In this article I’ll be describing an edge case related to logical and internal fragmentation within a specific index branch that may cause performance issues, and also I’d like to contribute to the debate about the use of “global” thresholds for your maintenance plans.
Let’s suppose you have a table with a structure that holds 5 rows per page and leaves almost no space to accommodate changes. After a complete index rebuild with a fillfactor of 100%, the pages would be almost full and you should see a minimal logical fragmentation in your index. Here is the script to generate the initial state of our database.
Script 01 – Create database and tables with records
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
CREATE DATABASE SimpleTalk GO USE SimpleTalk GO IF EXISTS (SELECT [name] FROM sys.tables WHERE [name] = 'HistoricalTable') DROP TABLE HistoricalTable GO CREATE TABLE HistoricalTable ( ID INT IDENTITY NOT NULL CONSTRAINT PK_ID PRIMARY KEY , ColumnA VARCHAR(1590) NULL , ColumnB VARCHAR(1000) NULL , EventDate DATETIME NULL ) GO -- Insert some records to simulate our history INSERT INTO HistoricalTable (ColumnA) VALUES (REPLICATE('SimpleTalk', 159)) GO 100000 UPDATE HistoricalTable SET EventDate = DATEADD(HOUR, ID - 100000, GETDATE()) GO ALTER TABLE dbo.HistoricalTable REBUILD WITH (FILLFACTOR = 100) GO |
Great! As many other DBAs would do, you take care of your indexes and deploy a maintenance plan that checks the fragmentation in your pages: If a certain threshold is met, and a 30% fragmentation is commonly mentioned, you would start a task to rebuild your indexes (let’s put reorganization aside for the sake of simplicity). Your routine runs every night and you have the time window that is necessary to accommodate the entire maintenance task.
After the index-rebuild is over, a quick analysis of this index using sys.dm_db_index_physical_stats shows low levels of logical (ordering of pages) and internal fragmentation (page density); 0.03499% and 99.72% respectively. You can check it by running the following statement:
Script 02 – Checking fragmentation
|
1 2 3 |
SELECT * FROM sys.dm_db_index_physical_stats(DB_ID('SimpleTalk'), OBJECT_ID('HistoricalTable'), NULL, NULL, 'DETAILED') GO |
A more detailed analysis would show the b-tree+ to be very well organized at the rightmost branch of the index (red branches in figure 01). We can accomplish this detailed checking by using DBCC PAGE and navigate thru the tree structure (script 02).
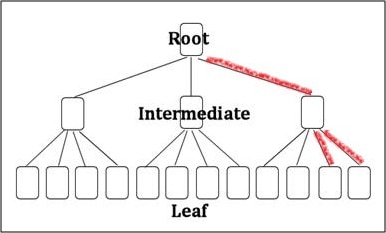
(Figure 01 – B-tree+ rightmost branches)
Starting from the root, and verifying the page ordering at the last two non-leaf index pages, it’s possible to check that all the pages are ordered and that no logical fragmentation is seen. At the leaf level, all the pages are fully allocated with 21 bytes free (in the page header, “m_freeCnt = 21”).
Script 03 – Analyzing the rightmost branch
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
-- Get the root page for our index: 0xAA5000000100 in this sample -- Doing byte swap: 0x000050AA (page number: 20650) at file 0x0001 SELECT AU.root_page FROM sys.system_internals_allocation_units AS AU INNER JOIN SYS.Partitions AS P ON AU.Container_id = P.Partition_id WHERE OBJECT_ID = OBJECT_ID('HistoricalTable') GO -- Checking root page and get references to the two rightmost non-leaf pages (figure 02) DBCC TRACEON(3604) DBCC PAGE ('SimpleTalk', 1, 20650, 3) GO |
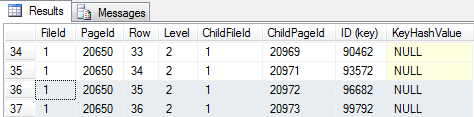
(Figure 02 – Index root level)
|
1 2 3 4 |
-- Non-leaf index page (figure 03) -- Note that all the child pages are ordered DBCC PAGE (36, 1, 20972, 3) GO |
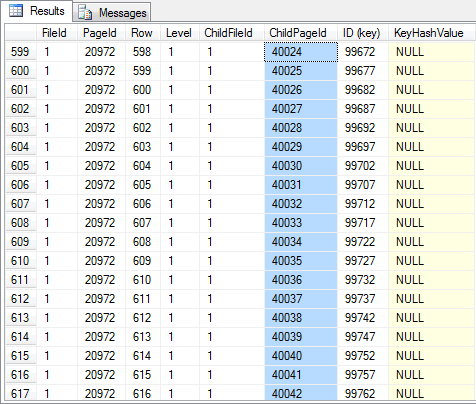
(Figure 03 – Index non-leaf level)
|
1 2 3 4 |
-- Non-leaf index page (figure 04) -- Note that all the child pages are ordered DBCC PAGE (36, 1, 20973, 3) GO |
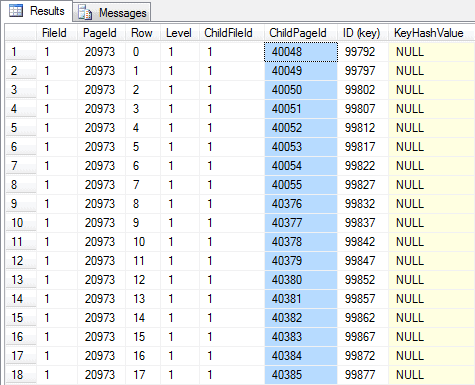
(Figure 04 – Index non-leaf level)
|
1 2 3 4 |
-- Looking at a leaf page (choose one from the level above) -- The last page should show some space left, waiting for the next inserts in the clustered index DBCC PAGE (36, 1, 40048, 3) GO |
Now let’s suppose that this table hold many years of historical records and the most recent records can get updated, because that’s the way your business works. After some updates happening in the most recent records (script 04), you again check your index fragmentation and it is worse, showing 3.95% of logical fragmentation and 97.78 for page density: But those values are far from the threshold defined by your rebuild routine.
Script 04 – Updates in action and new fragmentation
|
1 2 3 4 5 6 7 8 9 10 |
-- Business rules and application in action UPDATE HistoricalTable SET ColumnB = 'Update bigger then 21 bytes free in each page.' WHERE ID >= 98000 AND (ID % 5) = 0 GO SELECT * FROM sys.dm_db_index_physical_stats(DB_ID('SimpleTalk'), OBJECT_ID('HistoricalTable'), NULL, NULL, 'DETAILED') GO |
A small fragmentation means nothing to do, right? Not so fast…
If we re-execute the same steps to analyze the rightmost branch of your index (Script 05) you will notice something very different from the first execution. Since the rows that get updated didn’t fit in the space available in each page, SQL Server has to execute a series of page splits to organize the index to respect the order of the index key.
Script 05 – Analyzing the rightmost branch after fragmentation
|
1 2 3 4 5 |
-- Checking root page and get references to the rightmost non-leaf pages (figure 05) -- Note that new pages (out of order) are shown... DBCC TRACEON(3604) DBCC PAGE ('SimpleTalk', 1, 20650, 3) GO |
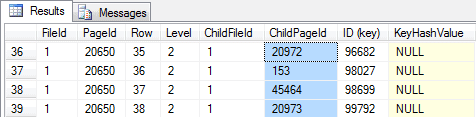
(Figure 05 – Index root level with fragmentation)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
-- Non-leaf index page (figure 06) -- Note that all child pages are NOT ordered DBCC PAGE ('SimpleTalk', 1, 45464, 3) GO -- Non-leaf index page (figure 07) -- Note that all child pages are NOT ordered DBCC PAGE ('SimpleTalk', 1, 20973, 3) GO -- Looking at a leaf page (choose one from the level above) -- The page now shows some space left. In this page, 4866 bytes (m_freeCnt = 4866). DBCC PAGE ('SimpleTalk', 1, 40048, 3) GO |
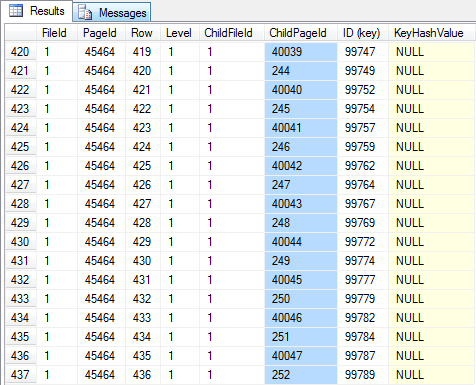
(Figure 06 – Index non-leaf level with fragmentation)
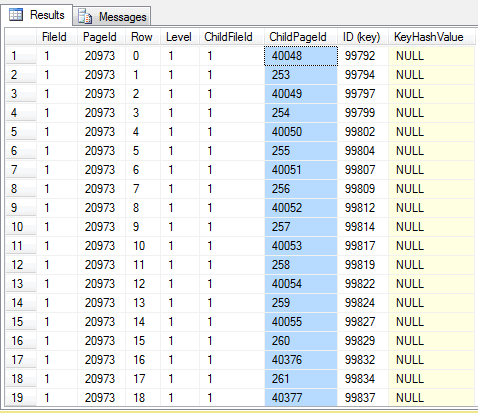
(Figure 07 – Index non-leaf level with fragmentation)
Checking the non-leaf level starting from row with ID 98000, we can clearly see that the logical fragmentation for this b-tree branch should be bigger than 90%, since the physical order of pages in the leaf level is not the same as the logical order. This means that the most accessed pages are out of order (potentially avoiding read aheads, but if they are hot they will be in the data cache anyway), leading to a greater logical fragmentation than represented by the DMV.
Maybe this doesn’t seem that bad, but another aspect also worries me. If you check the details of a page in the fragmented part of the leaf level, it will show that, on average, only 50% of the page is used (m_freeCnt in the page header). Since the most accessed pages are about half empty, this means that you are wasting space in your data cache, and if your table has a significant size and the updates touches GBs of data, you are wasting half of the space used by those pages. In this case it doesn’t seem that bad due to the low number of pages, but we’re working on a small set of data, probably your SQL Server has a lot more GBs that can be wasted.
You can check for the space used (and available) inside the data cache by using sys.dm_os_buffer_descriptors. In the script below I show the average space free (or wasted) for this databasein each page loaded in cache. This is without grouping by object, something worth monitoring in your environment.
Script 06 – Checking the data cache from free space
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
-- Clean the data cache CHECKPOINT DBCC DROPCLEANBUFFERS GO -- Bring fragmented pages to memory SELECT COUNT(*) FROM dbo.HistoricalTable WHERE ID >= 98000 GO -- In average, 3895 bytes are wasted in each page. SELECT AVG(free_space_in_bytes) FROM sys.dm_os_buffer_descriptors WHERE database_id = DB_ID('SimpleTalk') GROUP BY database_id GO |
To check for the real fragmentation in this branch (without using DBCC PAGE), you can re-execute the script but as well as the cluster index, you can create a filtered non-clustered index (script 07) that mimics your original data structure and check for fragmentation after all the updates are made. This non-clustered index showed me a logical fragmentation of 99.75% and page density of 50.02%.
Script 07 – Filtered non-clustered index creation
|
1 2 3 4 5 |
CREATE NONCLUSTERED INDEX idxNCL_Filtered ON HistoricalTable (ID) INCLUDE (ColumnA, ColumnB, EventDate) WHERE ID >= 98000 GO |
Conclusion
A considerable fragmentation in specific branches of an index, not seen as a representative change in the overall index fragmentation, may be happening to your servers and frankly, you can’t always prevent those from happening. Partitioning your index and using a different fill factor for each partition would probably give you the best results, but this isn’t the main concern in this article.
I want to alert you to the potential problem on relying on thresholds – like 20% or 30% – to rebuild and reorganize all your indexes. This usually won’t suffice and may lead to degradation of performance, especially for large tables; the one you normally care about the most. Even when working with partitions, keeping the data from the current year in the “hot partition” can make your year have a great start and be a problem during Christmas.
In this simple case a small table shows 3% logical fragmentation and 97.7% of page density for the whole index, and that’s correct for the whole table, but for the most-used pages you would see a huge logical fragmentation and 50% of page density.
That’s one of the reasons I worry when people take those thresholds as being the absolute truth and don’t think about the patterns of data access and manipulation in their own environment, not mentioning the collateral effect and real impact that those may be causing to your hot spots in the database. You, as the DBA responsible for your data should know better than anyone the behavior of your SQL Server and databases.
Of course that is better having a threshold and maintenance plan than to have nothing, but as Paul Randall (said in his blog), don’t treat those numbers as absolute truth.
Take care, and remember, there is always more than meets the eye…
Load comments