In this series, there are …
- 1. Declarative SQL: Using UNIQUE Constraints
- 2. Declarative SQL: Using References
- 3. Declarative SQL: Using CHECK() & DEFAULT
SQL signaled a major leap from a file system to a relational databases system. A file is basically passive; it just holds the data. SQL, in contrast, allows you to specify, define it, and protect its integrity. While the choice of data type for a column is an important part of this, we will, in this article, be more interested in the CHECK () and DEFAULT options because they are important for ensuring that your data is correct.
Traditionally, file descriptions are in the application programs, such as the DATA DIVISION in COBOL, the FORMAT statement in FORTRAN, fopen() in C, or the Pascal ‘TYPE <file name>: FILE OF <record descriptor>‘ declaration.
But the Data Definition Language (DDL) in SQL is a separate, active sub-language. It is the DDL that defines the data types, not the host program; the DDL applies CHECK constraints, not the host program; the DDL maintains certain relationships, not the host program.
CHECK()
We probably all underuse the CHECK() constraints. Part of the problem is cultural: They do not exist in other programming languages. People generally rely on ‘transfer of training’ when picking up new skills, and it is more difficult to assimilate things that they have never come across; but a more subtle part of the problem is those SQL NULLs! Our language has three logical values – – True, False, and Unknown. The Unknown value shows up when you try to use a predicate with a NULL value. One of the principles of SQL is that NULLs propagate. This is why good SQL avoids NULL-able columns; the old heuristic was that fewer than 5% of the columns in a schema should be NULL-able.
When you do a Data-manipulation Language (DML) statement, (INSERT, MERGE, UPDATE, DELETE and SELECT), an Unknown logical result from a predicate is treated as a False. But an Unknown result in a DDL CHECK () clause is treated as a True. We call this the ‘benefit of the doubt’ option in SQL. Look at this skeleton code to see what I mean:
|
1 2 3 4 5 |
CREATE TABLE Test (test_id CHAR(3) NOT NULL PRIMARY KEY, null_val INTEGER CONSTRAINT oversized_value CHECK (null_val < 10)); |
Now try these test insertion statements.
|
1 2 3 |
INSERT INTO Test VALUES ('A', 1); -- no problems INSERT INTO Test VALUES ('B', 11); -- caught by constraint INSERT INTO Test VALUES ('C', NULL); -- benefit of the doubt |
If you want to play with a bit, try these simple queries.
|
1 2 3 |
SELECT * FROM Test WHERE null_val < 10; SELECT * FROM Test WHERE null_val > 10; SELECT * FROM Test WHERE null_val = 10; |
The simplest CHECK() constraints on the column use basic predicates. They establish such rules as minimums and/or maximums for numeric values or allowed values for a column. They use a LIKE predicate to define a regular expression for strings. They can include expressions, but you would, in general, prefer to keep these fairly simple. This information is passed on the optimizer along with statistics.
The most overlooked constraint for numeric data is one that will prevent negative or zero values in a column.
|
1 2 |
CHECK (order_qty > 0) CHECK (item_cnt >= 0) |
There is a horror story about a simple order entry system that allowed negative quantities to be ordered. When it would do the price extensions, you got a negative total and turn that into a refund to the customer. It did not take too long for less than honest people to figure out how to game the system.
Another overlooked constraint is for strings. You can enforce upper and lower case conventions with the UPPER() or LOWER() functions. Likewise, even simple regular expressions can save a lot of grief.
|
1 2 |
CHECK (xyz_code = UPPER (xyz_code)) CHECK (zip_code LIKE '[0-9][0-9][0-9][0-9][0-9]' |
The ISO convention is to use only unaccented uppercase ASCII Latin letters, digits and limited set of punctuation marks for standardized encoding schemes, so this simple constraint saves you a lot of programming. This subset of ASCII is part of all the Unicode character sets for languages, so that everyone on earth can write ISO encoding strings in their native languages.
The IN() predicate is useful for limiting the column to a fixed list of constant values. Think of it as a “local table lookup” in DDL. But the question becomes when do you use the IN() predicate or the REFERENCES clause. My rule of thumb is that if the list of possible values is short and static, then use the IN() predicate in a CHECK() constraint. If the list of possible values is long or is dynamic, then it is better to reference an actual lookup table. The definition of “long” and “static” are fuzzy; remember, this is a heuristic, not mathematics. SQL Server supports several thousand values in the IN() predicate.
Some SQL products have special optimizations for long lists; they sort the list and use a binary search, put it in a hash table, or self-organize it. Do not depend on this in SQL Server. A really long list probably be should be sorted in the code from most likely to least likely values.
Computed Checks
Since the constraint eventually is to evaluate to a predicate, we often forget that you can do a lot of math inside a predicate. Consider, for example, a simple check digit like the one used in many barcode and credit card validation applications.
Each digit in the barcode is assigned a weight by its position in the sequence within the barcode string. The final position holds the check digit. If you are faced with validating the old ten digit UPC barcode where the 10th digit is the check digit then we need to use modulus 10 arithmetic: Multiply each digit by its weight. The multiplication will automatically cast each digit to an integer, but you could be explicit and use a CAST() function. This also adds documentation.
Some of these expressions will be a bit unnatural and complicated to write without loops. However, the payoff is that it is done, one way, one time in one place in the database, so there is no chance of an application program forgetting to do. People too often forget that the function of the database is to maintain data integrity, as well as to store it
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
CREATE TABLE Products (barcode CHAR(10) NOT NULL, CONSTRAINT All_Numeric_Barcode CHECK (CAST(barcode AS INTEGER) NOT LIKE '%[^0-9]%'), CONSTRAINT Valid_Checkdigit CHECK ( SUBSTRING (CAST(barcode AS INTEGER), 10, 1) --- check digit = (SUBSTRING (CAST(barcode AS INTEGER), 1, 1) + 2 * SUBSTRING (CAST(barcode AS INTEGER), 2, 1) + 3 * SUBSTRING (CAST(barcode AS INTEGER), 3, 1) + 4 * SUBSTRING (CAST(barcode AS INTEGER), 4, 1) + 5 * SUBSTRING (CAST(barcode AS INTEGER), 5, 1) + 6 * SUBSTRING (CAST(barcode AS INTEGER), 6, 1) + 7 * SUBSTRING (CAST(barcode AS INTEGER), 7, 1) + 8 * SUBSTRING (CAST(barcode AS INTEGER), 8, 1) + 9 * SUBSTRING (CAST(barcode AS INTEGER), 9, 1)) % 10) ); |
See how easy it is to avoid procedural code in favor of declarative code?
As an exercise, try doing the Luhn algorithm (https://en.wikipedia.org/wiki/Luhn_algorithm) with CASE expressions instead of the look-up table. The CHECK() constraint is a little long, but pretty fast.
CASE Expressions
You can use a CASE expression in a CHECK constraint. It becomes a replacement for if-then-else logic procedural code. The general outline for this idiom is:
|
1 2 3 4 5 6 7 |
CONSTRAINT <constraint_name> CHECK (CASE WHEN <predicate_1> THEN 'T' WHEN <predicate_2> THEN 'T' WHEN <predicate_3> THEN 'F' ... ELSE NULL END = 'T'); |
The CASE expression tests the WHEN clauses in the order they are written, and stops at the first predicate that evaluates to TRUE. Therefore, you can get a performance boost by putting the most likely test, at the front of the CASE expression. Finally, be careful about the ELSE clause; I like to use “ELSE NULL” explicitly so that I can use it as a marker when I discover a need to put more test code in the expression.
Computed Columns
Computed columns are a bit like a VIEW but in it in the DDL rather than the DML. The syntax is simply to declare the column as
|
1 |
<column_name> AS (<formula>) [PERSISTED] |
The optional keyword PERSISTED, says that the computation of the formula will actually be materialized in the table. The SQL engine looks to see if any of the component columns of the formula are changed and re-computes the value of the column anew. Without the PERSISTED keyword, the SQL engine performs the computation only when the column name is used in the DML.
Because division by zero is a common problem, you will find this trick to be handy. The quotient of a division by zero becomes a NULL, rather than an error.
|
1 2 3 4 5 6 |
CREATE TABLE Zero_Divide_Test (.. numerator INTEGER NOT NULL, denominator INTEGER NOT NULL, quotient AS (numerator/NULLIF(denominator, 0)) .. ); |
I would not use a user-defined function (UDF) in a computed column. In general, they cannot help the optimizer, they do not port to other RDBMS, and there will be problems with indexing the column if they are not flagged as being deterministic and precise.
Persisted computed columns can be indexed in SQL Server. They must be deterministic; meaning that the formula always returns the same result when given the same inputs. There are also some precision requirements. Precision requirements are usually not a problem; we do not use approximate data types very often.
Multi-Column CHECK Constraints
CHECK() constraints come in two flavors. So far we have talked about the simple column level constraint. However, a CHECK() constraint can be a multi-column predicate. Probably the most common example of this is with temporal values. So it has to be modeled, using the ISO open intervals approach. This means that we have (start_date, end_date) pairs in the tables. But it also means we need a constraint for CHECK(start_date <= end_date); for each interval.
Status attributes are related to temporal constraints and have to be modeled with multiple columns. A status is a state of being and things exist in time as well as space. A transition constraint says that the status can change only in certain ways over time. For example, you have to be born before you can die, you have to get married before you can be divorced and you can be re-married after a divorce.
In order to enforce a transition constraint, we need the current state and the previous state of an entity. But we also need to limit the pairs of valid current and previous states. Transition constraints are usually modeled with the state transition diagram. This is made up of arrows and boxes that show the direction of flow in the model (see diagram).
A declarative way to enforce transition constraints is put the state transitions into a separate table and then reference the legal transitions. This requires that the referencing table have both the previous, and the current state in two separate columns. Using this example, we would have something like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE TABLE State_Changes (previous_state VARCHAR(15) NOT NULL, current_state VARCHAR(15) NOT NULL, PRIMARY KEY (previous_state, current_state)); INSERT INTO State_Changes VALUES ('Born', 'Born'), -- initial state ('Born', 'Married'), ('Born', 'Dead'), ('Married', 'Divorced'), ('Married', 'Dead'), ('Divorced', 'Married'), ('Divorced', 'Dead'), ('Dead', 'Dead'); -- terminal state |
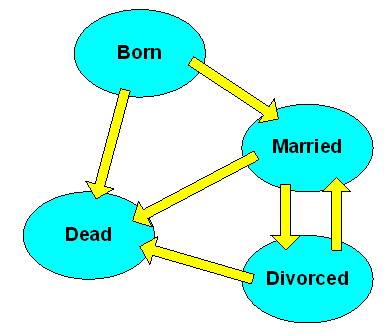
The referencing table looks like this.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE MyLife (.. previous_state VARCHAR(15) DEFAULT 'Born' NOT NULL, current_state VARCHAR(15) DEFAULT 'Born' NOT NULL, FOREIGN KEY (previous_state, current_state) REFERENCES State_Changes (previous_state, current_state) ON UPDATE CASCADE, ..); It is not always realized by developers that a foreign key can be multi-column. |
DEFAULT
The DEFAULT clause is attached to a column in the table and gives a value that can be used to construct a complete row with an INSERT INTO statement. There are some other uses for defaults, but I will skip those for now.
The value is usually a constant of the same data type column to which it belongs. The reason that I specified that the types must match, is that a lot of programmers
- put the default value in quotation marks, even when they are numeric types,
- do not use standard data formats
- oversize or under-size the value.
Besides being sloppy programming, these habits require the database to cast the default value to the proper data type, size and precision, which can only waste resources.
Many programmers do not know that the values list of an INSERT INTO statement can include the word DEFAULT. If the column is NULL-able, then the “default DEFAULT” is NULL. It is probably less surprising that almost nobody knows about the DEFAULT VALUES option. This is a shorthand for a VALUES list made up of nothing but defaults. Obviously, this assumes that all the columns have a default value declared, which isn’t often the case.
|
1 2 3 |
INSERT INTO <table name> [(<column_list>)] VALUES ({ DEFAULT | NULL | <expression> } [,..n]) [,..n] | DEFAULT VALUES |
The DEFAULT option does not have to be a simple constant. It can be a system-level function, such as CURRENT_TIMESTAMP (please stop using the old Sybase/UNIX getdate() function call). This can be very handy for time-stamping a row. SQL Server has a range of such functions that, when used as DEFAULTs, are valuable for auditing changes in the data.
But the default can also use a sequence. First, you need to use a CREATE SEQUENCE statement. This statement creates a schema level object that is accessible to any user. It is not part of a table. It is not a procedure that belong to one user. The idea is that a user can invoke the sequence with a special syntax that is used wherever an integer value of the sequence’s data type would work.
If you want a physical model, imagine you are in the butcher store. You walk in and pull a service ticket number from a roll of tickets on the counter. Sequence numbers are generated outside the scope of the current transaction, just like the tickets. The basic options are fairly simple. Let’s look at the roll of tickets (i.e. CREATE SEQUENCE). It has to be declared with parameters that define behavior.
|
1 2 3 4 5 6 7 |
CREATE SEQUENCE Service_Ticket_Seq AS INTEGER START WITH 1 INCREMENT BY 1 MINVALUE 1 MAXVALUE 100 CYCLE; |
I can put a SEQUENCE in the DEFAULT clause of the DDL for table:
|
1 2 3 |
CREATE TABLE Butcher_Shop (ticket_nbr INTEGER DEFAULT NEXT VALUE FOR Service_Ticket_Seq, ..); |
The numbering will cycle when the sequence reaches 100 in this example and start over at 1. Besides being declarative and giving you lots of control, the NEXT VALUE can be used anywhere that allows its data type.
Conclusion
SQL has evolved to be much more declarative than when it was first created. I would recommend that you pick a feature you do not know well, and spend an afternoon seeing how far you can push it. You will be surprised how much procedural code you can remove.
Load comments