

Introduction
Imagine you've got at hand a huge task. You'd naturally want to have multiple persons working in parallel on the task to finish it as early as possible, but there are some considerations required to ensure that the task "actually" gets done quickly.
- You need to ensure that no two persons are doing the "same" job (for example two employees processing the payment of the same customer)
- You need to ensure that no two employees are stuck waiting on each other. For example, if one employee has access to the Account details of a customer, but cannot finish their task until they also get the order details. Meanwhile another employee has taken ahold of the order details and is waiting on account details to finish the job. One of them has to back off for both to complete but that has to be done gracefully.
- The number of employees would be limited by the amount of resources (tools, machines etc.) you have. If you have excess people, they would be required to wait for resources and they would not be able to contribute to parallel processing.
- You need to make sure that the employees are assigned only the tasks they are specialized in. It would be costlier if they are assigned those tasks in which they have no experience working. For example if an employee that is most efficient on sales is asked also to work on the Accounts/Finance details of a customer, his productivity goes down and he also may lose other new customers. Instead it would be effective if he manages just sales, gets the order details of a customer, and puts them in a queue for the Finance people to process, and then moves to another customer. Meanwhile the Finance department can independently process the Accounts and Finances of customers as they come in.
In database terms these considerations would respectively mean the following:
- Database Consistency
- Avoid Deadlocks
- Concurrency and Optimization: Number of parallel processes vs. available resources
- Independent Units of Transactions instead of one single transaction
This article is about handling such issues in the database world (SQL Server to be specific). We shall see how with a help of custom design and T-SQL, a huge dataset can be processed with both high consistency and high concurrency by multiple processes running continuously in parallel. These processes access the same resources (tables) at the same time. But they aren't pre-assigned with any specific identifiers (Row IDs) of the data they are supposed to process. They would have to pick up these identifiers at run time. Under such circumstances it has to be ensured that the processes are not blocking each other and at the same time they are not duplicating each other's efforts i.e. not processing data with the same identifiers.
Problem Statement
Let's state the above requirement in database terms. There is an event table with millions of event records waiting to be processed in a particular order. More records are added to this table at regular intervals. To start processing these records, multiple parallel jobs are employed. They pick up a fixed number of event records at a time from this event table, process them, and then mark them as complete. Once finished with a batch, they pick up the next set of unprocessed records. Each job should ensure that it is not processing the same records that some other parallel job is processing.
Proposed Solution
First we define the size of a batch of records that these jobs would be picking up for processing in every run. Let's assume the batch size is "n" here. The following description is a basic idea of what each job would be doing:
- SELECT TOP n records from the EVENT table INTO a temporary table
- Process the records
- UPDATE the successfully processed records i.e. set their Processed Flag to 1. Alternatively move the processed records to another table.
Thus the first thing each job would do is, fire a "SELECT TOP n..." query on the EVENT table to get the records for processing. A SELECT statement, on its own, places no more than a SHARED lock on the records and hence does not prevent any other parallel SELECT statement from picking up the same unprocessed records. We are considering that each process takes quite some time for processing before it can mark the records as processed. Eventually each parallel job would be processing the same set of records. That would be highly inefficient since the efforts are duplicated.
What we need is an exclusive record lock that would prevent any parallel processing job from picking up the same records. At the same time we have to make sure that any other different process that are just intending to read the data should not be blocked. These things can be achieved by specifying a table hint in the "SELECT TOP n..." query. The following table hints are the relevant commands available for exclusive locking.
Please note that only the relevant Table Hints have been listed. For a list of all Table Hints please refer to SQL Server Books Online.
TABLOCKX: The whole table gets locked exclusively until the transaction completes.
UPDLOCK: An update lock gets placed on the records in the table until the transaction completes. It is compatible with a SHARED lock. By default it tries to lock rows but depending upon the data size, SQL Server can escalate to a Page Lock or a Table Lock.
XLOCK: An exclusive lock gets placed on the records in the table until the transaction completes. It is not compatible with a SHARED lock.
The Best Choice
From the above options, UPDLOCK turns out to be a better option in this situation for the following reasons:
- The entire data processing operation has to be enclosed in a single transaction for these locks to work.
- TABLOCKX puts an exclusive lock on the entire table until the end of the transaction. In that case, the other parallel jobs would have to wait until the first process completes. That would not be acceptable.
- XLOCK is by default at the row level, but it is not compatible with even a SHARED lock. Hence any independent process trying just to read data from the table would have to wait until the data processing is completed.
- UPDLOCK is compatible with a SHARED lock. Hence any process just trying to read data (even the same records) from the table won't be required to wait. On the other hand UPDLOCK is incompatible with itself. Hence any parallel data processing job cannot place an update lock on the same records. That avoids redundancy.
But here again, the parallel data processing job may have to wait until the first job has finished processing because it is trying to SELECT the TOP n records which are locked by the first job for processing. Only after the first job finishes marking the records as processed would the second job be able to pick the next set of records.
To counter this, we can specify the READPAST hint (along with UPDLOCK) in the same SELECT query so that it would skip the locked records and get another set of records for exclusive locking and processing.
Example
Fine! So let's summarize the design discussed so far with the help of an example.
Consider RAINFALL_EVENTS as the event table that refers to the rainfall data entered into the system. This table will hold the RAINFALL ID, which would ultimately guide us to the other details (e.g. Rainfall measurement, Location, Instrument, Day and Time etc) that are distributed across the other tables in the database.
The following would be the fields in the RAINFALL_EVENTS table:
| EVENT_ID | Auto-increment field, PRIMARY KEY with a Clustered index on it |
| RAINFALL_ID | Single Reference to all rainfall related details |
| PROCESSED | Flag indicating whether the event is processed |
Here's the DDL for the table:
IF object_id('Rainfall_Events') IS NOT NULL DROP TABLE Rainfall_Events
CREATE TABLE Rainfall_Events
(Event_ID bigint IDENTITY PRIMARY KEY NOT NULL
,Rainfall_ID bigint NOT NULL
,Processed bit NOT NULL default (0)
)
Populate the table with 10K records. Here's the script to do that.
DECLARE @Rainfall_ID bigint SELECT @Rainfall_ID = 0 WHILE @Rainfall_ID < 10000 BEGIN INSERT RAINFALL_EVENTS(Rainfall_ID) SELECT @Rainfall_ID + 1 SELECT @Rainfall_ID = @Rainfall_ID + 1 END --SELECT * FROM Rainfall_Events
The following could would be the outline of the stored procedure that the processing job would call. The batch size is set as 5, i.e. the value of "n" in our SELECT TOP n query. Thus the procedure selects the top 5 records at one time for processing. After that we introduce a delay of 30 seconds in the procedure to account for the processing time. Therefore 30 seconds is the minimum time that each process would take to finish executing. Finally the procedure marks the records as "Processed", i.e. updates the Processedflag to 1.
--DROP PROCEDURE DataProcessor
CREATE PROCEDURE DataProcessor
AS
BEGIN
IF object_id('tempdb..#Events') IS NOT NULL DROP TABLE #Events
BEGIN TRANSACTION
-- Retrieve data for processing
SELECT TOP 5 * INTO #Events FROM Rainfall_Events WITH (UPDLOCK,READPAST)
WHERE Processed = 0 ORDER BY Event_ID
-- Processing block. Say the time required is 30 seconds
WAITFOR DELAY '00:00:30'
-- Mark the records as processed
UPDATE A SET Processed = 1
FROM Rainfall_Events A JOIN #Events B ON A.Event_ID = B.Event_ID
COMMIT TRANSACTION
--SELECT * FROM Rainfall_Events WHERE Processed = 1
END
Note the UPDLOCK and READPAST hint the SELECT query.
Now execute the same procedure at the same time in two separate windows (as two separate processes) of SQL Server Management Studio as shown in the image below.
EXEC DataProcessor
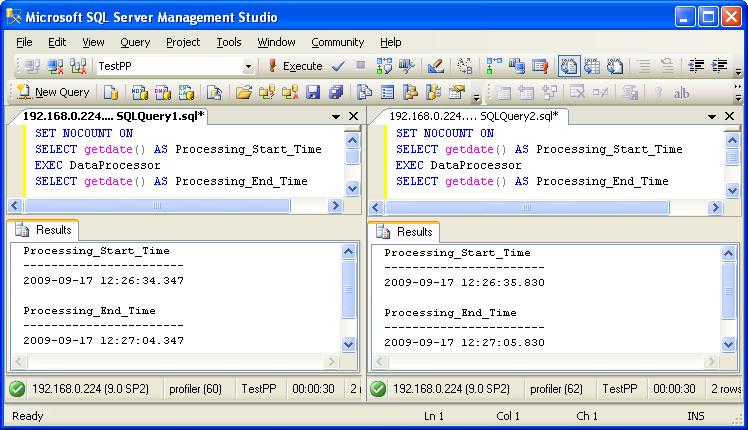
"SELECT getdate()" is done to display the start time and end time of the processes just for demonstration purposes. From the figure it is clear that both the processes started almost at the same time with a small difference of about 1.5 seconds.
Results
You'll see that both the processes finish in 30 seconds time and in all 10 records have been processed, i.e. 5 records by each job. That can be confirmed by the following query:
SELECT * FROM Rainfall_Events WHERE Processed = 1
-- 10 records affected
Just for the sake of testing our other options, we can modify the SELECT TOP 5 query in our procedure to use TABLOCKX hint or only UPDLOCK hint without the READPAST hint and then repeat the same flow to see the results.
SELECT TOP 5 * INTO #Events FROM Rainfall_Events WITH (UPDLOCK)
WHERE Processed = 0 ORDER BY Event_ID
Before executing every option please execute this query to make the EVENT table fresh for each option.
UPDATE Rainfall_Events SET Processed = 0 WHERE Processed = 1
Results:
If both the processes are fired almost at the same time, one process would finish in 30 seconds while the other would take close to 60 seconds to execute. Overall 10 records are processed
Summary So Far
So to summarize so far UPDLOCK and READPAST hints form the best choice because:
- Efforts are not duplicated
- Deadlocks can be avoided by limiting the batch size
- Each Process can go on in parallel as independent transaction hopefully without affecting the other, i.e. as long as the processing job does not acquire a lock on the entire Event table thereby keeping the other job waiting
Problem Statement Part 2
Well, it's not a happy ending yet. This solution does come with some practical issues which are listed as follows:
- The Transaction: As is already mentioned, the entire data processing process has to be enclosed in a single transaction for the locks to be active throughout the process. But the processing could be using a number of business tables for read/write. If this processing spans over more than even a minute, we would have the resources locked for quite an annoying amount of time. Second, processes wanting to acquire a table lock (other than shared) on the event table may have to wait for indefinite amount of time since the jobs would be running continuously.
- Lock Escalation: Coming back to our SELECT TOP n query. If this query happens to get a sizeable number of records, SQL Server may find it appropriate to escalate the lock to a page lock or table lock. In the case of a table lock, the parallel jobs would again have to wait until the 1st job has finished its processing. The worst case could happen when the number of key (row) locks is very high, such as when the batch size is large but the lock isn't escalated to a Table Lock.
To demonstrate this, just alter the DATAPROCESSOR update and set the batch size to 7000 in the SELECT TOP query in DATAPROCESSOR SP. The query becomes:
SELECT TOP 7000 * INTO #Events FROM Rainfall_Events WITH (UPDLOCK,READPAST)
WHERE Processed = 0 ORDER BY Event_ID
Remember to reset the Processed flag to 0 in the RAINFALL_EVENTS table using this query
UPDATE Rainfall_Events SET Processed = 0 WHERE Processed = 1
Now again execute the procedure as two separate processes at the same time. You will find that one process required close to 60 seconds to finish processing. That is because SQL Server escalated the lock to a TABLE Lock. This can be observed by executing the following query in a separate window on the same server on the same DB. Please note that this query has to be executed while processing is going on.
This query is extracted from the code for "sp_lock" system procedure and is tweaked to display locking information related only to Table "RAINFALL_EVENTS". That would give us only relevant results. Alternatively, if the SPID of both the processes are known it would do fine to directly execute the sp_lock System procedure as follows:
exec sp_lock @spid1, @spid2
select convert (smallint, req_spid) As spid,
rsc_dbid As dbid,
object_name(rsc_objid) As ObjectName,
rsc_indid As IndId,
substring (v.name, 1, 4) As Type,
substring (rsc_text, 1, 32) as Resource,
substring (u.name, 1, 8) As Mode,
substring (x.name, 1, 5) As Status from master.dbo.syslockinfo,
master.dbo.spt_values v,
master.dbo.spt_values x,
master.dbo.spt_values u where master.dbo.syslockinfo.rsc_type = v.number
and v.type = 'LR'
and master.dbo.syslockinfo.req_status = x.number
and x.type = 'LS'
and master.dbo.syslockinfo.req_mode + 1 = u.number
and u.type = 'L'
and object_name(rsc_objid) = 'Rainfall_Events'
order by spid
Output of the query

3. Deadlocks: This problem comes when SQL Server doesn't perform a lock escalation even when the batch size is high. The number of KEY (ROW) locks on the table would be the batch size multiplied by the number of parallel executions of the processing SP. Deadlocks could happen over any one of the keys.
To demonstrate this, just alter the DATAPROCESSOR SP to update the batch size to 500 in the SELECT TOP query in DATAPROCESSOR SP. The query becomes:
SELECT TOP 500 * INTO #Events FROM Rainfall_Events WITH (UPDLOCK,READPAST)
WHERE Processed = 0 ORDER BY Event_ID
Remember to reset the Processed flag to 0 in the RAINFALL_EVENTS table using this query
UPDATE Rainfall_Events SET Processed = 0 WHERE Processed = 1
Now again execute the procedure as two separate processes at the same time. One of the threads fails with following deadlock error:
(500 row(s) affected)
Msg 1205, Level 13, State 51, Procedure DataProcessor, Line 17
Transaction (Process ID 64) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
The Soft-Lock Approach
Let me show the solution that I followed to handle this requirement. As many of you would have guessed, it is an option of soft locking, or flagging the records, instantly after they are picked up for processing. We do this by marking the records as "In Process" with the help of an additional field - say Job Process IDthat would indicate that the record is under processing. Other jobs would look out for records with no Job process id allocated yet. A new column would be created in RAINFALL_EVENTS table to store the Job Process ID.
This calls for an immediate UPDATE of the records returned by our SELECT TOP n query to assign @@SPID as value to the new Job Process ID field. This can be achieved as shown in the following query. The SELECT TOP n query forms a derived table and is joined to "RAINFALL_EVENTS" table to get the records for Update.
UPDATE events
SET Process_ID = @@spid
FROM Rainfall_Events events
JOIN (SELECT TOP 5 Event_ID FROM Rainfall_Events WITH (UPDLOCK, READPAST)
WHERE Processed = 0 AND Process_ID IS NULL
ORDER BY Event_ID
) batch
ON events.Event_ID = batch.Event_ID
Lock (SQL Server Lock) is required on the records only when they are being flagged, to ensure that the same records are not picked up by two parallel jobs i.e. when two parallel jobs run the "SELECT TOP n" query exactly at the same time (possible though rare). That is handled by using UPDLOCK and READPAST as discussed earlier and shown in the above query. Once the records are assigned a Process-ID, the lock can be released.
At a first look itself, we see the benefit of not having to enclose the entire job process in a single transaction. Also since individual records are flagged at code level and not "actually" locked we do not have an issue of Lock Escalation.
But again this solution also comes with its own challenges:
Challenges
Since the job takes care of locking the records, it has the responsibility of unlocking the records in case of an unforeseen system failure due to which the records could not be processed. The records if not unlocked, they would remain unprocessed until some other job acquires the same process id and processes those records. That would not be acceptable.
The basic purpose of soft locking would be to keep our event table free most of the time for parallel processing. But as we will see, the table may be required to be a part of data processing logic. And some part (DML) of that data processing logic would definitely be enclosed in a transaction so that it can be rolled back in case of any unforeseen failure. There goes our table into a lock again and hence unavailable.
The Ultimate Solution
Let's now have a look at these "Challenges" in the same order
"With control comes responsibility": You either finish the job (Processing) or either release the control to some other job. But unfortunately our poor processing job has no idea that it's going to crash or else it would have at least sent some signal asking to take control.
So then the responsibility comes on another independent job specialized to reset locks on any orphan recordsthat it may encounter. What are orphan records? These would be the records which are locked for more than a specific period of time and yet are not processed. We can fix some time (say 15 minutes) beyond which we decide that any processing should not go. The reset-orphan-locks job continuously would keep looking for such orphan records. If it finds such records, it would straightaway attempt to update the Job Process ID column of those records to NULL. Some other job would take over those records and resume processing from where the first job had left.
This means that we would have to do a forced stop on slow processing jobs. This also means that we would need to have one more column Locked Time Stamp (along with Job Process ID) in our Event table to store the timestamp when that record was locked.
So what are our processing jobs required to do? They have to keep a track of the time they themselves are taking to finish the process (Current Time minus the Locked Time). If they find that they are taking more than even half the pre-fixed time, they have to rollback and call off their current operation. Before that, they can even release the control on the records and walk out. If they are well within the allotted time, but crash out accidentally, the reset-orphan-locks job would release the records after the allotted time has passed i.e. < (Current Time - Locked Time)
Let's say that the data processing requirement is as follows:
- Pick records from Event table
- Process them: That would include analyzing, mapping, consolidating and organizing the records in a specific universal / generic format.
- Write the processed records to another server (acting as universal homogeneous server)
Consider that the job has finished tasks "a" and "b" within the allotted time, and it is now performing task c. While transferring data across the network, the allotted time may get surpassed (possible in a very slow network). In that case the continuous Reset-Orphan-Locks job would treat those records as Orphan Records and hence release them making them available to some other job for processing. But here the records have already finished processing and are eventually transferred across the network. It would be repetitive erroneous transfer.
That raises the need to lock (SQL Server Lock)the Event table during the time of transfer and release it only when:
- The transfer is complete
- The record is marked as processed
Reset-Orphan-Locks SP would not touch the processed records.
But we may not afford to keep the event table locked for all the time when a transfer across the network is in process. Hence instead of directly transferring the data across the network we would actually be writing data to a local queue table (which would have the same format as the table across the network) and there and then mark the record as processed and release the table.
Data transfer from a queue table to the destination table would be a separate transaction unit. We may also consider deleting the record from the queue table the moment it is moved to the destination table so that the queue table remains small in size and writing to the queue table becomes faster.
Example Continued
The following would now be all the fields in the RAINFALL_EVENTS table:
| EVENT_ID | Auto-increment field, PRIMARY KEY with a Clustered index on it |
| RAINFALL_ID | Single Reference to all rainfall related details |
| PROCESSED | Flag indicating whether the event is processed |
| PROCESS_ID | Job Server Process ID which processes the event |
| LOCKED_TIME | Timestamp indicating when the event was locked by the processing job |
Script to add the new columns to the existing RAINFALL_EVENTS table
ALTER TABLE Rainfall_Events ADD Process_ID int NULL
ALTER TABLE Rainfall_Events ADD Locked_Time datetime NULL
GO
We now need to alter the DATAPROCESSOR SP to incorporate our new design. Let's have a look at it.
--DROP PROCEDURE DataProcessor
CREATE PROCEDURE DataProcessor
AS
BEGIN DECLARE @AllottedTimeInMinutes smallint
,@StartTime datetime SELECT @AllottedTimeInMinutes = 15
,@StartTime = getdate() -- Soft-Lock data. Assign value to Process_ID and Locked_Time
UPDATE events
SET Process_ID = @@spid
,Locked_Time = @StartTime
FROM Rainfall_Events events
JOIN (SELECT TOP 5 Event_ID FROM Rainfall_Events WITH (UPDLOCK, READPAST)
WHERE Processed = 0 AND Process_ID IS NULL AND Locked_Time IS NULL
ORDER BY Event_ID
) batch
ON events.Event_ID = batch.Event_ID -- Take the flagged data into a temporary table for processing.
SELECT * INTO #Events FROM Rainfall_Events WHERE Process_ID = @@spid -- Processing block. Say the time required is 30 seconds
WAITFOR DELAY '00:00:30' -- Processing completed. Transaction begins here
BEGIN TRANSACTION -- Get a quick table Lock on Events table (Shield from Reset_Orphan_Locks SP) SELECT * INTO #LockHelp FROM Rainfall_Events WITH (TABLOCKX) WHERE 1 = 2 -- Now Check whether the process duration has not surpassed the allotted time.
-- If yes Abort the process
IF datediff(mi,@StartTime,getdate()) > @AllottedTimeInMinutes GOTO AbortProcess --We are still in time.
--Write data to a queue table
--Mark the records as processed
UPDATE A SET Processed = 1
FROM Rainfall_Events A JOIN #Events B ON A.Event_ID = B.Event_ID COMMIT TRANSACTION IF object_id('tempdb..#Events') IS NOT NULL DROP TABLE #Events RETURN AbortProcess:
ROLLBACK TRANSACTION
RETURN --SELECT * FROM Rainfall_Events WHERE Processed = 1
END
The Procedure explained
Variables
@AllottedTimeInMinutes: This variable holds the maximum time allotted to complete the processing
@StartTime: This variable marks the start time for processing. The same value goes to the Locked_Time field in the Event table. It would be used to check for the time elapsed during processing.
Soft-Locking
This is the query for flagging the records along with associating the Time when they are being flagged
-- Soft-Lock data. Assign value to Process_ID and Locked_Time
UPDATE events
SET Process_ID = @@spid
,Locked_Time = @StartTime
FROM Rainfall_Events events
JOIN (SELECT TOP 5 Event_ID FROM Rainfall_Events WITH (UPDLOCK, READPAST)
WHERE Processed = 0 AND Process_ID IS NULL AND Locked_Time IS NULL
ORDER BY Event_ID
) batch
ON events.Event_ID = batch.Event_ID
The UPDLOCK will ensure that the records are not picked up by any other job (which may have been running the same query in parallel at the same time). READPAST will ensure that the parallel job is not waiting for the current UPDATE query to finish executing. It will skip the locked records and update the next set of records.
In case the order is not important, we can use the UPDATE TOP (n) feature of SQL Server 2005. An UPDLOCK would not be required in that case.
Post-Processing
After processing we have to mark the records as processed and also may be required to copy the processed / consolidated data to some queue table. Before that we need to shield the table from Reset-Orphan-Locks SP (in case we may surpass the time during the process) and also check for the time already taken for processing. Hence we start a transaction and take a quick exclusive table lock on the table. After that we check for the elapsed time.
BEGIN TRANSACTION SELECT * INTO #LockHelp FROM Rainfall_Events WITH (TABLOCKX) WHERE 1 = 2 IF datediff(mi,@StartTime,getdate()) > @AllottedTimeInMinutes GOTO AbortProcess
If the processing time has gone beyond the allotted time there are high chances that the records have already been reset by the Reset-Orphan-Locks SP. In that case we have to abort the process and not transfer the data lest some other job may already be in the process of transferring the same data.
Please note this case of "processing time exceeding the allotted time" should be a very rare scenario because we would be setting the allotted time considering appropriate buffer in addition to the maximum time that a job would require to finish processing. The Reset-Orphan-Locks commonly comes to help when a particular processing job fails and is not able to finish processing.
If the processing is still within the allotted time, we can safely go ahead with transferring the data and marking the data as processed. After that the transaction would be committed thereby releasing the Event table
UPDATE A SET Processed = 1
FROM Rainfall_Events A JOIN #Events B ON A.Event_ID = B.Event_ID COMMIT TRANSACTION
Final Destination
Through a separate procedure, data from the queue table would be pushed to the final destination table across the network to the other server. Data would then be deleted from the queue table once it is moved.
Reset-Orphan-Locks
With so much discussion going on around about the Reset-Orphan-Locks SP, we definitely have to look at how it is implemented:
-- DROP PROCEDURE [dbo].[Reset_OrphanLocks]
CREATE PROCEDURE dbo.Reset_OrphanLocks
AS
BEGIN DECLARE @AllottedTimeInMinutes smallint
SELECT @AllottedTimeInMinutes = 15 -- Resetting locked records not processed within the allotted time
UPDATE events
SET Process_ID = NULL
,Locked_Time = NULL
FROM Rainfall_Events events
JOIN (SELECT Event_ID
FROM Rainfall_Events WITH (NOLOCK)
WHERE Processed = 0 AND Process_ID IS NOT NULL
AND datediff(mi,Locked_Time,getdate()) >= @AllottedTimeInMinutes
) batch
ON events.Event_ID = batch.Event_ID AND events.Processed = 0 RETURN
END GO
This would be a separate regularly scheduled job which would keep on checking for unprocessed records associated with a job process id for more than a fixed amount of time and then resetting them. To make sure that the update query in this job does not scan through the entire table thereby locking the table for a long time, we first retrieve the relevant records using NOLOCK hint and then join on Event ID of the instance which actually gets updated. Event ID is the primary key with clustered index.
Simulation
First execute the following query to have the data fresh for simulation:
UPDATE Rainfall_Events SET Processed = 0,Process_ID = NULL,Locked_Time = NULL
WHERE Processed = 1
Now, open three windows in SQL Server Management Studio all connected to the database which has the RAINFALL_EVENTS table. In the first two windows, have the following script ready:
WHILE (1 = 1) EXEC DataProcessor
This statement would keep on executing two parallel processing threads continuously. Note the SPID of each of the processing windows. In the third window type the following query
WHILE (1 = 1) EXEC Reset_OrphanLocks
This SP will continuously check for orphan records.
Now execute the scripts in all the three windows. In a separate fourth window check the contents of the RAINFALL_EVENTS table especially the Processed, Process_ID and Locked_Time columns. At any point of time, we would have 10 rows with Processed as 0 and Process ID as NOT NULL. Those are the records which are currently under processing. The records with Processed = 1have finished processing.
The next step would be to close down one of the processing windows thereby forcefully stopping the processing and ending the session. Check for unprocessed records for that session / SPID in the RAINFALL_EVENTS table. There would be 5 such records. After about 15 minutes, the Process_ID of those records would be set to NULL by the Reset_OrphanLocks SP and the same records would be picked up by the 1st session later.
Conclusion
This article thus attempts to demonstrate how large volumes of data can be processed efficiently having multiple parallel processes working at same time. Using T-SQL programming transaction loading can be reduced and resource availability (concurrency) can be improved. Though these processes work independently synchronization and non-redundancy (consistency) can be obtained with the help of some common parameters and not having to really isolate the resources from each other.
Feedback and suggestions would be sincerely appreciated.
