

Introduction
Effective indexing is the key to keeping your queries running quickly while consuming as few resources as possible in the process. Each index that is added to a table will increase the speed of reads that are now able to utilize that index, but at the cost of speed whenever that index needs to be updated. In addition, your index maintenance processes (rebuilding/reorganizing) will now have an additional index to operate on.
SQL Server has no safeguards against indexes that duplicate behavior, and therefore a table could conceivably have any number of duplicate or overlapping indexes on it without your ever knowing they were there! This would constitute an unnecessary drain on resources that could easily be avoided. How do we easily view our current indexes and determine if duplicates exist? What about indexes that contain overlapping column lists that could be combined?
Problem
To illustrate the effect of duplicate indexes, we will start by inserting a row of data into the Production.Product table in AdventureWorks:
SET STATISTICS IO ON
INSERT INTO Production.Product
( Name ,
ProductNumber ,
MakeFlag ,
FinishedGoodsFlag ,
Color ,
SafetyStockLevel ,
ReorderPoint ,
StandardCost ,
ListPrice ,
Size ,
SizeUnitMeasureCode ,
WeightUnitMeasureCode ,
Weight ,
DaysToManufacture ,
ProductLine ,
Class ,
Style ,
ProductSubcategoryID ,
ProductModelID ,
SellStartDate ,
SellEndDate ,
DiscontinuedDate ,
rowguid ,
ModifiedDate
)
VALUES ( 'Test Product 1' , -- Name - Name
N'12345' , -- ProductNumber - nvarchar(25)
0 , -- MakeFlag - Flag
0 , -- FinishedGoodsFlag - Flag
N'Flurple' , -- Color - nvarchar(15)
100 , -- SafetyStockLevel - smallint
50 , -- ReorderPoint - smallint
0 , -- StandardCost - money
0 , -- ListPrice - money
NULL , -- Size - nvarchar(5)
NULL , -- SizeUnitMeasureCode - nchar(3)
NULL , -- WeightUnitMeasureCode - nchar(3)
7.77 , -- Weight - decimal
12 , -- DaysToManufacture - int
N'R' , -- ProductLine - nchar(2)
N'L' , -- Class - nchar(2)
N'U' , -- Style - nchar(2)
2 , -- ProductSubcategoryID - int
NULL , -- ProductModelID - int
GETDATE() , -- SellStartDate - datetime
GETDATE() , -- SellEndDate - datetime
GETDATE() , -- DiscontinuedDate - datetime
NEWID() , -- rowguid - uniqueidentifier
GETDATE() -- ModifiedDate - datetime
)The execution plan is a bit complex, as many views, indexes, and constraints are being updated and checked, but if we zoom in on just the Clustered Index Insert, we can see the guts of the insert:
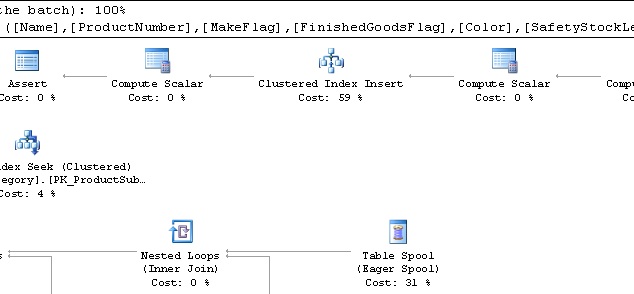
Hovering over the Clustered Index Insert, we can also see the details of what objects were updated:
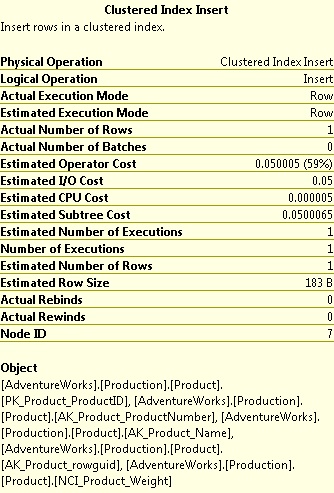
Based on the details at the bottom, we can see 5 indexes being updated:
- AK_Product_Name
- AK_Product_ProductNumber
- AK_Product_rowguid
- NCI_Product_Weight
- PK_Product_ProductID
Lastly, here are the IO statistics for the Product table:
Table 'Product'. Scan count 0, logical reads 11, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
The total subtree cost for this operation is 0.085147 and there were a total of 11 reads on the table itself. Note that the insert itself comprised 59% of the total subtree cost for the entire operation.
Now we will add a new index on Weight. An index already exists on this column, so we are purposely duplicating it:
CREATE NONCLUSTERED INDEX NCI_Product_Weight_DUPE ON Production.Product (Weight ASC)
With our new index in place, we will repeat the insert from earlier, adjusting a few columns to satisfy unique indexes:
INSERT INTO Production.Product
( Name ,
ProductNumber ,
MakeFlag ,
FinishedGoodsFlag ,
Color ,
SafetyStockLevel ,
ReorderPoint ,
StandardCost ,
ListPrice ,
Size ,
SizeUnitMeasureCode ,
WeightUnitMeasureCode ,
Weight ,
DaysToManufacture ,
ProductLine ,
Class ,
Style ,
ProductSubcategoryID ,
ProductModelID ,
SellStartDate ,
SellEndDate ,
DiscontinuedDate ,
rowguid ,
ModifiedDate
)
VALUES ( 'Test Product 2' , -- Name - Name
N'12346' , -- ProductNumber - nvarchar(25)
0 , -- MakeFlag - Flag
0 , -- FinishedGoodsFlag - Flag
N'Flurple' , -- Color - nvarchar(15)
100 , -- SafetyStockLevel - smallint
50 , -- ReorderPoint - smallint
0 , -- StandardCost - money
0 , -- ListPrice - money
NULL , -- Size - nvarchar(5)
NULL , -- SizeUnitMeasureCode - nchar(3)
NULL , -- WeightUnitMeasureCode - nchar(3)
7.77 , -- Weight - decimal
12 , -- DaysToManufacture - int
N'R' , -- ProductLine - nchar(2)
N'L' , -- Class - nchar(2)
N'U' , -- Style - nchar(2)
2 , -- ProductSubcategoryID - int
NULL , -- ProductModelID - int
GETDATE() , -- SellStartDate - datetime
GETDATE() , -- SellEndDate - datetime
GETDATE() , -- DiscontinuedDate - datetime
NEWID() , -- rowguid - uniqueidentifier
GETDATE() -- ModifiedDate - datetime
)A look at the execution plan reveals the same plan, but with slightly different numbers:
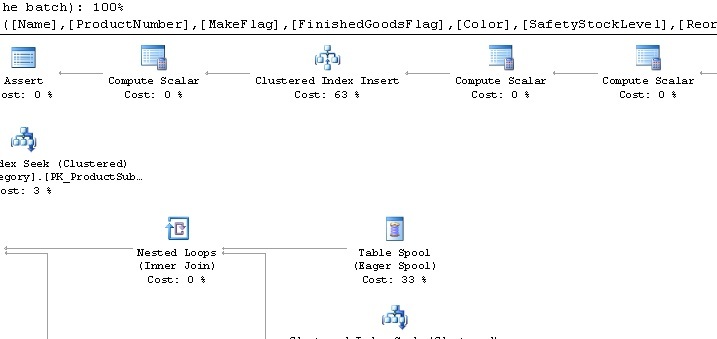
Hovering over the insert, we can verify that our new index is being updated:
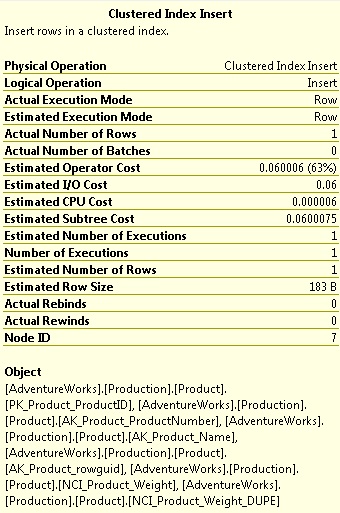
At the bottom of the list is our newly created dupe. A look at the IO statistics on Production.Product shows an additional 2 reads that were needed as part of the insert:
Table 'Product'. Scan count 0, logical reads 13, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
This time the insert takes up a total of 63% of the total subtree cost, which is now 0.095148, an 11.7% increase over our original time. Our reads are up 18.2% as well. This table only contains 504 rows by default, and therefore it is easy to infer how these increased costs would scale up to a table with thousands or millions of rows and become a costly problem.
Solution
There are a handful of system views that we will use to locate duplicate indexes:
- sys.schemas: Contains a row for each schema in a database.
- sys.tables: Contains a row for each user table in a database. Can be joined to sys.schemas using schema_id.
- sys.columns: Contains a row for each column in a database. Can be joined to sys.tables using object_id.
- sys.indexes: Contains a row for each index in a database. Can be joined to sys.tables using object_id.
- sys.index_columns: Contains a row for each column in an index. Can be joined to sys.tables using object_id and sys.indexes using index_id.
Using these views, we will assemble a query that will show us a row per index, including a comma-delimited list of key columns and include columns. To keep this simple, we will filter out system tables and anything except for clustered and non-clustered indexes. The two correlated subqueries take all of the index columns and stuff them into the comma-delimited lists:
SELECT
SCHEMA_DATA.name AS schema_name,
TABLE_DATA.name AS table_name,
INDEX_DATA.name AS index_name,
STUFF((SELECT ', ' + COLUMN_DATA_KEY_COLS.name + ' ' + CASE WHEN INDEX_COLUMN_DATA_KEY_COLS.is_descending_key = 1 THEN 'DESC' ELSE 'ASC' END -- Include column order (ASC / DESC)
FROM sys.tables AS T
INNER JOIN sys.indexes INDEX_DATA_KEY_COLS
ON T.object_id = INDEX_DATA_KEY_COLS.object_id
INNER JOIN sys.index_columns INDEX_COLUMN_DATA_KEY_COLS
ON INDEX_DATA_KEY_COLS.object_id = INDEX_COLUMN_DATA_KEY_COLS.object_id
AND INDEX_DATA_KEY_COLS.index_id = INDEX_COLUMN_DATA_KEY_COLS.index_id
INNER JOIN sys.columns COLUMN_DATA_KEY_COLS
ON T.object_id = COLUMN_DATA_KEY_COLS.object_id
AND INDEX_COLUMN_DATA_KEY_COLS.column_id = COLUMN_DATA_KEY_COLS.column_id
WHERE INDEX_DATA.object_id = INDEX_DATA_KEY_COLS.object_id
AND INDEX_DATA.index_id = INDEX_DATA_KEY_COLS.index_id
AND INDEX_COLUMN_DATA_KEY_COLS.is_included_column = 0
ORDER BY INDEX_COLUMN_DATA_KEY_COLS.key_ordinal
FOR XML PATH('')), 1, 2, '') AS key_column_list ,
STUFF(( SELECT ', ' + COLUMN_DATA_INC_COLS.name
FROM sys.tables AS T
INNER JOIN sys.indexes INDEX_DATA_INC_COLS
ON T.object_id = INDEX_DATA_INC_COLS.object_id
INNER JOIN sys.index_columns INDEX_COLUMN_DATA_INC_COLS
ON INDEX_DATA_INC_COLS.object_id = INDEX_COLUMN_DATA_INC_COLS.object_id
AND INDEX_DATA_INC_COLS.index_id = INDEX_COLUMN_DATA_INC_COLS.index_id
INNER JOIN sys.columns COLUMN_DATA_INC_COLS
ON T.object_id = COLUMN_DATA_INC_COLS.object_id
AND INDEX_COLUMN_DATA_INC_COLS.column_id = COLUMN_DATA_INC_COLS.column_id
WHERE INDEX_DATA.object_id = INDEX_DATA_INC_COLS.object_id
AND INDEX_DATA.index_id = INDEX_DATA_INC_COLS.index_id
AND INDEX_COLUMN_DATA_INC_COLS.is_included_column = 1
ORDER BY INDEX_COLUMN_DATA_INC_COLS.key_ordinal
FOR XML PATH('')), 1, 2, '') AS include_column_list,
INDEX_DATA.is_disabled -- Check if index is disabled before determining which dupe to drop (if applicable)
FROM sys.indexes INDEX_DATA
INNER JOIN sys.tables TABLE_DATA
ON TABLE_DATA.object_id = INDEX_DATA.object_id
INNER JOIN sys.schemas SCHEMA_DATA
ON SCHEMA_DATA.schema_id = TABLE_DATA.schema_id
WHERE TABLE_DATA.is_ms_shipped = 0
AND INDEX_DATA.type_desc IN ('NONCLUSTERED', 'CLUSTERED')The output of our query looks like this:
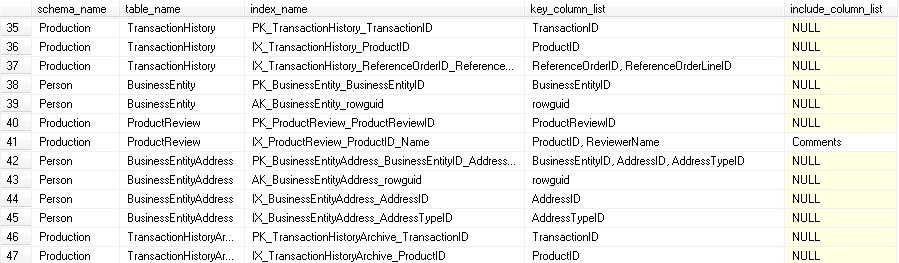
Our first task will be to use this data to locate exact duplicates. This can be done by building on top of our existing query to find duplicate rows and return only them for our review:
;WITH CTE_INDEX_DATA AS (
SELECT
SCHEMA_DATA.name AS schema_name,
TABLE_DATA.name AS table_name,
INDEX_DATA.name AS index_name,
STUFF((SELECT ', ' + COLUMN_DATA_KEY_COLS.name + ' ' + CASE WHEN INDEX_COLUMN_DATA_KEY_COLS.is_descending_key = 1 THEN 'DESC' ELSE 'ASC' END -- Include column order (ASC / DESC)
FROM sys.tables AS T
INNER JOIN sys.indexes INDEX_DATA_KEY_COLS
ON T.object_id = INDEX_DATA_KEY_COLS.object_id
INNER JOIN sys.index_columns INDEX_COLUMN_DATA_KEY_COLS
ON INDEX_DATA_KEY_COLS.object_id = INDEX_COLUMN_DATA_KEY_COLS.object_id
AND INDEX_DATA_KEY_COLS.index_id = INDEX_COLUMN_DATA_KEY_COLS.index_id
INNER JOIN sys.columns COLUMN_DATA_KEY_COLS
ON T.object_id = COLUMN_DATA_KEY_COLS.object_id
AND INDEX_COLUMN_DATA_KEY_COLS.column_id = COLUMN_DATA_KEY_COLS.column_id
WHERE INDEX_DATA.object_id = INDEX_DATA_KEY_COLS.object_id
AND INDEX_DATA.index_id = INDEX_DATA_KEY_COLS.index_id
AND INDEX_COLUMN_DATA_KEY_COLS.is_included_column = 0
ORDER BY INDEX_COLUMN_DATA_KEY_COLS.key_ordinal
FOR XML PATH('')), 1, 2, '') AS key_column_list ,
STUFF(( SELECT ', ' + COLUMN_DATA_INC_COLS.name
FROM sys.tables AS T
INNER JOIN sys.indexes INDEX_DATA_INC_COLS
ON T.object_id = INDEX_DATA_INC_COLS.object_id
INNER JOIN sys.index_columns INDEX_COLUMN_DATA_INC_COLS
ON INDEX_DATA_INC_COLS.object_id = INDEX_COLUMN_DATA_INC_COLS.object_id
AND INDEX_DATA_INC_COLS.index_id = INDEX_COLUMN_DATA_INC_COLS.index_id
INNER JOIN sys.columns COLUMN_DATA_INC_COLS
ON T.object_id = COLUMN_DATA_INC_COLS.object_id
AND INDEX_COLUMN_DATA_INC_COLS.column_id = COLUMN_DATA_INC_COLS.column_id
WHERE INDEX_DATA.object_id = INDEX_DATA_INC_COLS.object_id
AND INDEX_DATA.index_id = INDEX_DATA_INC_COLS.index_id
AND INDEX_COLUMN_DATA_INC_COLS.is_included_column = 1
ORDER BY INDEX_COLUMN_DATA_INC_COLS.key_ordinal
FOR XML PATH('')), 1, 2, '') AS include_column_list,
INDEX_DATA.is_disabled -- Check if index is disabled before determining which dupe to drop (if applicable)
FROM sys.indexes INDEX_DATA
INNER JOIN sys.tables TABLE_DATA
ON TABLE_DATA.object_id = INDEX_DATA.object_id
INNER JOIN sys.schemas SCHEMA_DATA
ON SCHEMA_DATA.schema_id = TABLE_DATA.schema_id
WHERE TABLE_DATA.is_ms_shipped = 0
AND INDEX_DATA.type_desc IN ('NONCLUSTERED', 'CLUSTERED')
)
SELECT
*
FROM CTE_INDEX_DATA DUPE1
WHERE EXISTS
(SELECT * FROM CTE_INDEX_DATA DUPE2
WHERE DUPE1.schema_name = DUPE2.schema_name
AND DUPE1.table_name = DUPE2.table_name
AND DUPE1.key_column_list = DUPE2.key_column_list
AND ISNULL(DUPE1.include_column_list, '') = ISNULL(DUPE2.include_column_list, '')
AND DUPE1.index_name <> DUPE2.index_name)The CTE is the same exact query that we created earlier. We encapsulate this logic into a CTE separately as copying & pasting the large STUFF statements over and over would be messy & cumbersome. While we could use the ROW_NUMBER window function to return duplicates, we explicitly want to see all versions of the dupe, not just the one that we deem to be expendable. Joining the CTE to itself allows us to locate all sets of rows that are not unique and return all of the data for each. The results look like this:

NCI_Product_Weight_DUPE, the index we created earlier, is here as expected. We’ve also caught another dupe on the Production.Document table. Now that we have located 2 sets of duplicates, we are free to drop one copy of each to remove the duplicated functionality. We will not drop these indexes yet, as they will be needed for further testing below.
Our solution thus far will only identify indexes that are exact duplicates of each other. We are also interested in finding overlapping indexes: a scenario where two indexes share the same sequence of indexes in order. For example, let’s create another new index on Adventureworks:
CREATE NONCLUSTERED INDEX NCI_Product_Weight_OVERLAP ON Production.Product(Weight, ProductModelID ASC)
This new index is similar to the one we duplicated earlier, but has ProductModelID as an additional key column. SQL Server will use both indexes for different queries, but we could remove the indexes on Weight and rely solely on this new one to handle queries on Weight or queries on Weight & ProductModelID. For queries only on Weight, the new index would be slightly more expensive to use, as ProductModelID also needs to be returned, but the difference is very small compared to the burden of maintaining the other indexes indefinitely.
To detect both duplicate indexes AND overlapping indexes, we can modify the query we wrote earlier by using some string manipulation:
;WITH CTE_INDEX_DATA AS (
SELECT
SCHEMA_DATA.name AS schema_name,
TABLE_DATA.name AS table_name,
INDEX_DATA.name AS index_name,
STUFF((SELECT ', ' + COLUMN_DATA_KEY_COLS.name + ' ' + CASE WHEN INDEX_COLUMN_DATA_KEY_COLS.is_descending_key = 1 THEN 'DESC' ELSE 'ASC' END -- Include column order (ASC / DESC)
FROM sys.tables AS T
INNER JOIN sys.indexes INDEX_DATA_KEY_COLS
ON T.object_id = INDEX_DATA_KEY_COLS.object_id
INNER JOIN sys.index_columns INDEX_COLUMN_DATA_KEY_COLS
ON INDEX_DATA_KEY_COLS.object_id = INDEX_COLUMN_DATA_KEY_COLS.object_id
AND INDEX_DATA_KEY_COLS.index_id = INDEX_COLUMN_DATA_KEY_COLS.index_id
INNER JOIN sys.columns COLUMN_DATA_KEY_COLS
ON T.object_id = COLUMN_DATA_KEY_COLS.object_id
AND INDEX_COLUMN_DATA_KEY_COLS.column_id = COLUMN_DATA_KEY_COLS.column_id
WHERE INDEX_DATA.object_id = INDEX_DATA_KEY_COLS.object_id
AND INDEX_DATA.index_id = INDEX_DATA_KEY_COLS.index_id
AND INDEX_COLUMN_DATA_KEY_COLS.is_included_column = 0
ORDER BY INDEX_COLUMN_DATA_KEY_COLS.key_ordinal
FOR XML PATH('')), 1, 2, '') AS key_column_list ,
STUFF(( SELECT ', ' + COLUMN_DATA_INC_COLS.name
FROM sys.tables AS T
INNER JOIN sys.indexes INDEX_DATA_INC_COLS
ON T.object_id = INDEX_DATA_INC_COLS.object_id
INNER JOIN sys.index_columns INDEX_COLUMN_DATA_INC_COLS
ON INDEX_DATA_INC_COLS.object_id = INDEX_COLUMN_DATA_INC_COLS.object_id
AND INDEX_DATA_INC_COLS.index_id = INDEX_COLUMN_DATA_INC_COLS.index_id
INNER JOIN sys.columns COLUMN_DATA_INC_COLS
ON T.object_id = COLUMN_DATA_INC_COLS.object_id
AND INDEX_COLUMN_DATA_INC_COLS.column_id = COLUMN_DATA_INC_COLS.column_id
WHERE INDEX_DATA.object_id = INDEX_DATA_INC_COLS.object_id
AND INDEX_DATA.index_id = INDEX_DATA_INC_COLS.index_id
AND INDEX_COLUMN_DATA_INC_COLS.is_included_column = 1
ORDER BY INDEX_COLUMN_DATA_INC_COLS.key_ordinal
FOR XML PATH('')), 1, 2, '') AS include_column_list,
INDEX_DATA.is_disabled -- Check if index is disabled before determining which dupe to drop (if applicable)
FROM sys.indexes INDEX_DATA
INNER JOIN sys.tables TABLE_DATA
ON TABLE_DATA.object_id = INDEX_DATA.object_id
INNER JOIN sys.schemas SCHEMA_DATA
ON SCHEMA_DATA.schema_id = TABLE_DATA.schema_id
WHERE TABLE_DATA.is_ms_shipped = 0
AND INDEX_DATA.type_desc IN ('NONCLUSTERED', 'CLUSTERED')
)
SELECT
*
FROM CTE_INDEX_DATA DUPE1
WHERE EXISTS
(SELECT * FROM CTE_INDEX_DATA DUPE2
WHERE DUPE1.schema_name = DUPE2.schema_name
AND DUPE1.table_name = DUPE2.table_name
AND (DUPE1.key_column_list LIKE LEFT(DUPE2.key_column_list, LEN(DUPE1.key_column_list)) OR DUPE2.key_column_list LIKE LEFT(DUPE1.key_column_list, LEN(DUPE2.key_column_list)))
AND DUPE1.index_name <> DUPE2.index_name)Only two adjustments were needed to change our query to look for similar data, rather than identical data. First, we removed the equality check on the included columns list. For the sake of this search, we will ignore included columns altogether. The result set will generally be small enough that we can scan these manually and see what (if any) included columns overlap and can be combined. The second change was to rewrite the key columns equality into a string comparison using the LEFT operator. Here, we are comparing each key columns list in our CTE with the leftmost segment of the rest to determine where we have repeating parts. The output of our query looks like this:

In addition to the 4 rows that were returned earlier, we also get back NCI_Product_Weight_OVERLAP, the new index we created above.
Lastly, we will clean up the dupes that we created in our example:
DROP INDEX Production.Product.NCI_Product_Weight_DUPE DROP INDEX Production.Product.NCI_Product_Weight_OVERLAP
Running our last query, we can check one last time for duplicate or overlapping indexes:

All that’s left is a single duplicate index, which we will let Microsoft clean up at their leisure in a future version of AdventureWorks.
Author’s Note:
I have modified this article since publication to add some additional functionality and robustness:
- Added is_disabled to the query output. If an index is disabled, then we would want to know that before dropping duplicates. Dropping the enabled index while leaving behind the disabled one could be disastrous! Thanks to grzegorz.mozejko for the idea!
- Added additional SQL to the key columns so that the order is output (ASC or DESC). This ensures that indexes covering different column orders are treated as distinct indexes and not identified as duplicates. Thank you to Carlo Romagnano for pointing this out.
- I left out any generated SQL for auto-deletion as adding and dropping indexes should never be done lightly, and never without sufficient time and research.
- There are many other ways to customize these scripts to tailor them to your own environment or company's needs. Feel free to mess with them, reuse them, and share them so that we can ultimately find newer and better ways to handle indexes in SQL Server.
Conclusion
Indexes that duplicate the functionality of each other waste precious SQL Server resources. Being able to efficiently locate duplicate or overlapping indexes will allow us to plan a course of action that will ultimately remove all duplicated logic. Care should be taken when making changes; always test in a development environment first and confirm that your changes are not inadvertently removing any non-duplicated index columns. Having these tools at your disposal will allow you to spend more time cleaning up & verifying the efficiently of your database environment, and less time trying to identify these problems in the first place.
