

The bulk-logged recovery model is probably the least well understood of the three recovery models that SQL Server offers, both in what it actually does in terms of log records and in how it affects database recoverability. In my previous article on recovery models I glossed over the details of bulk-logged recovery and minimally logged operations. In this article, I want to dive into the details of both.
Minimally logged operations
The exact definition of minimally logged operations can be a matter of debate. One definition of minimally logged operations state that they are operations that log only the pages affected and not the rows affected. However, both the DROP TABLE and TRUNCATE TABLE statements log only page deallocations in all recovery models, and they are not classified as minimally logged operations for the purposes of different behaviour in the bulk-logged recovery model. For the list of exactly what operations can be minimally logged, see http://msdn.microsoft.com/en-us/library/ms191244%28v=sql.100%29.aspx.
Kalen Delany defined minimally logged operations as ones that log only enough information to roll back the transaction, without supporting point-in-time recovery (SQL Server 2008 Internals, Chapter 4, page 199) and Books Online gives a very similar definition of logging only the information that is required to recover the transaction. For the purposes of this article, I’m going to use Kalen’s definition and explore exactly what she means.
Let’s take a look at the log and see what exactly is meant by “only logging the information necessary to roll back or recover the transaction”. I’m going to take an operation that can be minimally logged and run it in both full recovery and bulk-logged recovery and see what the logging difference is.
In SQL 2008, SELECT INTO statements can be minimally logged (http://msdn.microsoft.com/en-us/library/ms191244%28v=sql.100%29.aspx) so I’ll use that to see what the logging differences are.
I’m going to use the SELECT INTO statement to insert 200 rows of 2000 bytes each. So 4 rows per page, 50 pages in total (excluding allocation pages).
First up, full recovery model:
CREATE DATABASE FullRecovery
GO
ALTER DATABASE FullRecovery SET RECOVERY FULL
GO
BACKUP DATABASE FullRecovery TO DISK = 'D:\Develop\Databases\Backups\FullRecovery.bak'
GO
USE FullRecovery
go
SELECT TOP (200) REPLICATE('a',2000) AS SomeCol
INTO SomeTable
FROM sys.columns AS c;
SELECT Operation, Context, AllocUnitName, Description,[Log Record Length], [Log Record]
FROM fn_dblog(NULL, NULL)
If we examine the transaction log, what appears are sets of LOP_FORMAT_PAGE log records. These appear in sets of 8 (other than for the first set, which is just 7 pages) and are 8276 bytes long each. So each one contains the image of an entire page, plus log headers, and in sets of 8 it means SQL was processing the insert one extent at a time and writing one log record for each page.
Please note that the function fn_dblog is undocumented and hence may change in future versions. While it is quite safe (all it does is read the transaction log), it should not be used in a production environment.
I’m not going to post the entire log output here, as it is very large, so just a small portion of it showing one set of 8 pages:
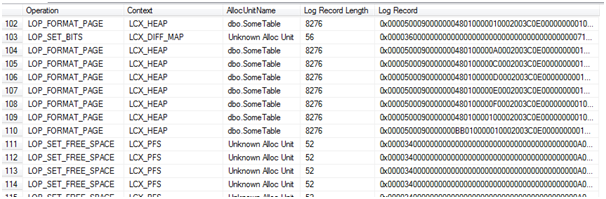
A closer examination of the [Log Record] column shows large sections of the hex value 0x61. This translates to decimal 97 which is the ASCII value for ‘a’. So that’s the actual data rows in the log file:

Let’s see bulk-logged recovery model:
CREATE DATABASE BulkLoggedRecovery
GO
ALTER DATABASE BulkLoggedRecovery SET RECOVERY BULK_LOGGED
GO
BACKUP DATABASE BulkLoggedRecovery TO DISK = 'D:\Develop\Databases\Backups\BulkLoggedRecovery.bak'
GO
USE BulkLoggedRecovery
go
SELECT TOP (200) REPLICATE('a',2000) AS SomeCol
INTO SomeTable
FROM sys.columns AS c;
SELECT Operation, Context, AllocUnitName, [Log Record Length], [Log Record]
FROM fn_dblog(NULL, NULL)What we get this time is a very different set of log records. There are no LOP_FORMAT_PAGE log records at all:
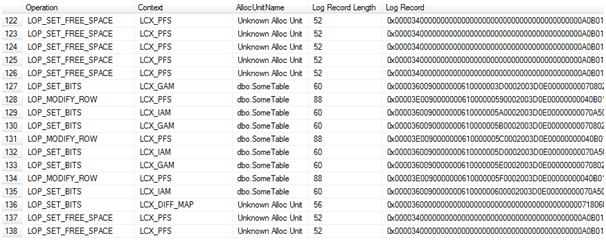
The page allocations are logged, the modifications to the allocation bitmaps and PFS pages, but the pages themselves are not there. There is no reference in the log as to what data is on those pages that were allocated. The 0x61 pattern that appeared in the log records in full recovery are not here and the log records are under 100 bytes in size.
So now we can take another look at the definition of a minimally logged operation with a better understanding. A minimally logged operation logs enough information to roll the transaction back. We can see that from the log records. To roll back or undo the SELECT INTO, all that needs to be done is deallocate the pages. Since the page allocations are logged, that’s possible. To redo (roll forward) the transaction is another matter. The log records can be used to re-allocate the pages, but there is no way, from what is logged, that the contents of the pages can be recreated when the select into was minimally logged.
Implications of minimally logged operations
The obvious question is: “What implications does this have?” Well there are two times that SQL will need to redo transactions:
- Crash recovery (restart recovery)
- Restores
Let’s look at these one at a time.
Crash Recovery
Crash recovery, also called restart recovery, is a process that SQL performs on a database when it is brought online. If the database was not cleanly shut down, then SQL goes through the database’s transaction log. It undoes any transaction that had not committed at the time of the shutdown and redoes any transaction that had committed but whose changes had not been persisted to disk.
This is possible because the log records associated with a data modification must be written to disk before either the transaction commits or the data modification is written to disk, whichever happens first. The changes to the data file can occur any time either before the transaction commits or after via the Checkpoint or Lazy Writer. Hence, for normal operations (ones that are fully logged), SQL has sufficient information in the transaction log to tell whether an operation needs to be undone or redone, and has sufficient information to do the roll forward or rollback.
For operations that were minimally logged, however, roll forward is not possible - there’s not enough information in the log. So, when dealing with minimally logged operations in simple or bulk-logged recovery model, another process guarantees that the extents that were modified by the minimally logged operation are hardened on disk before the transaction is complete. This is known as an Eager Write, and is done by the thread that is executing the bulk operation. This is in contrast to normal operations where only the log records have to be hardened before the transaction is complete and the data pages are written later by a system process (lazy writer or checkpoint).
This means that crash recovery will never have to redo a minimally logged operation since the modified data pages are guaranteed to be on disk at the time the transaction commits and hence the minimal login has no effect on the crash recovery process.
One side effect of this requirement that both log records and modified data pages are written to disk before the transaction commits is that it may actually result in the minimally logged operation being slower than a regular transaction if the data file is not able to handle the large volume of writes. Minimally logged operations are usually faster than normal operations, but that is not guaranteed. The only thing that is guaranteed is that they write less information to the transaction log.
Restores
The second place that a redo occurs is when restoring full, differential or log backups. I’m not going to touch on full and differential backups here, they are not a problem because for a minimally logged operation the affected pages are on disk at the point the transaction completes.
Log backups are more interesting. If the log backup only contained the extent allocation log records, then there would be no way to recreate contents of the extents that the minimally logged operation affected when the log backup was restored. This is because, as we saw earlier, the log does not contain the data that was inserted, just the extent allocations and metadata.
What’s done to facilitate the restores is that, when there are minimally logged operations in the log and a log backup occurs, it’s not just the log records that are backed up. The log backup also includes the images of the extents (sets of 8 pages) that were affected by the minimally logged operation. Not the pages as they were after the minimally logged operation, but the pages as they are at the time of the log backup.
So if we have a timeline like this, where at (1) a minimally logged operation (let’s say a bulk insert) affected pages 1308 – 1315 among others, at (2) an update affected pages 1310 and 1311 and at (3) a log backup occurred

The log backup at 10:30 backs up the log records covering the period 10:00-10:30 and, because there was a minimally logged operation within that log interval, copies the extents that were affected by the minimally logged operations into the log backup. It copies them as they appear at the time of the log backup, after they were affected by both the bulk insert and the update.
SQL Server knows what extents need to be copied into the transaction log. When an extent is affected by a minimally logged operation, a bit is set in an allocation page, called the ML map or bulk-logged change map, to indicate that the extent needs to be copied into the next transaction log backup. The next log backup will then clear the ML map.
This requirement of including the pages in the log backup and taking the copies of the pages only at the point of the log backup affects how the log can be restored.
Restoring to a point-in-time
If I wanted to take that 10:30 log backup and do a restore with STOPAT 10:15 (a time between the minimally logged operation and the update), SQL is not going to walk the rest of the log backup figuring out what operations it needs to undo on the pages that were affected by the minimally-logged operation. It has a simpler reaction:
Msg 4341, Level 16, State 1, Line 2
This log backup contains bulk-logged changes. It cannot be used to stop at an arbitrary point in time.
As soon as there is a minimally-logged operation within a log backup, that log backup can only be restored entirely or not at all. So let’s say we have the following set of backups of a database in bulk-logged recovery model, and a minimally logged operation occurred at 10:05 (and assume for the purposes of this that no other minimally logged operations occurred):
- 05:00 – full backup
- 06:00 – log backup
- 07:00 – log backup
- 08:00 – log backup
- 09:00 – log backup
- 10:00 – log backup
- 11:00 – log backup
- 12:00 – log backup
- 13:00 – log backup
Given that set of log backups, that database can be restored to absolutely any time between the completion of the full backup and 10:00, or any time at all between 11:00 and 13:00 but it cannot be restored to a point between 10:00 and 11:00 because of the minimally logged operation. If a restore was required to reverse an accidental delete at 10:55, the only option would be to restore to 10:00 and accept that any changes between 10:00 and 10:55 be lost.
This inability to restore the database to point-in-time if there are minimally logged operations within the log interval is something that must be considered when choosing to run a database in bulk-logged recovery, either for short or long periods. While some minimally logged operations are obvious (bulk insert, bcp or index rebuilds), others are not. For example, Insert...Select can be minimally logged under some circumstances in SQL 2008. (See http://msdn.microsoft.com/en-us/library/ms191244%28v=sql.100%29.aspx for details.)
Identifying whether a specific log backup contains any minimally logged operations is easy. A Restore HeaderOnly returns a set of details about the backup in question, including a column HasBulkLoggedData. Also, the msdb backupset table has a column has_bulk_logged_data. If the column value is 1, then the log backup contains minimally logged operations and can only be restored entirely or not at all. That said, finding this out while planning or executing a restore may be an unpleasant surprise.
Tail-log backups
The second implication of needing to copy the pages into the log backup file has to do with database recovery in the case of a disaster.
If I have a database in full recovery model, I’m taking regular log backups, and some disaster damages the data file severely enough that the database becomes unavailable (say a complete drive failure), I can take what’s called a tail-log backup (BACKUP LOG ... WITH NO_TRUNCATE) if the log file is still available even though the data file is completely unavailable. With the existing backups (full, perhaps differentil and then log) and the tail log backup, I can restore the database up to the exact point that it failed. I can do that because the log contains sufficient information to completely recreate all of the committed transactions.
However, in bulk-logged recovery that may not be true. If there are any minimally logged operations, then the log does not contain sufficient information to completely recreate all of the committed transactions and the actual data pages are required to be available when the log backup is taken. If the data file is not available, then that log backup cannot copy the data pages it needs to restore a consistent database.
Let’s see how this works:
CREATE DATABASE BulkLoggedRecovery
GO
ALTER DATABASE BulkLoggedRecovery SET RECOVERY BULK_LOGGED
GO
BACKUP DATABASE BulkLoggedRecovery TO DISK = 'D:\Develop\Databases\Backups\BulkLoggedRecovery.bak'
GO
USE BulkLoggedRecovery
go
SELECT TOP (200) REPLICATE('a',2000) AS SomeCol
INTO SomeTable
FROM sys.columns AS c;
GO
SHUTDOWN WITH NOWAIT
GOThe shutdown is so that I can go and do nasty things to the data file for that DB without having to resort to things like pulling USB drives out.
With the SQL Server service shut down, I’m going to go to the data folder and delete the mdf file for the BulkLogged database, then restart SQL. It’s not a complete simulation of a drive failure, but its close enough for the purposes of this demo.
When SQL restarts, the database is not available. No surprise, its primary data file is missing. The state is Recovery_Pending, meaning that SQL couldn’t open the database to run crash recovery on it.
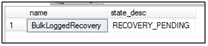
Let’s see what happens if I try to take a tail-log backup (note that no_truncate implies copy_only and continue_after_error):
BACKUP LOG BulkLoggedRecovery TO DISK = D:\Develop\Databases\Backups\BulkLoggedRecovery_tail.trn' WITH NO_TRUNCATE
Processed 4 pages for database 'BulkLoggedRecovery', file 'BulkLoggedRecovery_log' on file 1.
BACKUP WITH CONTINUE_AFTER_ERROR successfully generated a backup of the damaged database. Refer to the SQL Server error log for information about the errors that were encountered.
BACKUP LOG successfully processed 4 pages in 0.022 seconds (1.376 MB/sec).
Well, it said that it succeeded (and despite the warning, there were no errors in the error log). Now, let’s try and restore this DB:
RESTORE DATABASE BulkLoggedRecovery FROM DISK = 'D:\Develop\Databases\Backups\BulkLoggedRecovery.bak' WITH NORECOVERY RESTORE LOG BulkLoggedRecovery FROM DISK = 'D:\Develop\Databases\Backups\BulkLoggedRecovery_tail.trn' WITH RECOVERY
Processed 184 pages for database 'BulkLoggedRecovery', file 'BulkLoggedRecovery' on file 1.
Processed 2 pages for database 'BulkLoggedRecovery', file 'BulkLoggedRecovery_log' on file 1.
RESTORE DATABASE successfully processed 186 pages in 0.074 seconds (19.597 MB/sec).
Msg 3182, Level 16, State 2, Line 2
The backup set cannot be restored because the database was damaged when the backup occurred. Salvage attempts may exploit WITH CONTINUE_AFTER_ERROR.
Msg 3013, Level 16, State 1, Line 2
RESTORE LOG is terminating abnormally.
Well that didn’t work. Let’s see about restoring the log with continue_after_error:
RESTORE DATABASE BulkLoggedRecovery FROM DISK = 'D:\Develop\Databases\Backups\BulkLoggedRecovery.bak' WITH NORECOVERY RESTORE LOG BulkLoggedRecovery FROM DISK = 'D:\Develop\Databases\Backups\BulkLoggedRecovery_tail.trn' WITH RECOVERY, CONTINUE_AFTER_ERROR
Processed 184 pages for database 'BulkLoggedRecovery', file 'BulkLoggedRecovery' on file 1.
Processed 2 pages for database 'BulkLoggedRecovery', file 'BulkLoggedRecovery_log' on file 1.
RESTORE DATABASE successfully processed 186 pages in 0.075 seconds (19.335 MB/sec).
Processed 0 pages for database 'BulkLoggedRecovery', file 'BulkLoggedRecovery' on file 1.
Processed 4 pages for database 'BulkLoggedRecovery', file 'BulkLoggedRecovery_log' on file 1.
The backup set was written with damaged data by a BACKUP WITH CONTINUE_AFTER_ERROR.
RESTORE WITH CONTINUE_AFTER_ERROR was successful but some damage was encountered. Inconsistencies in the database are possible.
RESTORE LOG successfully processed 4 pages in 0.003 seconds (10.091 MB/sec).
That worked, so let’s see about the state of the database. The table that was the target of select...into exists, so let’s see if any of the data made it into the table (remember, the page allocations were logged, the contents of the pages were not.

Not good. Let’s see what CheckDB says about the state of the DB
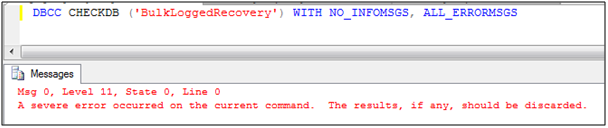
Not good at all. About the only sensible option here is to restore again and leave off the tail-log backup. It means that any transactions that committed between the last normal log backup and the point of failure are lost.
This is a second thing to consider carefully before choosing to run a database in bulk-logged recovery model for long or short periods.
Advantages
So given all of the scary possibilities, why would anyone ever run a database in bulk-logged recovery at all? Well, it has to do with the amount of log space used by these operations.
Let’s take an index rebuild for example (it can be minimally logged). In full recovery model the index rebuild requires log space >= size of the table. For large tables, that can be a huge impact on the log. It’s a very common forum question – “I rebuild my indexes and my log grew huge/ran out of space.”
In bulk-logged recovery, only the page allocations for the new index are logged, so the impact on the transaction log can be substantially less than it would in full recovery. Similarly for large data loads via bcp or bulk insert or for copying data into new tables via SELECT ... INTO or INSERT INTO ... SELECT.
To get an idea just how much of a difference this makes, I’m going to rebuild a clustered index (consisting of 231885 pages) in both full and bulk-logged recovery models and see how much log space the index rebuild needs.
I’ll check the amount of log space with the sys.dm_tran_database_transactions DMV. The code that will be run in both recovery models is:
BEGIN TRANSACTION
ALTER INDEX ALL ON dbo.PrimaryTable_Large REBUILD
-- there's only the clustered index
SELECT session_id ,
d.recovery_model_desc ,
database_transaction_begin_time ,
database_transaction_log_record_count ,
database_transaction_log_bytes_used
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st ON dt.transaction_id = st.transaction_id
INNER JOIN sys.databases AS d ON dt.database_id = d.database_id
COMMIT TRANSACTIONFull recovery:

So 40 seconds (give or take) and about 1.8GB of log space used for the 232 thousand log records (and I’m ignoring the log reservation in case of rollback, so the total log space required is larger).
Bulk-logged recovery:

Only 27 seconds this time, however the data and log files are both on a single drive, so not much can be concluded from that time difference. The main point here is the difference in the log space used. In bulk logged recovery, that index rebuild only used 6.3 MB of log space, compared to the 1.8 GB of log space in full recovery. That’s a major saving (and this was not that large a table even, only 1.8 GB in size).
Oh, and in case anyone’s curious about simple recovery:

Just about the same as bulk-logged recovery, this is expected since operations that are minimally logged in bulk-logged recovery are minimally logged in simple recovery as well.
This is the major reason for running a database in bulk-logged recovery, it gives both the database recovery options of full recovery (mostly, subject to the cases looked at above), but it reduces the amount of log space used by certain operations, just as simple recovery does.
If the database is a log shipping primary, the database cannot be switched into simple recovery for index rebuilds without having to redo the log shipping afterwards, but it can be switched to bulk logged for the index rebuilds.
Note that database mirroring requires full recovery only and as such a database that is a database mirroring principle cannot use bulk-logged recovery.
Guidelines for Bulk-logged Recovery
The main guideline for bulk-logged recovery is: ‘as short a time as possible’.
Due to the implications for point-in-time restores and restoring to point of failure, if a database is switched to bulk-logged recovery in order to minimally log some operations, it should stay in bulk-logged recovery for the shortest time possible.
It is not necessary to take any backups after switching the database from full recovery to bulk-logged recovery. Like with a switch to simple recovery, it’s effective immediately. Similarly, it is not necessary to take any backups when switching back to full recovery.
That said, it is strongly recommended to take a transaction log backup immediately prior to switching to bulk-logged recovery and another transaction log backup immediately upon switching back to full recovery. The point of these log backups is to ensure that the absolute smallest amount of time and smallest number of transactions are within a log interval that contains minimally logged operations, to reduce the risks associated with bulk-logged recovery as much as possible
Conclusion
The bulk-logged recovery model offers a way of performing data loads and some database maintenance operations such as index rebuilds without the transaction log overhead that they would normally have in full recovery model while still keeping the log chain intact. The downsides of this include greater data loss potential if a disaster occurs during the bulk operation.
When using bulk-logged recovery, the increased risks of data loss should be kept in mind and the recovery model used only for the duration of the maintenance or data load operations and not as a default recovery model.
Even with the increased risks it is a viable and useful option and is something that DBAs should consider when planning data loads or index maintenance.
Acknowledgements
Thanks to Jonathan Kehayias (blog|twitter) for doing a technical review of this article, and to Gus Gwynn (GSquared), Jason Brimhall (SQLRnnr) and Wayne Sheffield for doing a general review.


