F-8281-4EBA-81CE-185B3BDE0830”.
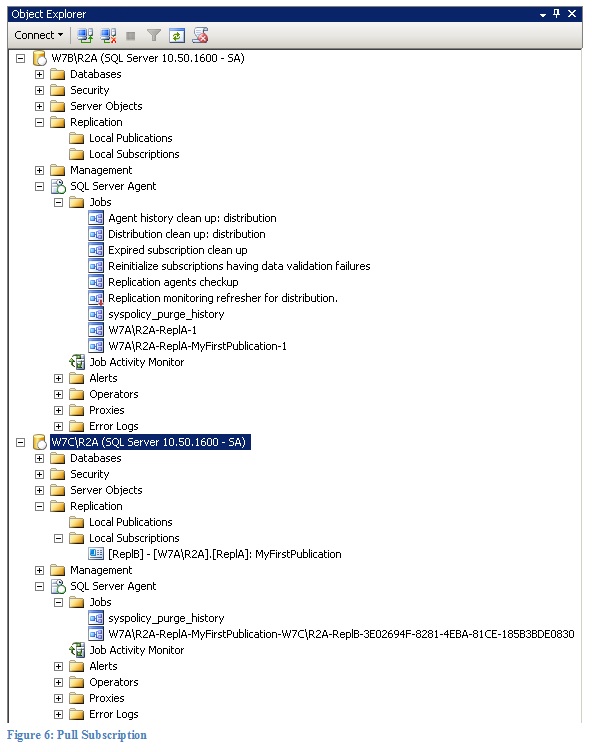
Again, if you want to identify the job that is running the distribution agent you can refer to the category column in the SQL Server Agent Job Activity Monitor. This is shown in Figure 7.
Agents
At first glance, there seem to be an overwhelming number of jobs and agents, each doing different things at different times. However, when you look more closely, there are really only three main players involved in transactional replication: the Snapshot Agent, the Log Reader Agent and the Distribution Agent.Figure 8 gives an overview over the three agents.
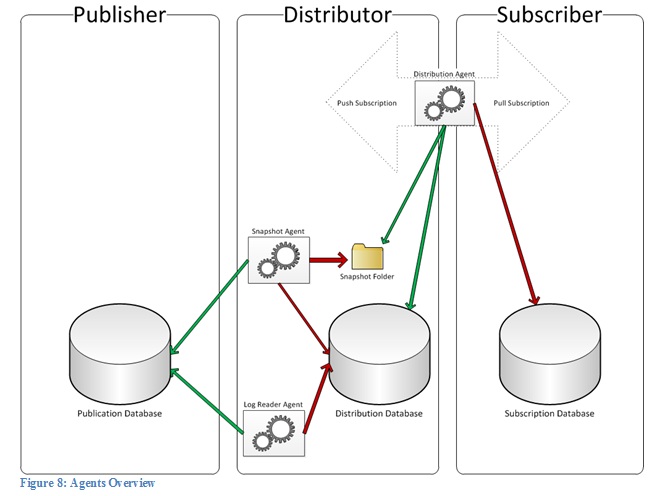
The green arrows depict read access while the red arrows show where write access is happening. The Distribution Agent lives either on the Distributor or the Subscriber, depending on the subscription model.
Snapshot Agent
The Snapshot Agent is the main player in snapshot replication. In transactional replication as well as all other replication types, the snapshot agent is used for the initial synchronization of all replicated objects. While this is not the only way to execute the initial synchronization, it is certainly the most convenient way.
Generating a snapshot involves two steps. First the snapshot agent generates drop and creation scripts for all replicated objects on the subscriber side and places them in the snapshot folder. After that it generates BCP files of the data in all published tables. A record of all generated files is kept in the distribution database.
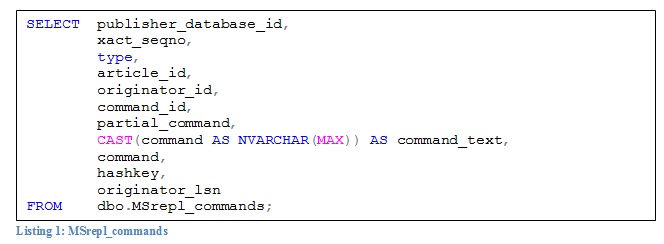 You can run the statement in Listing 1 to see the entries for each BCP file.
You can run the statement in Listing 1 to see the entries for each BCP file.
For snapshot replication a shared lock is kept on all published tables while the BCP files are generated,. This allows the snapshot agent to guarantee transactional consistency of the data, but it blocks all other requests that are trying to write to any of those tables at the same time. Depending on the size of the tables involved this time can be quite substantial. In snapshot replication this is the only way to guarantee transactional consistency.
However, in transactional replication the shared table locks are not required. As of SQL Server 2005, if Transactional Replication is setup through the SSMS GUI, SQL Server uses a different method of generating the snapshots, which allows greater concurrency. This allows changes to the tables to happen while the snapshot is generated. Transactional consistency is guaranteed using the mechanism described here:
- When the snapshot process starts, a table lock is taken on all tables involved in the publication. Then a marker indicating the beginning of the snapshot process is written into the log file of the publication database. After that marker is written the locks are released. The BCP files are then generated without the table locks in place; however more fine-grained short-lived locks on the page and row levels are still used.
- After the BCP file creation finishes another marker is written into the log file of the publication database. It marks the end of the snapshot process. All committed changes to the replicated tables that are recorded in the log file between those two markers are then copied to the distribution database by the Log-Reader Agent like any other transaction log entry.
- When it is time to apply the snapshot to the subscription database, the tables are dropped and recreated using the above mentioned scripts in the snapshot folder. Then the data from the BCP files in the snapshot folder is applied to those tables while a table lock is held on all of them. With the table locks still in place, as the last step, the distribution agent uses the log data that captured the activity during the snapshot generation to bring all tables in a transactionally consistent state.
By default SQL Server creates a new SQL Agent job to execute the Snapshot Agent for every publication . These jobs are named following this pattern: <Server>-<Publication Database>-<Publication>-<number>. If you need a new snapshot to be generated you can manually start the Snapshot Agent Job for the publication, or you can schedule it to run at a later time.
Log-Reader Agent
The Log-Reader Agent is responsible for copying the transaction log records to the distribution database for all transactions that changed published database objects. Every time a change happens to any object in a database, SQL Server first writes a record to the transaction log for the database. After that it applies the change to the actual data pages. When the transaction is committed, SQL Server forces the log records to disk before signaling success. This process is an integral part of any ACID compliant relational database management system.
The process records the information that is necessary to apply the change to the data pages. If for example a power outage occurs before all data pages have been written to disk but after the transaction committed, these log records allow SQL Server to redo the change and finish the write operation upon restart.
The same information is used by the replication system to apply all changes that affected a published object in the publication database to the target object in the subscription database.
If either a DML change (such as INSERT,UPDATEor DELETE) or a DDL change (such as ALTER TABLE) runs against a published object in the publication database, the log records for the change to those objects are marked with a replication flag. Records for changes affecting non-replicated objects are not marked, even if they are in the same transaction.
The Log-Reader Agent connects to the publisher and searches the log file for records that are marked with the replication flag and copies all the information to the distribution database, that is necessary to apply the changes to the subscription database. Because of this process, replication can have a significant impact on the size of the database log file(s). A log file is basically a ring buffer. As soon as a page in the file is not required anymore, it can be reused. SQL Server takes care of this automatically, and usually no intervention is required.
As long as a page is still required, this page and all logically following ones cannot be reused. Reasons for a page still being required include long running transactions or outstanding log backups.
With replication an additional reason gets added into the mix. As long as the Log-Reader Agent did not process the records in the log file, they also cannot be reused. There are several reasons that could prevent the Log-Reader Agent processing the records in a timely manner. The most obvious ones are the distributor being down or the Log-Reader Agent not running for some other reason. An overloaded distributor can also cause a delay in log record processing.
SQL Server has to grow the log file to be able to continue to function in a situation where the log file pages cannot be reused and the file fills up. Depending on the auto grows setting for the log file this operation can take a significant amount of resources. If the log file cannot grow any further because it has reached its configured maximum size or because the drive it is on is full, SQL Server will prevent any further write access to that database until the problem is resolved.
If you have replication setup, keep an eye out for the size of the log file of your publication database. You can use the query in Listing 2 to see if replication is preventing log record reuse. If the log_reuse_wait_desc column contains the value ‘REPLICATION’, replication is the reason for unexpected log growth.

During setup of the first publication in a publication database SQL Server creates a single SQL Agent Job to execute the Log-Reader Agent. The name of this job follows this pattern: <Publisher>-<Publication Database>-<number>. All other publications in the same publication database will reuse this job.
This job is scheduled by default to start together with SQL Server. That means that it is always running which is, in light of the discussion about log reuse above, the preferred way of execution, and you should not change this behavior.
Distribution Agent
The Distribution Agent is responsible for moving the data from the distribution database to the subscription database. The Distribution Agent connects to the distributor and reads the recorded changes. Then it connects to the subscriber and applies those changes in the same order in which they occurred. The order is guaranteed within a single subscription. However, if you have two publications on distinct objects in the same database and subscriptions of these publications with the same subscription database, the order is only guaranteed within each publication, not between statements that belong to separate publications.
By default, SQL Server creates a job for each subscription to execute the Distribution Agent. This job executes either on the distributor (“Push Subscription”) or on the subscriber itself (“Pull Subscription”). The push subscription distribution jobs follow this naming convention: <Publisher>-<Publication Database>-<Publication>-<Subscriber>-<number>
The pull subscription distribution job naming convention looks a little different: <Publisher>-<Publication Database>-<Publication>-<Subscriber>-<Subscription Database>-<GUID>
Jobs
As mentioned in the beginning of this article, there are a few additional jobs required by the replication system that you should be aware of:
- Agent history clean up:
<distribution database name> - The agent history clean up job removes all history records that keep track of the agents’ performance from the distribution database. It uses the “history retention” setting of the distribution database to determine which records to delete.
There is one job of this type for each distribution database on the distributor.
- Distribution clean up:
<distribution database name> - This job removes old transaction information from the distribution database. It checks if all subscribers got each record and then determines based on the result of that check and the replication retention settings which records to delete. Subscriptions that failed to read the transaction information in time get disabled by this job. This job also regularly refreshes the statistics on the tables in the distribution database.
There is one job of this type for each distribution database on the distributor.
- Expired subscription clean up
- This job removes subscriptions that fail to connect to the subscriber within the “publication retention period”. This job runs on the distributor as well as on the publisher.
Each server has only one instance of this job.
- Reinitialize subscriptions having data validation failures
- This job identifies subscriptions with data validation errors and sets them up for re-initialization. Data validation is a process that you can use to verify data consistency between publisher and subscriber. For more information consult Validating Replicated Data in Books Online.
- Replication agents checkup
- This job monitors the replication agents. It will create an entry in the Windows Event Log if any of the agents fail to report their status in the distribution database.
- Replication monitoring refresher for
<distribution database name>
The replication monitor uses this job to refresh cached queries.
Summary
In this Level 5, I described the internals of the replication agents. We looked at the purpose of each replication agent in detail. We also discussed the replication helper jobs and what the tasks they perform.