
The performance of scalar functions sucks hard. Let’s see it in action using the Stack Overflow database – any size will work. I’ll set things up first in case you want to follow along:
|
1 2 3 4 5 6 7 8 9 10 |
USE StackOverflow2013; GO ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 140; GO EXEC DropIndexes; GO EXEC sp_configure 'cost threshold', 5; EXEC sp_configure 'max degree of parallelism', 0; RECONFIGURE GO |
I’m purposely setting my Cost Threshold for Parallelism to be low here because I want to demonstrate what happens when a query goes parallel, but I want to use short demo queries so you’re not twiddling your thumbs as you wait to reproduce this stuff on your Pentium 3.
I’m using compat level 140 (2017), but any compat level prior to 150 (2019) will work. (SQL Server 2019 has dramatically different effects, sometimes not so good.)
Let’s create a scalar function that just returns the number 1. Nothing more, nothing less:
|
1 2 3 4 5 6 7 |
CREATE OR ALTER FUNCTION dbo.Returns1 ( @Meaningless INT ) RETURNS BIGINT AS BEGIN RETURN 1; END; GO |
Then test its overhead by turning on actual execution plans and running these two queries back-to-back:
|
1 2 3 4 5 6 7 |
SET STATISTICS TIME, IO ON; SELECT COUNT(1) FROM dbo.Users; SELECT COUNT(dbo.Returns1(1)) FROM dbo.Users; |
The execution plan looks like no big deal – one of ’em costs 49%, and the other is 51% – what’s a couple of percent between friends?
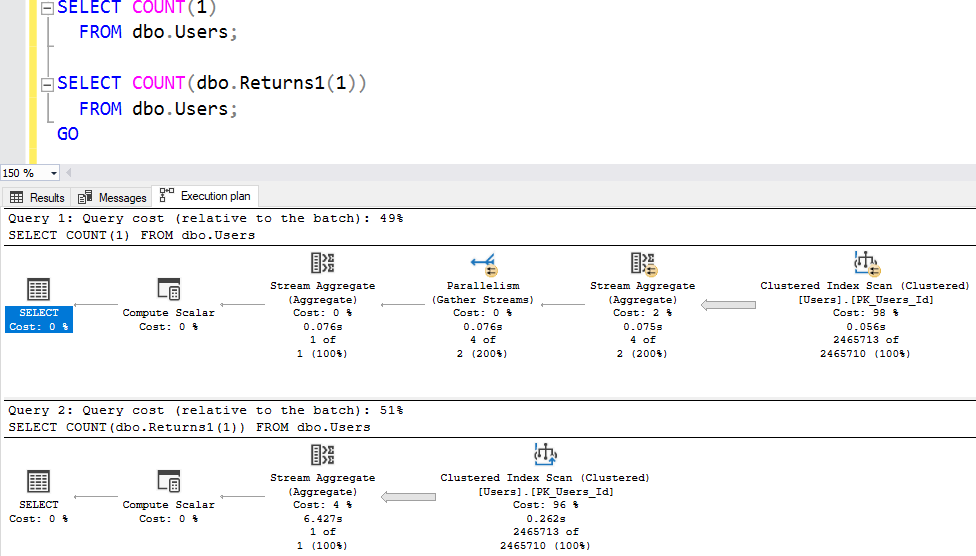
But remember, the percentages are based on the estimated costs – even when you’re looking at an actual plan. The percentages are simply garbage and meaningless – execution plans are full of lies. However, there’s one interesting thing that does stand out: the plan with the function doesn’t have parallelism. Until SQL Server 2019, if your query has a scalar function anywhere in it, your entire query plan goes single-threaded. Ouch. (Ironically, the contents of the function are allowed to go multi-threaded, so…yay.)
A better indicator of performance here is in the Messages tab:
- Without the function: 93 milliseconds elapsed time, 299 ms CPU time
- With the function: 6,427 ms elapsed time, 5,375 ms CPU time
Ouch. tl;dr – even if your scalar function doesn’t touch tables, it still cripples performance by forcing serial processing, blowing up your CPUs, and obfuscating your query plans. Scalar user-defined functions: not even once.

19 Comments. Leave new
so is rather preferable to use cross apply ?
Jose – if you’re using a scalar function, it doesn’t really matter how you refer to it in a query: you’re still screwed.
If you’re considering CROSS APPLY, you’re most likely thinking of a different kind of function: table-valued functions. Those have a totally different set of caveats.
SQL Server execution plans are like relationships…they are full of lies.
lol
been saying this for years to the devss don’t touch function in set based processing
I’ve spent a lot of the past couple of years extracting UDFs from code. Apologies if this is a stupid question but why do proprietary functions not suffer the same fate. Are they not the same under the hood?
Joe – this post is about proprietary (user-defined) functions, so I think what you’re asking is, “Why don’t system functions suffer the same performance fate as user-defined functions?” The short answer there is that Microsoft can do performance optimizations on system functions (building them into the engine itself) that they can’t do for our wild and crazy functions that can be unpredictable.
Does it matter if the scalar function is in the WHERE clause instead of the SELECT clause?
Terry – not in this example, no. You’re totally welcome to download the database and try it out, too.
Early on in my SQL career I put a function in the WHERE clause. I will never make that mistake again.
Brent, I agree with your point 100%.
In testing your example locally, I believe that I found something interesting. If you create another comparable function WITH SCHEMABINDING and then run the COUNT query for both functions, the performance is the same.
However, if you run a query that selects the DISTINCT results, the performance of the schema bound function is comparable to a query that doesn’t call the function at all. The performance of the function without schema binding is still extremely slow.
— here is the baseline
SELECT DISTINCT 1
FROM dbo.Users;
— still excruciatingly slow
SELECT DISTINCT dbo.Returns1(1)
FROM dbo.Users;
— much faster than the non-schema bound version and comparable to the query without the function call
SELECT DISTINCT dbo.Returns1WithSchemaBinding(1)
FROM dbo.Users;
That’s great, except, uh, that’s different results than my query. As long as you’re willing to change the query results, you can often make queries faster. 😀
Agreed. Changing the query results is probably not the best thing. 🙂
I was just trying to show that not all query patterns in SQL Server seem to exhibit the scalar UDF slowness when (1) the function doesn’t select from tables and (2) schema binding is enabled on the function. Removing the DISTINCT keyword from the queries in my test resulted in similar performance, where the schema-bound scalar UDF was much faster than the non-schema bound scalar UDF.
Scalar user-defined functions: bug by design… 🙂
SQL Server is a db engine, so it’s a bug, nothing else
Not UDF’s, but similar issues with reports putting RANK on the columns (legacy, they won’t re-write…you know the drill). I’m trying to gently push them into at least dumping the raw data into temp tables first, but for now, they know this query (overnight report fortunately), will be slow.
Your reference to Pentium 3 reminded me of one of the best videos ever created. Enjoy. https://www.youtube.com/watch?v=qpMvS1Q1sos
This is a load of BS. Time to get over the hysteria about UDFs. Same with cursors for that matter. They can be useful tools just as well as abused tools. They are not inherently evil.
Tom – ok, thanks for stopping by!
Not UDF but User-defined scalar functions. Only in empty tables then they become interesting …
I occurred a strange error:
Msg 596, Level 21, State 1, Line 0 Cannot continue the execution because the session is in the kill state.
It seems that error is generated when I use a cursor like :
DECLARE dbCursor CURSOR FOR SELECT (SELECT TOP 1 VAL FROM dbo.fn_Table(‘n:’,dbo.fn_Scalar) ORDER BY VAL) from table
If I taken the select to run it, it is ok.
If in cursor I execute only fn_Table OR fn_Scalar, it is ok.
If in cursor I execute BOTH functions, I have the above error.
In older versions of SQL server (than 2019) the cursor is running properly.
Could you, please, give me an idea?
Thank you.
Gratiela – I don’t do free support, sorry. Your best bet there is to contact Microsoft for support, or post a question at https://dba.stackexchange.com.