Along with SQL 2012 came FileTable technology, which simplifies the management of large volumes of structured and unstructured documents. In this article Feodor describes the technology and how it can be valuable.
In this article I will cover the following topics:
- What is FileTable technology?
- How to set it up?
- How to prepare the indexing for the FileTable?
After the introduction to FileTable, I will give you the code that provides an example that, if you wish, you can run yourself, using Wikipedia articles used together with FileTable and Full-text search. The example serves to illustrate
- How to get out the XML from rows and save to FileTable
- What files can FTS deal with
- How to use FTS on FileTable
What is FileTable technology?
In short, FileTable is a new technology closely related to Filestream in SQL Server. Filetable enables unstructured (and semi-structured) data files to be stored and managed as part of a SQL Server database, and at the same time the files can be accessible via the Windows file system.
Furthermore, the Filestream and FileTable technologies can be combined with powerful Full-Text and Semantic searches in order to allow the user to take full control of document handling in an office.
The task at hand and how to handle overabundance of documents
For the purpose of this article I will use an existing database called WikiDB which contains about 12 million Wikipedia articles stored in XML format in an XML datatype column in the WikiDocument table.
In this exercise we will create a new database called WikiFilesDB, which utilizes the Filestream, Filetable and Full-Text searches, then we will export 50,000 of the articles from the WikiDocument table and will save them to WikiFIles table.
After the migration we will create a Full-Text search catalog and run some queries on the documents.
How to set up FileTable in a database
If you have not yet enabled FileStream for your SQL Server, you’ll need to do it via the SQL Server Configuration Manager, or maybe execute some PowerShell to do it:
|
1 2 3 4 5 |
$strComputer = "MyServer" $Instance = "MSSQLSERVER" $wmi=Get-WmiObject -computerName $strComputer -namespace "root\Microsoft\SqlServer\ComputerManagement11" -class FILESTREAMSettings | where {$_.InstanceName -eq $instance} $wmi.EnableFILESTREAM(3, $instance) "The access level of FILESTREAM is now set to $($wmi.AccessLevel), and the file share name is $($wmi.ShareName)" |
Then, in TSQL, you can run…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
-- Enable Filestream EXEC sp_configure filestream_access_level, 2 RECONFIGURE GO CREATE DATABASE [WikiFilesDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'WikiFilesDB1', FILENAME = N'Y:\WikiFileDB\WikiFilesDB.mdf' , SIZE = 8092KB , MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ), FILEGROUP [FS1] CONTAINS FILESTREAM DEFAULT ( NAME = N'WikiFilesDBFT', FILENAME = N'Y:\WikiFileDB\WikiFilesFT' , MAXSIZE = UNLIMITED) LOG ON ( NAME = N'WikiFilesDB_log', FILENAME = N'Y:\WikiFileDB\WikiFilesDB_log.ldf' , SIZE = 1024KB , MAXSIZE = 2048GB , FILEGROWTH = 10%) WITH FILESTREAM ( NON_TRANSACTED_ACCESS = FULL, DIRECTORY_NAME = N'FileTable' ) GO |
And now let’s create a table which will contain the references to the files:
|
1 2 3 4 5 6 7 8 9 |
-- Create FileTable Table USE [WikiFilesDB] GO CREATE TABLE WikiFiles AS FileTable WITH (FileTable_Directory = 'WikiFilesTb_Dir', FileTable_Collate_Filename = database_default, FILETABLE_STREAMID_UNIQUE_CONSTRAINT_NAME=UQ_stream_id); GO |
How to prepare the indexing for the FileTable
Note that during the creation of the FileTable I have explicitly specified the name of the Unique constraint for the StreamId column by specifying the optional FILETABLE_STREAMID_UNIQUE_CONSTRAINT_NAME=UQ_stream_id.
This way, we get a unique constraint created together with a non-clustered index which later on we can use for the Full-Text index.
In other words, instead of creating an extra index like this:
|
1 2 3 4 5 |
-- this script is just an example, a better way to do it is shown below CREATE TABLE WikiFiles AS FILETABLE WITH (FILETABLE_DIRECTORY = N'WikiFilesTb_Dir'); CREATE UNIQUE INDEX UQ_StreamId ON WikiFiles(stream_id); CREATE FULLTEXT CATALOG WikiFilesFT AS DEFAULT CREATE FULLTEXT INDEX ON WikiFiles (file_stream TYPE COLUMN file_type) KEY INDEX UQ_StreamId; |
We can actually skip the creation of the extra index altogether and create the objects like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- Create FileTable Table USE [WikiFilesDB] GO CREATE TABLE WikiFiles AS FileTable WITH (FileTable_Directory = 'WikiFilesTb_Dir', FileTable_Collate_Filename = database_default, FILETABLE_STREAMID_UNIQUE_CONSTRAINT_NAME=UQ_stream_id); GO -- create default catalog CREATE FULLTEXT CATALOG WikiFilesFT AS DEFAULT GO -- create the full-text index CREATE FULLTEXT INDEX ON WikiFiles (file_stream TYPE COLUMN file_type) KEY INDEX UQ_stream_id; GO |
How to get out the XML from rows and save to FileTable?
Each application using FileTables will have a different way of stocking the data, depending on where it comes from, but in our example we’ll use a database which contains about 12 million wikipedia articles. For this database called WikiDB, the idea was to take the entire data dump from Wiki: http://dumps.wikimedia.org/enwiki/latest/. The files are 27 and are between
enwiki-latest-pages-articles1.xml-p000000010p000010000.bz2
to
enwiki-latest-pages-articles27.xml-p029625017p037804211.bz2
The Wiki files are in XML format, and they contain multiple <page> XML nodes and each of them corresponds to a Wiki page.
The WikiDB database has a table which contains about 12 million rows and each one corresponds to a page.
The idea was to create an easy way to store the entire Wikipedia on my laptop. To do that, we’ll need to take all Wikipedia articles and to store them on the filesystem as part of a database which utilizes the FileTable technology.
Furthermore, the intention is to use Full-text search to search for words and phrases through the Wiki pages, while they are still available to other services.
At a first sight there is a slight problem with this task: how do we get the XML out of the SQL Server table? After all, SQL Server is notorious for having the ease of import of XML , yet a great difficulty in exporting it back to the file system. However with the FileTable technology it is not hard at all. All it takes is a simple query. We’ll start off by importing just one file just to ‘test the plumbing’.
|
1 2 3 4 5 6 7 8 9 10 |
declare @filename varchar(30); declare @wikifile varbinary(max); select @filename = 'Wikifile' + cast([ID] as varchar(10)) + '.xml' ,@wikifile = cast([WikiDocument] as varbinary(max)) from [WikiDB].[dbo].[WikiDocuments] where ID = 1; insert [WikiFilesDB].[dbo].[WikiFiles](Name, file_stream) values(@filename, @wikifile); |
What this code does is to simply take a row from the [WikiDB].[dbo].[WikiDocuments] table, converts the XML datatype to varbinary and saves it to the [WikiFilesDB].[dbo].[WikiFiles].
And if we right-click on the FileTable in WikiFilesDB, we can open an Windows Explorer window and see the file we just imported:
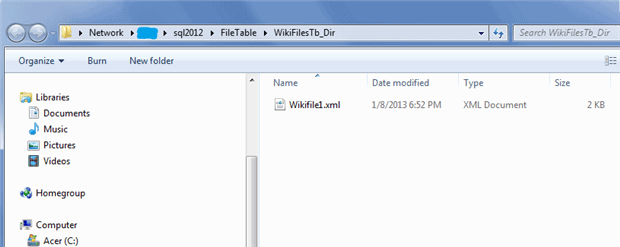
From here on, I can copy the XML file and paste it to a different folder, I can even modify the XML file with the use of external editor.
But how can we search the contents?
What files can FTS deal with?
The first question is: what file types can Full-text search handle?
The answer is just a matter of executing the following DMV:
|
1 |
select * from sys.fulltext_document_types |
There are 50 filetypes supported at this time, and XML is one of them.
How to use FTS on FileTable?
Earlier in this article I already created the Full-Text index on the FileTable.
Now I will actually execute a loop which inserts the XML files to the FileTable:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
DECLARE @intFlag INT SET @intFlag = 1 WHILE (@intFlag <=50000) BEGIN declare @wikifile varbinary(max); declare @name varchar(30); select @name = 'Wikifile' + convert(varchar(15),@intFlag) + '.xml' ,@wikifile = cast([WikiDocument] as varbinary(max)) from [WikiDB].[dbo].[WikiDocuments] where ID = @intFlag; insert [WikiFilesDB].[dbo].[WikiFiles](Name, file_stream) values(@name, @wikifile); SET @intFlag = @intFlag + 1 END GO |
For the purpose of this article, I will work with only 50,000 XML files, and in a later article I will explain the performance considerations for FileTable, including the scalability and performance of various file counts.
After completing the export and import of XML files to WikiFilesDB, it is time to re-build the Full-Text search catalog.
Before we hit the ‘Rebuild’ button, let’s prepare a script which will help us find out the status and how long it took to rebuild the catalog. For this purpose we are going to look into the default trace and I will slightly modify a script from my previous article “The default trace in SQL Server – the power of performance and security auditing“:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT TE.name AS [EventName] , DB_NAME(t.DatabaseID) AS DatabaseName , t.DatabaseID , t.NTDomainName , t.ApplicationName , t.LoginName , t.SPID , t.StartTime , t.IsSystem FROM sys.fn_trace_gettable(CONVERT(VARCHAR(150), ( SELECT TOP 1 f.[value] FROM sys.fn_trace_getinfo(NULL) f WHERE f.property = 2 )), DEFAULT) T JOIN sys.trace_events TE ON T.EventClass = TE.trace_event_id WHERE DB_NAME(t.DatabaseID) = 'WikiFilesDB' AND ( te.name = 'FT:Crawl Started' OR te.name = 'FT:Crawl Aborted' OR te.name = 'FT:Crawl Stopped') ORDER BY t.StartTime DESC |
Now let’s start the catalog rebuild with the following script and then let’s look at the default trace:
|
1 2 3 4 |
USE [WikiFilesDB] GO ALTER FULLTEXT CATALOG [WikiFilesFT] REBUILD GO |
When we execute the default trace query, we will get the start time of the Full-Text catalog rebuild:

Later on we can run the query again, and we will see the finish time of the Full-Text rebuild:

And here is another way to see the properties and the status of the Full-Text Catalog:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
USE [WikiFilesDB] GO declare @FTCatalogName nvarchar(250) set @FTCatalogName = 'WikiFilesFT' SELECT cat.name AS [Name], cat.fulltext_catalog_id AS [ID], CAST(FULLTEXTCATALOGPROPERTY(cat.name,'AccentSensitivity') AS bit) AS [IsAccentSensitive], CAST(cat.is_default AS bit) AS [IsDefault], dp.name AS [Owner], FULLTEXTCATALOGPROPERTY(cat.name,'LogSize') AS [ErrorLogSize], FULLTEXTCATALOGPROPERTY(cat.name,'IndexSize') AS [FullTextIndexSize (MB)], FULLTEXTCATALOGPROPERTY(cat.name,'ItemCount') AS [ItemCount] ,(SELECT CASE FULLTEXTCATALOGPROPERTY(cat.name,'PopulateStatus') WHEN 0 THEN 'Idle' WHEN 1 THEN 'Full Population In Progress' WHEN 2 THEN 'Paused' WHEN 3 THEN 'Throttled' WHEN 4 THEN 'Recovering' WHEN 5 THEN 'Shutdown' WHEN 6 THEN 'Incremental Population In Progress' WHEN 7 THEN 'Building Index' WHEN 8 THEN 'Disk Full. Paused' WHEN 9 THEN 'Change Tracking' END) AS PopulateStatus FROM sys.fulltext_catalogs AS cat LEFT OUTER JOIN sys.filegroups AS fg ON cat.data_space_id = fg.data_space_id LEFT OUTER JOIN sys.database_principals AS dp ON cat.principal_id=dp.principal_id WHERE (cat.name=@FTCatalogName) GO |
When we execute this query, we will get the following result:

And finally, let’s write some queries which will allow us to find words and phrases from the XML files we just imported. Keep in mind that the Full-Text search in this case is ignoring the markup nodes of the XML files and only the content is indexed.
Here are few various Full-Text queries:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
-- use the CONTAINS keyword to search for a single word SELECT top 10 * FROM [dbo].[WikiFiles] WHERE CONTAINS(file_stream,'music') -- -- proximity search SELECT top 10 * FROM [dbo].[WikiFiles] WHERE CONTAINS(file_stream, 'NEAR((landing,moon), 5, TRUE)') -- -- search for all forms of the word SELECT top 10 * FROM [dbo].[WikiFiles] WHERE CONTAINS(file_stream , ' FORMSOF (INFLECTIONAL, walk) '); -- -- using freetext SELECT top 10 * FROM [dbo].[WikiFiles] WHERE FREETEXT (file_stream, 'beatles and music' ); |
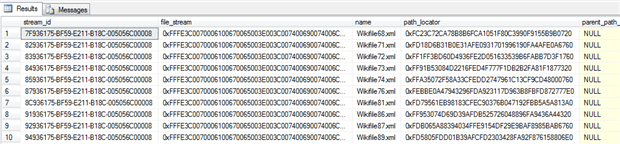
All of the above queries return only the handle to the documents and their properties, i.e. the contents as a binary string, the document name, the filesystem properties.
This is perfectly fine, since in a real-world situation we would like to have nothing more than a handle and we would like to process the documents on the application side and not to use SQL Server to return the entire dataset.
The result from the queries above looks like this:
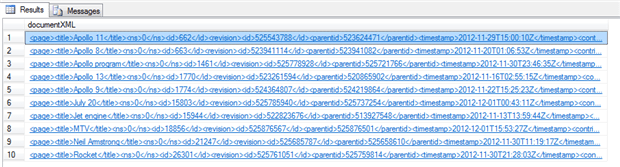
If we really wanted to see the documents’ contents in SQL Server Management Studio, we could run the following query:
|
1 2 3 |
SELECT top 10 convert(xml,file_stream) as documentXML FROM [dbo].[WikiFiles] WHERE CONTAINS(file_stream, 'NEAR((landing,moon), 5, TRUE)') |
And the result will look like this:
Conclusion
The Full-Text search combined with FILESTREAM and FileTable technologies in SQL Server 2012 can be a very powerful tool for the business. Keeping various documents stored in a central location and performing blazingly fast searches can improve the workflow for many people in the organization. Furthermore, it is very easy to export files stored within different databases and import them to FileTable storage in SQL Server, and thus making them available to the file system and other applications.

Load comments