

Within Integration Services there is no single out of the box components to handle CDC. However there are various mechanisms to achieve this either by building your own custom component or by using the standard components available within SSIS.
The design pattern described in this article can be implemented on SQL Server 2005 and SQL Server 2008. It uses only the out of the box SSIS tasks and components such as the Execute SQL tasks, Data Flow tasks, OLEDB Source components, OLEDB Destination components, Conditional Split components and Derived Column components. All tasks and components only use default settings, so no changes to the configurations are required.
The salient features of this design pattern are as follows:
- Efficient in handling large volumes of data
- Only uses set based SQL operations for inserting, updating and deleting data
- Avoids using any RBAR (Row-By-Agonising-Row) operations
- Can track historical changes
- Additional logging of changes can be easily added
- Flexible enough to incorporate and implement any other custom business logic
It is expected that the reader has a fair amount of SSIS experience and has a moderate to advance understanding of the principles.
Sample Application Scenario
In order to demonstrate the implementation of this design pattern, we are going look at a simple cut down version of a Patient Data warehouse.
Each day the database receives the latest Patient Register from the doctors' surgery and needs to be kept up to date with new patients and any changes made to existing patients. While any changes to existing patient details need to be updated, the old details should not be lost, and must to be stored in history for later reference. Patients removed from the register also must be stored in history prior to them being deleted.
The Patient Register arrives as a comma delimited text file and is first extracted into a data extract table. We will not look into the details of this data extract transfer mechanism but focus only on the change capture and update part of the process.
Sample Data Model
To demonstrate this design pattern we have set up the following tables:
- PatientDataExtract:- This is the table where the latest received Patient Register will be stored. It contains all the attributes required by the data warehouse. We will not be going into the detailed structure of this table as its purely used here as the primary data source.
- Patient:- This is the final table that we want to insert or update records based on the changes that we capture. The following DDL shows a simplified structure of this table. The table will hold one record for each patient uniquely identified by the PatientKey identify field which is also its primary key. The PatientID attribute on the other hand will be the business key.
CREATE TABLE [dbo].[Patient]( [PatientKey] [int] IDENTITY(1,1) NOT NULL, [PatientID] [varchar](50) NOT NULL, [DoctorCode] [varchar](50) NULL, [DateRegistered] [datetime] NULL, [PostCode] [varchar](50) NULL, [DateofBirth] [datetime] NULL, [Sex] [varchar](1) NULL, [Status] [varchar](1) NULL, CONSTRAINT [prk_Patient] PRIMARY KEY CLUSTERED([PatientKey] ASC) )
- PatientHistory:- In this table we want to store the old record before any changes are made to the Patient table. This is simply an exact copy of the Patient table with the exception of an additional History ID, which is a sequentially incrementing number and will be the primary key for this table.
CREATE TABLE [dbo].[PatientHistory]( [HistoryID] [int] IDENTITY(1,1) NOT NULL, [PatientKey] [int] NOT NULL, [PatientID] [varchar](50) NOT NULL, [DoctorCode] [varchar](50) NULL, [DateRegistered] [datetime] NULL, [PostCode] [varchar](50) NULL, [DateofBirth] [datetime] NULL, [Sex] [varchar](1) NULL, [Status] [varchar](1) NULL, CONSTRAINT [prk_PatientHistory] PRIMARY KEY CLUSTERED([HistoryID] ASC) )
- staging.Patient:- This is the staging table that will be used to temporarily hold patient records while we perform the CDC operations. It table has the same structure of the final Patient table, with the exception that it does not have the PatientKey attribute. We have created this table with the same name and placed it in a ‘staging’ schema, although it could be named differently or be placed in a altogether separate staging database.
CREATE TABLE [staging].[Patient]( [PatientID] [varchar](50) NOT NULL, [DoctorCode] [varchar](50) NULL, [DateRegistered] [datetime] NULL, [PostCode] [varchar](50) NULL, [DateofBirth] [datetime] NULL, [Sex] [varchar](1) NULL, [Status] [varchar](1) NULL )
- staging.PatientCDC:- This table is intended to keep a track of changes to the patient records in terms of which patient records are modified and which are removed. This is indicated by the CDCFlag attribute which will be set to ‘U’ for any modified records and ‘R’ for any removed records.
CREATE TABLE [staging].[PatientCDC]( [PatientID] [varchar](50) NOT NULL, [CDCFlag] [varchar](1) NOT NULL )
SSIS Package Design
The data flow diagram below shows at a high level how the package will flow.
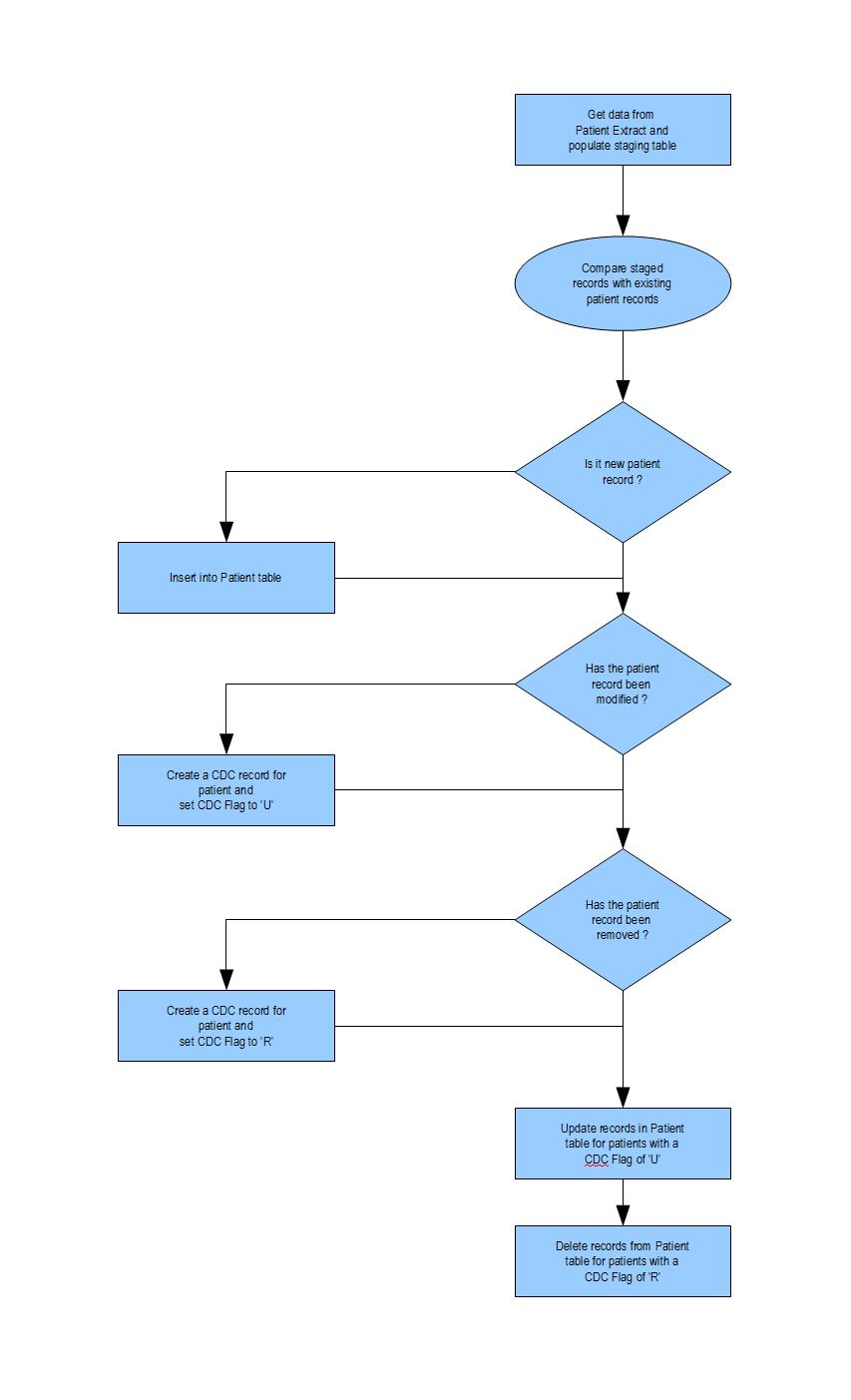
The SSIS package will essentially comprise of two Data Flow tasks, one to get the patient data from the PatientDataExtract table to the staging.Patient table and the other to compare records between the staging.Patient table and final Patient table, insert new patient records, if there are any, and set the CDCFlag in the staging.PatientCDC table for any changed or removed records to be later updated or removed. Then a Execute SQL task is used to Update or Delete records from the final Patient table based on the CDCFlag set in the previous Data Flow task.
The reason behind using a Execute SQL task to perform the updates and deletes is that, doing this within the Data Flow will cause these to be performed in a very slow row by row fashion as opposed to being performed as a data set. Unlike the OLEDB Destination component which is used to perform the inserting of new records as data sets within the Data Flow task, there is no readily available component within the Data Flow task, to perform updates or deletes in a similar fashion.
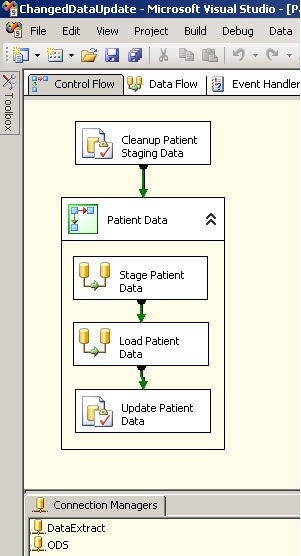
As you can see in the above package, there is also a Execute SQL Task at the beginning to clean up the staging tables prior to loading the data. The sequence container to which the first Execute SQL task connects is only for clarity and is entirely optional. If preferred the sequence container can be omitted and the tasks can be connected together directly. There are two Connection Managers that has been setup, one which connects to the DataExtract server and another to a Operations Data Server. Of course it is perfectly fine to have only one Connection Manager if all the data resided on the same server.
Package Tasks
Let us now examine each of the tasks in this package in more detail in the order of flow.
Execute SQL Task: Cleanup Patient Staging Data
This task simply truncates the staging.Patient and staging.PatientCDC tables using either TRUNCATE or DELETE statements.
Data Flow Task: Stage Patient Data
This task is used to pull all the patient data from the PatientDataExtract table into the staging.Patient table. In its most simplistic form it contains a OLE DB Source component and a OLE DB Destination component as shown below:
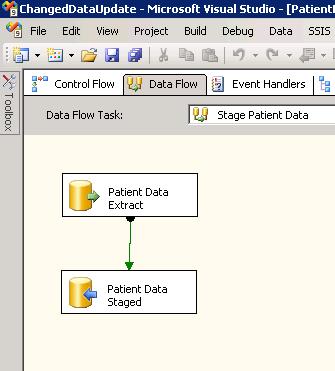
The Data Source component in this example can use a simple SQL command such as SELECT * FROM PatientDataExtract. However depending on the circumstances and complexity, this maybe done by a Stored Procedure or Table View. The Destination component then simply maps the required fields to the staging.Patient table.
Data Flow Task: Load Patient Data
Once the staging.Patient table is populated by the above Data Flow task, this Data Flow task performs the CDC operations. Based on these CDC checks, any new records are inserted into the Patient table and changes and removals are flagged accordingly in the staging.PatientCDC table. Those changed and/or removed records are also inserted into the PatientHistory table. The components in this Data Flow is shown below:
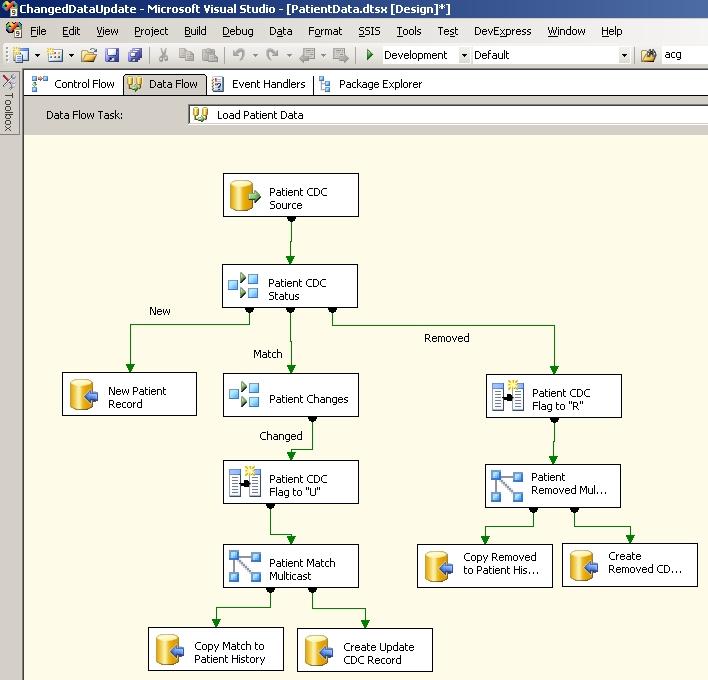
The first OLEDB Source component is key to the process where an SQL command is used to retrieve and combine the records currently in the final Patient table with the newly extracted records in the staging.Patient table. The same can also be achieved via a Stored Procedure if preferable, however in this example this recordset is produced by the following SQL query defined directly on the source component:
SELECT stg.PatientID stg_PatientID ,stg.DoctorCode stg_DoctorCode ,stg.DateRegistered stg_DateRegistered ,stg.PostCode stg_PostCode ,stg.DateofBirth stg_DateofBirth ,stg.Sex stg_Sex ,BINARY_CHECKSUM( ,stg.DoctorCode ,stg.DateRegistered ,stg.PostCode ,stg.DateofBirth ,stg.Sex ) stg_BinaryCDCMask ,pat.PatientKey dbo_PatientKey ,pat.PatientID dbo_PatientID ,pat.DoctorCode dbo_DoctorCode ,pat.DateRegistered dbo_DateRegistered ,pat.PostCode dbo_PostCode ,pat.DateofBirth dbo_DateofBirth ,pat.Sex dbo_Sex ,BINARY_CHECKSUM( ,pat.DoctorCode ,pat.DoctorCode ,pat.DateRegistered ,pat.PostCode ,pat.DateofBirth ,pat.Sex ) dbo_BinaryCDCMask FROM staging.Patient stg FULL OUTER JOIN pat.Patient pat ON stg.PatientID = pat.PatientID
The above query does a Full Outer Join between the staging.Patient and Patient tables on the PatientID key field. This creates a resultset containing all the matching records plus all the missing records from both sides of the join. Hence any records with a Null PatientID from the right side of the join (the Patient table), is a new record. Records with a Null PatientID from the left side of the join (the staging.Patient table), is a removed record. The remaining records with the same PatientID from both sides of the join are existing patient records.
In order to determine whether any details have changed between the existing records and the newly extracted records, we use two Checksum columns from both sides of the join using the BINARY_CHECKSUM function. Although in this example we have included all the fields, you can choose the fields to be included in the checksums, as not all fields may be significant enough to determine changes.
Next the OLEDB Source component passes the result set to a Conditional Split component, which determines which records are new, which records are removed and which records to update as shown below:
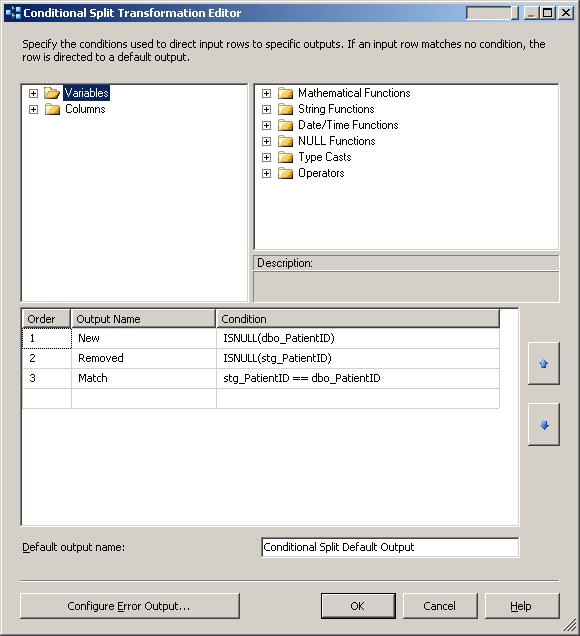
This Conditional Split component then separates the data flow into three routes for New records, Removed records and Matched records as can be seen in the data flow image.
The New record route gets directly connected to a OLEDB Destination component which is mapped to the fields in the final Patient table from the staging.Patient table. In this case the staging.Patient table will be represented by the columns prefixed with “stg_”, which is the left side of the join performed by the earlier OLEDB Source component query. The OLEDB Destination component could be configured to have a Data Access Mode of ‘Table or view - fast load’ which is generally a faster data population method.
The Matched record route is connected to a another Conditional Split component which determines whether any of the important data fields included in the checksums have changed by examining the two Checksum columns as shown below:
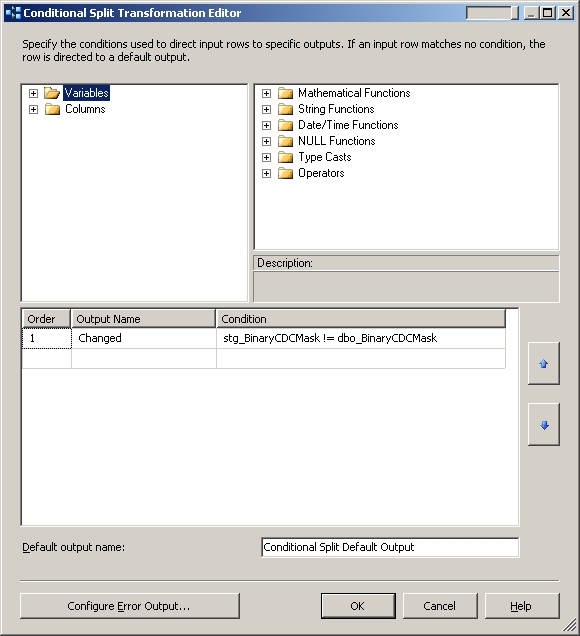
This step is entirely optional and is in place to avoid performing updates when no significant changes have taken place. In this example, if both the Checksum columns are the same then the data flow simply ignores those records and no further action will take place.
A Derived Column component is then used to add the CDCFlag column to the dataflow result set. In the case of the Matched records, this flag is set to “U” as shown below, which indicates these records need to be updated in the final Patient table.
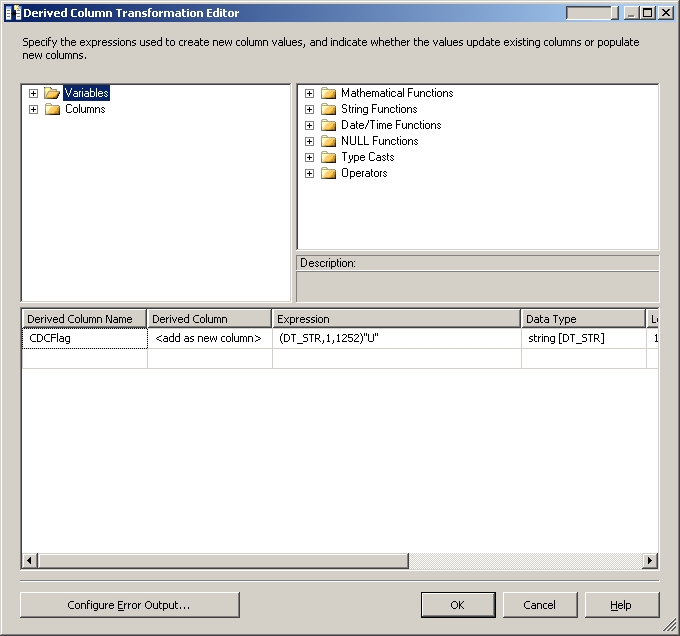
The data flow then gets duplicated by a Multicast component of which one copy gets mapped to the PatientHistory table from the Patient table via a OLEDB Destination component. In this case the Patient table will be represented by the columns prefixed with “dbo_”, which is the right side of the join performed by the earlier OLEDB Source component query. As a result the old values of any changed records will get inserted into the PatientHistory table. A second copy gets mapped to the staging.PatientCDC table via another OLEDB Destination component. The only columns mapped to this table are the any one of the two PatientID columns and the newly derived CDCFlag column. The end result is that the staging.PatientCDC table will contain the list of Patient records which have changed and needs updating in the final Patient table.
Similar to the Matched record route from the initial Conditional Split, the Removed record route, also gets a Derived Column component which adds a CDCFlag column to the data flow and sets it to “R” indicating that these records need to be removed or marked as removed from the final Patient table. Then the data flow is duplicated by a Multicast component and one copy is inserted into the PatientHistory table so that a copy of each record to be removed is retained in history. The other copy is used to insert a record to the staging.PatientCDC table with a CDCFlag of “R”.
As mentioned earlier, the Update and Delete operations are performed outside the Data Flow task via a Execute SQL task, avoiding row by row operations in favor of more efficient set based operations.
Execute SQL Task: Update Patient Data
Finally, this Execute SQL task is used to perform the required updates and deletions on the Patient table based on the flags set in the staging.PatientCDC table by the previous Data Flow task. Depending on the complexity of the operation, this can be done via a Stored Procedure or direct SQL commands. In this example we have simply used SQL commands as shown below:
-- Update changed records UPDATE dbo.Patient SET DoctorCode = stg.DoctorCode ,DateRegistered = stg.DateRegistered ,PostCode = stg.PostCode ,DateofBirth = stg.DateofBirth ,Sex = stg.Sex FROM staging.Patient stg JOIN staging.PatientCDC cdc ON stg.PatientID = cdc.PatientID AND cdc.CDCFlag = ‘U’ JOIN dbo.Patient pat ON cdc.PatientKey = pat.PatientKey; -- Delete removed records DELETE dbo.Patient FROM staging.Patient stg JOIN staging.PatientCDC cdc ON stg.PatientID = cdc.PatientID AND cdc.CDCFlag = ‘R’ JOIN dbo.Patient pat ON cdc.PatientKey = pat.PatientKey;
Summary
This SSIS Design Pattern has been used in several implementations and performs well under large volumes of data. It has been specifically developed using only the standard tasks and components found in both SQL Server 2005 and 2008, to ensure that applications using it will work for all customers who use a mix of both environments. This also makes the design open and simplistic, so that any customisations can be easily adapted.
References
Change Data Capture - http://en.wikipedia.org/wiki/Change_data_capture
SQL Server CHECKSUM vs BINARY_CHECKSUM - http://msdn.microsoft.com/en-us/library/ms173784.aspx

