

Background
In our Enterprise Data Warehouse (EDW) within the Northwestern University Biomedical Informatics Center (NUBIC), exact copies of many source systems exist. From that source system data we create several data marts to organize clinical data in meaningful ways to assist with reporting. Our current process to populate such data marts is to do the following.
- Stage the data in a staging table
- Delete rows from the destination/production table that exist in the staging table
- Insert the remaining data from the staging table into the production table
Many times in our SSIS ETL packages we will overlap slightly with the last load date/time to make sure all new data is collected. This practice causes numerous delete transactions on the production table on a daily basis before the new rows are inserted from staging. For the most part, these deletes are unnecessary since many of the deleted rows are re-inserted with the same data (because of the deliberate overlap mentioned earlier). In the long-term these unnecessary deletes can cause issues with fragmentation.
Problem
To avoid these excessive deletes we investigated the option of a MERGE statement in place of the 3-step process listed previously. This functionality initially looked very promising since it would allow us to stage whatever data we needed and then that data could simply be merged into the production data. The MERGE would update rows that already existed in production and would insert the rows that did not exist. This would eliminate the unnecessary deletes that occur in our current process.
Our evaluation process uncovered some issues with the MERGE statement and SSIS.
- There is currently no simple MERGE task available in SSIS 2008. The easiest way to do this is to create an SSIS Execute SQL task and manually type out the MERGE statement.
- SSIS Execute SQL Task MERGE statement maintenance. If we were to use the Execute SQL Task to execute a MERGE statement, the statements would be rather large. Many of our data mart tables are very wide and are prone to having new columns added to track new clinical information. Manually entering the MERGE statement in an Execute SQL Task creates maintenance issues if a data mart were ever to be modified. If changes to the data mart occur, the MERGE statement would need to be manually updated as well to reflect such changes.
- SSIS Execute SQL Task character limit. Manual entry of the merge statement into the query editor window of the SSIS Execute SQL task is subject to a 32,767 character limit. Again, many of our data mart tables are very wide and contain several columns where this could potentially be an issue.
- SSIS Execute SQL Task manual entry errors. Even if the 32,767 character limit is not met, the MERGE statement itself can still be very long. To type all of the statement manually creates several opportunities for typographical errors, including omission of specific columns.
If we were going to use the MERGE statement via SSIS a solution needed to be created that would be easy to use but also would resolve the issues we uncovered in our investigation.
Proposed Solution
Our solution was to create a stored procedure that could dynamically generate the MERGE statement outside of the SSIS Execute SQL Task and execute it. This article will walk through step-by-step how we built our stored procedure. An example MERGE statement is provided below. As we review each step we will see how the stored procedure would generate this example MERGE statement.
To begin, let’s first review the MERGE statement and its construction (Here is a link to a very useful SQLServerCentral technical article which provides a thorough overview of the MERGE statement). A MERGE is comprised of the following parts.
- A source table (this would be our staging table)
- A target table (this would be our production table)
- A predicate (how to join the source and target tables)
- An Update command to be executed when the source and target rows match on the predicate
- An Insert command to be executed when the source row does not match a target row
- A Delete command to be executed when the target rows do not exist in the source
For our purposes there was no need for the delete command because we want to keep the rows on the target table that do not exist in the source table. Here is the example MERGE statement that we will attempt to generate and execute via this stored procedure. Within this example we have a staging/source table called edw.adventure_hospital_dm.visits and a production/target table called edw.staging.stg_visits.
MERGE into edw.adventure_hospital_dm.visits tgt --1) Target table
using edw.staging.stg_visits src --2) Source table
on src.financial_nbr = tgt.financial_nbr --3) Predicate
when matched then update --4) Update into Source table when matched
set tgt.name = src.name,
tgt.financial_nbr = src.fininancial_nbr,
tgt.medical_number = src.medical_number,
tgt.registration_date = src.registration_date,
tgt.meta_orignl_load_dts = src.meta_orignl_load_dts,
tgt.meta_update_dts = src.meta_update_dts
when not matched then insert ( --5) Insert into Source table when not matched
name,
financial_nbr,
medical_number,
registration_date,
meta_orignl_load_dts,
meta_update_dts
)
values (
src.name,
src.fininancial_nbr,
src.medical_number,
src.registration_date,
src.meta_orignl_load_dts,
src.meta_update_dts);Before the stored procedure was built we determined that a useful MERGE stored procedure would need to satisfy the following requirements.
- Accept parameters to enter the Source database/schema/table and the Target database/schema/table.
- Automatically determine the predicate between the Source and Target tables
- Automatically determine whether a Source column data type matches a Target column data type and store the matching columns in a temp table
- Generate a dynamic SQL MERGE statement based on the matched columns stored in the temp table
- Execute the dynamic SQL MERGE statement
Step 1: Accept parameters to enter the Source database, schema, and table along with the Target database, schema, and table.
Our goal for this solution was for it to be easy to use. We wanted to be able to execute a stored procedure and simply tell it what two tables to merge. To do this we chose to create a stored procedure with 7 parameters. The first 3 parameters (database, schema, and table name) are used to pass in the Source table. The second 3 parameters (database, schema, and table name) are used to pass in the Target table. Even though the stored procedure will automatically generate the matching predicate (which is discussed in Step #2), we created the last parameter as an option to manually pass in a matching predicate if needed.
Here is the section of code that was used to create the stored procedure along with its arguments and variables.
CREATE PROCEDURE [adventure_hospital].[generate_merge]
@SrcDB SYSNAME, --Name of the Source database
@SrcSchema SYSNAME, --Name of the Source schema
@SrcTable SYSNAME, --Name of the Source table
@TgtDB SYSNAME, --Name of the Target database
@TgtSchema SYSNAME, --Name of the Target schema
@TgtTable SYSNAME, --Name of the Target table
@predicate SYSNAME = null
AS
BEGIN
--overall dynamic sql statement for the merge
DECLARE @merge_sql NVARCHAR(MAX);
--the dynamic sql to generate the list of columns used in
--the update/insert/values portion of the merge dynamic sql
DECLARE @columns_sql NVARCHAR(MAX);
--the dynamic sql to generate the predicate/matching-statement
--of the merge dynamic sql (populates @pred)
DECLARE @pred_sql NVARCHAR(MAX);
--contains the comma-seperated columns used in the UPDATE
--portion of the merge dynamic sql
DECLARE @updt NVARCHAR(MAX);
--contains the comma-seperated columns used in the INSERT
--portion of the merge dynamic sql
DECLARE @insert NVARCHAR(MAX);
--contains the comma-seperated columns used in the VALUES
--portion of the merge dynamic sql
DECLARE @vals NVARCHAR(MAX);
--contains the predicate/matching-statement of the merge dynamic
--sql (populated by @pred_sql)
DECLARE @pred NVARCHAR(MAX);
--contains the necessary parameters for the dynamic sql execution
DECLARE @dsql_param NVARCHAR(500);Step 2: Automatically determine the predicate used between the Source and Target tables
Before the predicate is automatically generated there must be a check to see whether or not a predicate was passed in as a parameter. If a predicate was passed in then the predicate statement is easily constructed and assigned to the @pred variable for later usage.
If the predicate was not passed in as a parameter a dynamic SQL (@pred_sql) is generated to query the INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE table using the Target database, schema, and table parameters. The INFORMATION_SCHEMA table is automatically available in SQL Server 2000 and above. Since the output of this the dynamic SQL (@pred_sql) needs to be collected and assigned to a variable (@pred) a parameter (@dsql_param) needs to be passed in so that the output can be returned and assigned appropriately. Once the dynamic SQL (@pred_sql) and the dynamic SQL parameter (@dsql_param) have been created, they can be executed. The output can then be assigned to @pred. We now have our predicate statement.
/****************************************************************************************
* This generates the matching statement (aka Predicate) statement of the Merge *
* If a predicate is explicitly passed in, use that to generate the matching statement *
* Else execute the @pred_sql statement to decide what to match on and generate the *
* matching statement automatically *
****************************************************************************************/ IF @predicate is not null
set @pred = 'src.' + @predicate + ' = tgt.' + @predicate
ELSE
BEGIN
set @pred_sql = ' SELECT @predsqlout = COALESCE(@predsqlout+''and'','''')+' +
'(''''+''src.''+column_name+''=tgt.''+ccu.column_name)' +
' FROM ' +
@TgtDB + '.INFORMATION_SCHEMA.TABLE_CONSTRAINTS tc_tgt' +
' INNER JOIN ' + @TgtDB +'.INFORMATION_SCHEMA.CONSTRAINT_COLUMN_USAGE ccu' +
' ON tc_tgt.CONSTRAINT_NAME = ccu.Constraint_name' +
' AND tc_tgt.table_schema = ccu.table_schema' +
' AND tc_tgt.table_name = ccu.table_name' +
' WHERE' +
' tc_tgt.CONSTRAINT_TYPE = ''Primary Key''' +
' AND tc_tgt.table_catalog = ''' + @TgtDB + '''' +
' AND tc_tgt.table_name = ''' + @TgtTable + '''' +
' AND tc_tgt.table_schema = ''' + @TgtSchema + ''''
set @dsql_param = '@predsqlout nvarchar(max) OUTPUT'
EXEC sp_executesql
@pred_sql,
@dsql_param,
@predsqlout = @pred OUTPUT;
ENDThe benefit of generating the predicate this way is that this automatically handles multiple primary key constraints on the Target table. All primary key constraints are evaluated and added into the predicate statement. The example output from the @pred variable is listed here.
src.financial_nbr = tgt.financial_nbrStep 3: Automatically determine if a Source column data type matches the corresponding Target column data type and store the matching columns in a temp table
To do this we first need to create the custom table (@columns) that will be used to hold all the columns that exist between the Source and the Target tables. These columns must have the same name and same data type. By ‘same data type’ I mean both that the data type is the same and that the precision of the Target table column is at the same level or greater than the precision of the Source table column. For example, the medical_number column on the Source table may be varchar(10). As long as the corresponding medical_number column on the Target/Production table is at least a varchar(10) or greater the logic will consider that to be a match and store that column on the temp table.
--Create the temporary table to collect all the columns shared
--between both the Source and Target tables.
DECLARE @columns TABLE (
table_catalog VARCHAR(100) NULL,
table_schema VARCHAR(100) NULL,
table_name VARCHAR(100) NULL,
column_name VARCHAR(100) NULL,
data_type VARCHAR(100) NULL,
character_maximum_length INT NULL,
numeric_precision INT NULL,
src_column_path VARCHAR(100) NULL,
tgt_column_path VARCHAR(100) NULL
)When the @columns temp table has been created a dynamic SQL statement is generated (@columns_sql) and executed to populate the temp table. The @columns_sql dynamic SQL statement takes the values passed in via parameters and uses them to query the INFORMATION_SCHEMA.COLUMNS table to find matching columns between the Source and Target tables. Once the @columns_sql dynamic SQL has been constructed it is executed and the values returned are automatically inserted into the @columns temp table.
--Generate the dynamic sql (@columns_sql) statement that will
--populate the @columns temp table with the columns that will be used in the merge dynamic sql
--The @columns table will contain columns that exist in both the source and target
--tables that have the same data types.
set @columns_sql =
'SELECT
tgt.table_catalog,
tgt.table_schema,
tgt.table_name,
tgt.column_name,
tgt.data_type,
tgt.character_maximum_length,
tgt.numeric_precision,
(src.table_catalog+''.''+src.table_schema+''.''+src.table_name+''.''+src.column_name) AS src_column_path,
(tgt.table_catalog+''.''+tgt.table_schema+''.''+tgt.table_name+''.''+tgt.column_name) AS tgt_column_path
FROM
' + @TgtDB + '.INFORMATION_SCHEMA.COLUMNS TGT
INNER JOIN ' + @SrcDB + '.INFORMATION_SCHEMA.COLUMNS SRC
ON tgt.column_name = src.column_name
AND tgt.data_type = src.data_type
AND (tgt.character_maximum_length IS NULL OR tgt.character_maximum_length >= src.character_maximum_length)
AND (tgt.numeric_precision IS NULL OR tgt.numeric_precision >= src.numeric_precision)
WHERE
tgt.table_catalog = ''' + @TgtDB + '''
AND tgt.table_schema = ''' + @TgtSchema + '''
AND tgt.table_name = ''' + @TgtTable + '''
AND src.table_catalog = ''' + @SrcDB + '''
AND src.table_schema = ''' + @SrcSchema + '''
AND src.table_name = ''' + @SrcTable + '''
ORDER BY tgt.ordinal_position'
--execute the @columns_sql dynamic sql and populate @columns table with the data
INSERT INTO @columns
exec sp_executesql @columns_sqlNow that the @columns temp table has been populated we have a list of all the columns that will be referenced in the overall MERGE statement.
Step 4: Generate a dynamic SQL MERGE statement based on the matched columns stored in the temp table
For the overall MERGE statement there are 3 sets of comma-separated columns that need to be generated from the data collected in the @columns temp table. These will be the update columns, insert columns, and the insert-values columns. In our example MERGE statement the 3 sets of columns are outlined below in red.

For each one of the 3 sets of columns a query needs to be executed against the @columns temp table. We needed a way to query the columns on the @columns temp table and loop through them creating a comma separated list. Since such a query will return more than row, if you try to assign the output of this query to a variable you will receive the error "Subquery returned more than 1 value."
To get around this we used SQLServer’s FOR XML functionality. For anyone not familiar with FOR XML, simply put FOR XML allows you to run a query and format all of the output as XML. It then assigns that output to a variable of type XML. We essentially ran the same query but used FOR XML PATH('') which allowed us to loop through the data results by generating an XML version of the data with absolutely no XML formatting. Since FOR XML automatically returns a data type of XML, we then cast the results to convert them from XML to NVARCHAR.
What you are left with is a string that contains all the comma-separated columns that can be used for the MERGE statement. Obviously, this is not the intended use of FOR XML, but this suited our needs nicely.
Here is the section of the stored procedure used to generate the comma-separated columns used for the update portion of the overall MERGE statement.
/**************************************************************************
* A Merge statement contains 3 seperate lists of columns *
* 1) List of columns used for Update Statement *
* 2) List of columns used for Insert Statement *
* 3) List of columns used for Values portion of the Insert Statement *
**************************************************************************/ --1) List of columns used for Update Statement
--Populate @updt with the list of columns that will be used to construct the Update Statment portion of the Merge
set @updt = CAST((SELECT ',tgt.' + column_name + ' = src.' + column_name
FROM @columns
where column_name != 'meta_orignl_load_dts' --we want to filter out this column because we do not want the
FOR XML PATH('')) --meta_orginl_load_dts of the target table to be overwritten on updates.
AS NVARCHAR(MAX) --we want to preserve the original date/time the row was written out.
)Here is the output of the @updt variable for our example.
,tgt.name = src.name
,tgt.financial_nbr = src.fininancial_nbr
,tgt.medical_number = src.medical_number
,tgt.registration_date = src.registration_date
,tgt.meta_update_dts = src.meta_update_dts**Special Note** For the columns used in the update portion of the MERGE statement, we filtered out the meta_orginl_load_dts column. The EDW uses this column as meta data to record when a row was originally written out to the data mart. Upon an update, we do not want this column to be updated with the meta_orignl_load_dts from the staging/source table. We still want to preserve the original load date time of that row. The date and time the row was updated will be represented in the meta column meta_update_dts. Second, the comma-separated list of columns used for the insert portion of the overall MERGE statement need to be generated.
Here is section of the stored procedure used to generate the comma-separated columns used for the insert portion of the overall MERGE statement.
--2) List of columns used for Insert Statement
--Populate @insert with the list of columns that will be used to construct the Insert Statment portion of the Merge
set @insert = CAST((SELECT ',' + column_name
FROM @columns
FOR XML PATH(''))
AS NVARCHAR(MAX)
)Here is the output of the @insert variable for our example.
,name
,financial_nbr
,medical_number
,registration_date
,meta_orignl_load_dts
,meta_update_dtsHere is section of the stored procedure used to create the comma-separated list of columns used for the insert-values portion of the overall MERGE statement.
--3) List of columns used for Insert-Values Statement
--Populate @vals with the list of columns that will be used to construct the Insert-Values Statment portion of the Merge
set @vals = CAST((SELECT ',src.' + column_name
FROM @columns
FOR XML PATH(''))
AS NVARCHAR(MAX)
)Here is the output of the @vals variable for our example.
,src.name
,src.fininancial_nbr
,src.medical_number
,src.registration_date
,src.meta_orignl_load_dts
,src.meta_update_dtsStep 5: Execute the dynamic SQL MERGE statement
Now that we have the Source database/schema/table, the Target database/schema/table, the predicate matching statement, and the update/insert/values comma-separated lists of columns, we have everything we need to generate the entire dynamic SQL MERGE statement. Once the MERGE statement is generated it then gets executed automatically.
Here is the section of the stored procedure used to pull everything together into the overall MERGE statement (@merge_sql) and then execute it.
/*************************************************************************************
* Generate the final Merge statement using *
* -The parameters (@TgtDB, @TgtSchema, @TgtTable, @SrcDB, @SrcSchema, @SrcTable) *
* -The predicate matching statement (@pred) *
* -The update column list (@updt) *
* -The insert column list (@insert) *
* -The insert-value column list (@vals) *
*************************************************************************************/ SET @merge_sql = (' MERGE into ' + @TgtDB + '.' + @TgtSchema + '.' + @TgtTable + ' tgt ' +
' using ' + @SrcDB + '.' + @SrcSchema + '.' + @SrcTable + ' src ' +
' on ' + @pred +
' when matched then update ' +
' set ' + SUBSTRING(@updt, 2, LEN(@updt)) +
' when not matched then insert (' + SUBSTRING(@insert, 2, LEN(@insert)) + ')' +
' values ( ' + SUBSTRING(@vals, 2, LEN(@vals)) + ');'
);
--Execute the final Merge statement to merge the staging table into production
EXEC sp_executesql @merge_sql;The substring() function is used on @updt, @insert, and @vals to remove the preceding comma from each set of columns. This could have been done earlier in the stored procedure but we decided to take care of it here.
Here is the output of the @merge_sql variable from our example.
MERGE into edw.adventure_hospital_dm.visits tgt
using edw.staging.stg_visits src
on src.financial_nbr = tgt.financial_nbr
when matched then update
set tgt.name = src.name,
tgt.financial_number = src.financial_number,
tgt.medical_number = src.medcial_nubmer,
tgt.registration_date = src.registration_date,
tgt.meta_orignl_load_dts = src.meta_orignl_load_dts,
tgt.meta_update_dts = src.meta_update_dts
when not matched then insert (
name,
financial_nbr,
medical_number,
registration_date,
meta_orignl_load_dts,
meta_update_dts
)
values (
src.name,
src.financial_nbr,
src.medical_number,
src.registration_date,
src.meta_orignl_load_dts,
src.meta_update_dts);Conclusion
We are currently working towards utilizing this stored procedure within our SSIS packages for populating datamarts. Using our current process, a simplified version of one of our SSIS packages would look like the example below.
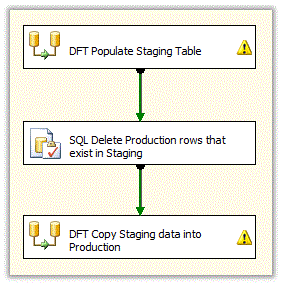
By using the stored procedure to merge the data from staging into the production table we can replace the last 2 tasks with one Execute SQL task. That Execute SQL task simply executes the stored procedure. Using this method the example SSIS package would now look like this.
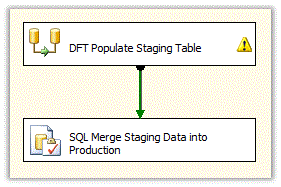
Here is the SQL code that is executed by the Execute SQL task.
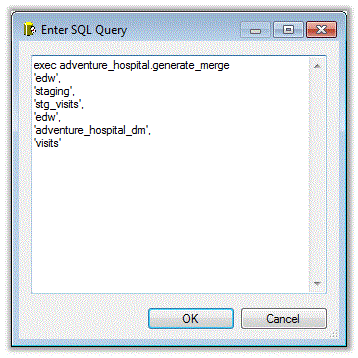
Although this stored procedure as a bit tedious to build, it is worth it. We now have a stored procedure to run from SSIS that suits our data warehousing needs for merging staging data into production.
There are many benefits to merging data via a stored procedure.
- Easily executed through an SSIS SQL Task
- Easily reusable
- Automatically builds and executes the merge statement so there is no need for manual creation or maintenance of the merge SQL statement.
- Reduces fragmentation since there are less deletes performed on the production table
- Since rows are updated instead of deleted and reinserted, the ETL package runs faster
- Overcomes SSIS SQL Task 32,676 character limit
- Preserves original row load date and time (since the row is updated instead of deleted and re-inserted)
Limitations
This stored procedure is meant for data warehousing type functionality. It assumes you are using a Staging-To-Production type of model where the staging table and production table are almost identically built with the same column names and very similar data types.
Resources
Dhaneenja, T. (2008). Understanding the MERGE DML Statement in SQL Server 2008.
SQLServerCentral.com. Retrieved from
http://www.sqlservercentral.com/articles/SQL+Server+2008/64365/


