Over the past decade, Red Gate has learned a lot, often the hard way, about the value of delivering software early and often or, perhaps more accurately, the cost of not doing so. Here, we explain what exactly we’ve learned and how we’ve adapted our software delivery processes, as a result.
The Cost of Failing to Deliver
The basic template for many early Red Gate Software projects, for either a new tool or a major release of an existing one, was relatively straightforward. We’d come up with product brief, establish a rough timeline, and put a team to work.
In one particular project, we assembled a team of seven brilliant people to work on a tool. The product brief was wide-ranging and visionary. We put our best developers and testers to work on the code, our best UX people on design, assigned an experienced project manager to lead the whole adventure, and set them to work. The team worked diligently and relentlessly on a project for 12 months in order to deliver on our vision, the equivalent in hours of one person working on it solidly for about 9 years.
The tool, when it finally arrived, delivered more-or-less everything that we’d agreed. Yet, from our customers’ perspective, it turned out not to be the revolution we’d been hoping to deliver. In fact, in retrospect, we realized that this project had taken a tool with steady growth and actively stopped it from continuing to increase revenue. In effect, the team had each wasted a year of their professional lives.
We thought we’d done everything right. We’d put our best people on the project, with a compelling brief. We’d given them plenty of time to deliver against our hopes and expectations but, ultimately, we blew it.
So where did we go wrong? Early feedback from existing customers seemed to suggest buy-in to our vision, but we didn’t sustain the conversation. We didn’t spend enough time, early on, asking our customers what they really wanted. We believed in our software development model; after all, with tools such as SQL Compare and Data Compare behind us, it had proven pedigree. We also believed in our vision for this tool. Perhaps, in the cold light of hindsight, there was an element of “selective hearing” in our early conversations with customers, finding reasons to disregard that which didn’t fit into our vision, and with an unshakeable belief that once we’d delivered on this vision, everyone would “get it”.
Crucially, we sat on 12 months’ inventory of code without our users receiving a single benefit. They saw very little of our efforts, and so as the project progressed we received relatively little feedback. We’d set ourselves on a one-way track to the wrong destination.
We’d called ourselves chumps before, for failing to spend enough time with our customers, talking to them, watching them work, learning what problems they face and what they really needed from our tools. However, we clearly still had much to learn.
Lessons learned
Skip forward to 2008 and, despite its mistakes, the 25-person company had become a 137-person company. We’d learnt an enormous amount from our earlier experiences; they were galling, but not terminal, and we had a chance to put things right. When a team assembled to work on version 4 of ANTS Performance Profiler, we decided to prototype a new way of working.
At the start of the APP4 delivery cycle, a computer ‘detox’ helped cut the teams ‘ties’ to the design of previous versions of ANTS Performance Profiler; there was no good reason why the future of the product should be constrained by its past.

Computer detox: before and after
We implemented sketching techniques that allowed us to come up with ideas and iterate them very quickly. We talked to customers as early and often as possible, getting tons of constructive feedback and immediately incorporating this into our plans for the product.
Crucially, we delivered frequently; we put new releases, new features into the hands of our users as quickly as possible. These were ‘controlled’ deliveries, to a select group of 20-30 users, but their feedback was vital, and we incorporated it in the next iteration. The entire project took us seven months, was a huge success and largely responsible for a 50% increase in the NET Tools division revenue, in the year following its release.
Our earlier lessons were still painful to think about, but we’d definitely begun to learn from them, and had made real changes to the way we developed software.
No iron underpants
We learned a lot from the APP4 project and in the immediate aftermath could have gone further. We had projects getting started to upgrade several popular tools, each with large and enthusiastic user bases, and had the opportunity to experiment further with even more frequent releases and to hone the way in which we deployed software to our users.
And we bottled it.
Controlled delivery to tens of users was one thing, but pushing out frequent releases to hundreds or even thousands of users seemed like a bigger, scarier thing altogether. We didn’t know what regular releases would mean for our customers, or how they could negatively affect the product. We were afraid of pushing out builds with major bugs in them, overnight or just before the weekend, and not realizing we’d caused significant problems for our customers until the next morning or the following week.
We were cowards: cowards because we didn’t understand how or why to use the technology we’d been developing, and cowards because we were too afraid to experiment, and as a result we missed a trick. If we’d done then what we know how to do now, this story would be half as long.
Red Gate and the Toyota Way
Simon Galbraith, one of Red Gate’s CEOs, met Bryan Jackson, the former head of Toyota’s UK manufacturing business, and copies of The Toyota Way started to spring up all over the office. Toyota revolutionized the automobile industry in the 1980s, and the software industry steadily imported their methodologies under the mantle of lean software development, as embraced by Agile development techniques such as Scrum.
Most of our developers, testers and project managers signed up for further lean, agile or scrum master training. Whiteboards sprang up all over the office. In projects such as APP4, we’d already started to embrace concepts such as Kaizen (small, frequent change) and, slowly, the way we made software continued to change for the better.
However, some skepticism remained over whether we could apply the Toyota principles successfully to the teams that create our tools. Central to the Toyota Way is the Plan–Do–Check–Adjust (PDCA) cycle, and the notion that a team can achieve rapid improvement by frequent, small change, and so frequent, rapid iteration through each PDCA cycle.
In Scrum, the “Do” part of the cycle is the sprint and, in practice, most teams focus all their efforts here, neglecting, in particular, the Check (sprint review), and retrospective, where they reflect on what they learned from the previous sprint and adjust their processes accordingly.
This is a particular problem for deployments. Our developers write code, test it, fix it, test it, refactor it, and test it again. In other words, their code and testing routines are naturally subject to iterative improvement, to the point where the code is robust, testing procedures thorough, and we spot and fix problems very quickly.
Deployments, however, we tend to treat differently. Unlike code and test routines that are subject to iterative improvement from very early in the delivery cycle, there is a tendency to defer the development of a deployment process until much later in the cycle. It is not refined and honed in the same way as our code and tests. Consequently, our development teams were still suffering from deployment pain, both chronic and acute.
- Delayed deployments cause chronic pain. It means you can’t deliver to the customer. This can last 6 months, a year, sometimes longer.
- Failed deployments cause acute pain. The team regularly pushes releases to production, so the new features are in customers hands, but each deployment ‘breaks something’. This is typically 24-48 hour pain, and causes distress to the team and users alike, until the team finds a cure.
Many of our early projects suffered chronic deployment pain. In later projects, we were scared of causing our customers acute pain. We thought that deploying to thousands of customers was a big and scary thing to do, and that we ought to make sure we did a lot of very careful planning, and get it right.
We were wrong.
Yes, deployments are hard, but rather than long-winded planning, they need constant practice, testing and refining, and we could only do this by deploying early. How often and how quickly we complete each PDCA cycle determines or rate of learning and improvement. If deploying to users is not part of this cycle, then we don’t tune and refactor our deployment process, and so we remove some of the most critical inputs to the check-and-adjust part of the cycle.
Leaner and wiser
In mid-2011, Neil Davidson (our other CEO) bought 100 copies of The Lean Startup as soon as it released in the US. Anyone who wanted to read a copy was free to take one, and the books disappeared within hours. As an established company with twelve years of innovation under our belts, there ideas in The Lean Startup that didn’t directly apply to Red Gate, but many more that did. In particular, ideas around ‘immune systems’ and regular releases resonated deeply with what we’d already begun working towards.
When the SQL Tools division began work on SQL Connect in November 2011, the team were ready to bring together all of the lessons we’d learnt as a software company. The SQL Connect team worked on the product for ten days before releasing, and then in the following six months shipped more than forty further releases to our “early adopters”, using an automatic update mechanism.
By using a lean approach, we were able to tackle very early issues relating to usability, and to our customers’ understanding of what the tool did. We followed up on this feedback, did regular usability sessions with our beta customers, worked very hard to understand their experience when trying to get started with the tool, adapted it quickly, and re-released.
Other projects benefitted from this ‘lean’ approach to releasing software. The team working on Nomad (a Visual Studio extension, and associated cloud-based build service, for building mobile apps) have adopted the mentality that “every commit is potentially releasable“. Every time a developer commits a change, it pushes a new build to Staging. From there, a single click can release the new build to users. The VS extension is auto-updating; it checks every hour for updates and applies them in the background upon VS shutdown or startup.
In such circumstances, one discovers very quickly the importance of the ‘immune system’, which tests and monitors their builds for potential problems, and the urgency with which problems must be resolved. Most ‘beta’ customers have an extra degree of tolerance to small quirks in the software, but they still expect it to be sound in its fundamentals, and they are certainly won’t appreciate being treated as unpaid bug hunters.
In addition, Nomad automatically reports to base any exceptions experienced by users, so that the team can respond very quickly with a fix. The team can even send affected users a link to the staging build so that they can pre-test a fix before upgrading.
Deploying regularly is not entirely without pain and pitfalls, as we discovered in these and a few other projects that regularly auto-pushed updates to customers. In one memorable episode, a new release of Nomad broke the auto-updater. The team spotted the problem quickly and rolled back the release, but for a handful of users, that auto-update was to be their last. Sadly, we’re not yet at the stage of having an immune system that does auto-rollbacks if it detects a problem, but we’re working on it!
The Future of Deployments at Red Gate
We’ve learned a lot about “optimal” release cycles, and about the real need for an immune system that can alert you to problems caused by a new deployment, before they harm customers. We’ve developed a picture of the delivery process that looks a bit like this…
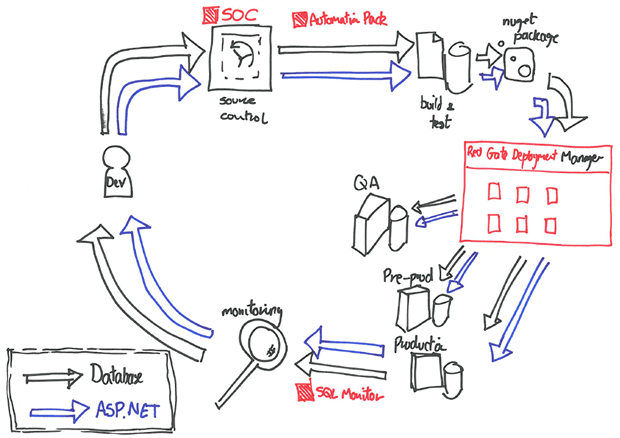
You’ll notice in this picture a new tool called Red Gate Deployment Manager, designed to help developers automate deployments to all their environments, and into which we’re pouring the benefit of many of our own experiences, over the past 10 years.
The interesting thing about this tool is that in its continuing development of it, we’re trying to implement many of the development and delivery practices we hope the tool itself will enable for our customers. Every time a developer checks in a change, our Continuous Integration process deploys it automatically to a Smoke Test environment, where developer can see and actually “use” it. As new features stabilize, we do scheduled deployments to a PlayPen area. From here, we deploy to an environment called Dog Food, so called because our own Dev Ops team take these releases and use them to deploy our internal infrastructure. We also deploy regularly (every two weeks, as long as we’re happy with the stability and quality of the current build) to a group of beta customers.
It had taken us six years to get to this point, and we still aren’t even nearly done (the “monitoring/immune system” component is still not there yet). However, the wider message coming out of the rapid development and iteration of projects such as this was clear: we’d revolutionized the way we create software, and we’d done so in a way geared towards continued change and improvement.
Summary
What is the real value of delivering software early and often? Most companies understand the advantages of small, incremental change, and the benefit of the continuous feedback loop that we establish by putting those changes into the hands of the customer as early as possible.
Equally, though, they are all too aware of the associated risks and costs, and they form a considerable barrier to “continuous delivery”. In particular, it is a significant undertaking to design and refactor a deployment process to the point where you really understand and trust it, and then to automate it to the point where placing a new piece of software functionality into the hands of your QA team, or your customers, is a matter of minutes rather than days. In addition to this are the risks of pushing software out to customer’s machines before it is really ready, and causing them problems, and shaking their confidence in your processes.
This barrier can remain in place until the organization learns the true cost of not delivering software early and often. One might try to quantify it in terms of the cost of a team’s wasted effort when they don’t find out early that they are heading in the wrong direction, or lost revenue when a release is delayed, or decline in reputation when a competitor beats you to the release of a new feature.
In reality, however, most companies find out the true cost the hard way – such as the NHS patient record system that cost £12.7 billion and ultimately failed. Red Gate has learned some hard lessons too, but emerged a better and stronger company. We still have an awful lot to learn but we believe that if everyone developed software the way we develop it now, the world would undoubtedly be a better place. Certainly, disasters such as the NHS project would happen far less frequently.
Load comments