
This week, I’m demoing SQL Server 2019 features that I’m really excited about, and they all center around a theme we all know and love: parameter sniffing.
If you haven’t seen me talk about parameter sniffing before, you’ll probably wanna start with this session from SQLDay in Poland. This week, I’m going to be using the queries & discussion from that session as a starting point.
In this week’s posts, I’m using the 50GB StackOverflow2013 database (any size will produce the same behaviors, just different metrics.) I’ve got an index on Reputation, and I’m using this stored procedure:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE INDEX IX_Reputation ON dbo.Users(Reputation) GO CREATE OR ALTER PROCEDURE dbo.usp_UsersByReputation @Reputation int AS SELECT TOP 10000 * FROM dbo.Users WHERE Reputation=@Reputation ORDER BY DisplayName; GO |
Setting the stage: how SQL Server works today
When you call it for @Reputation = 2, you get an index seek + key lookup plan optimized for tiny amounts of data.
When you call it for @Reputation = 1, you get a clustered index scan plan optimized for large amounts of data.
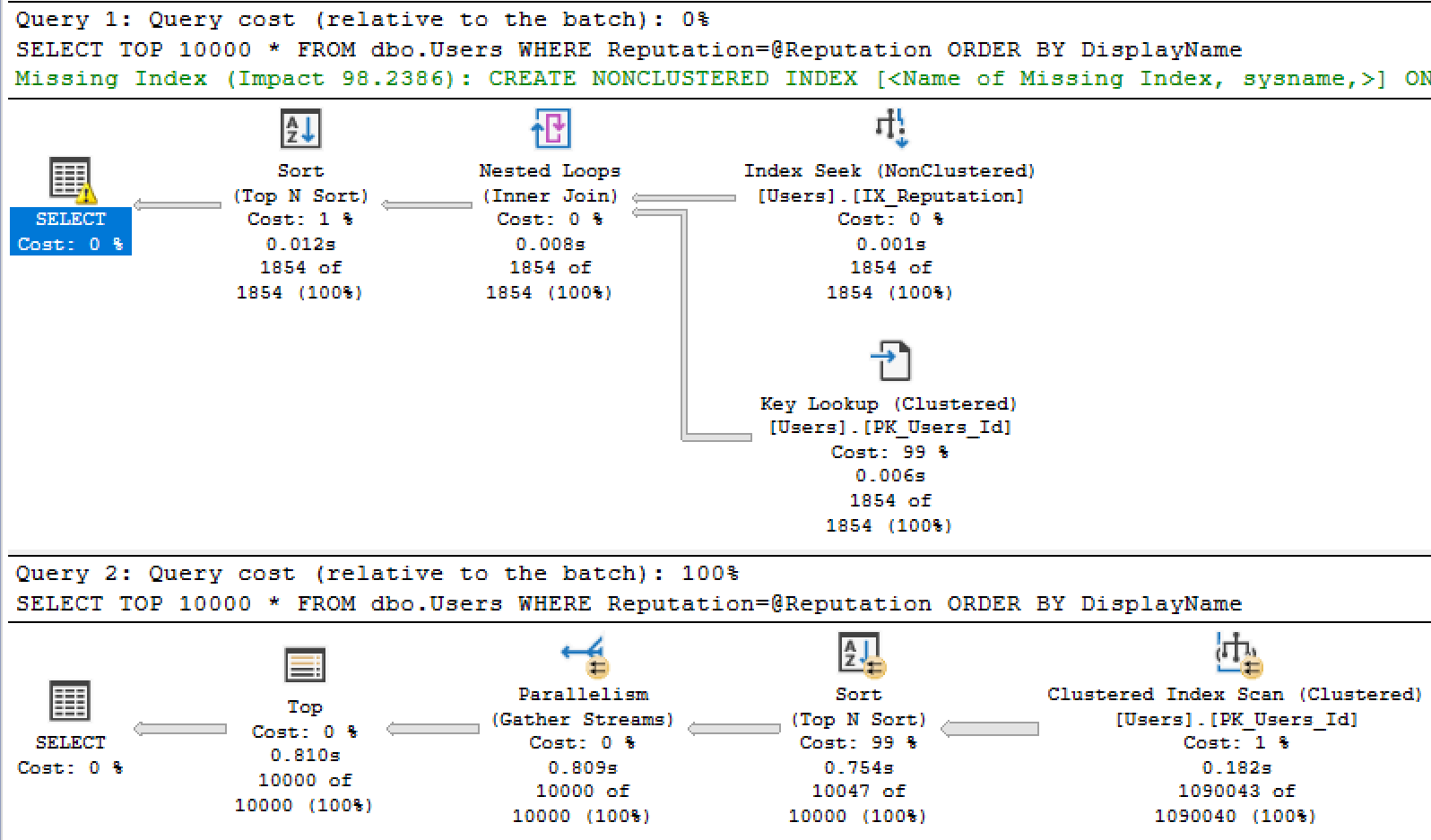
The easiest way to tell the sad story of plan reuse is with a table:
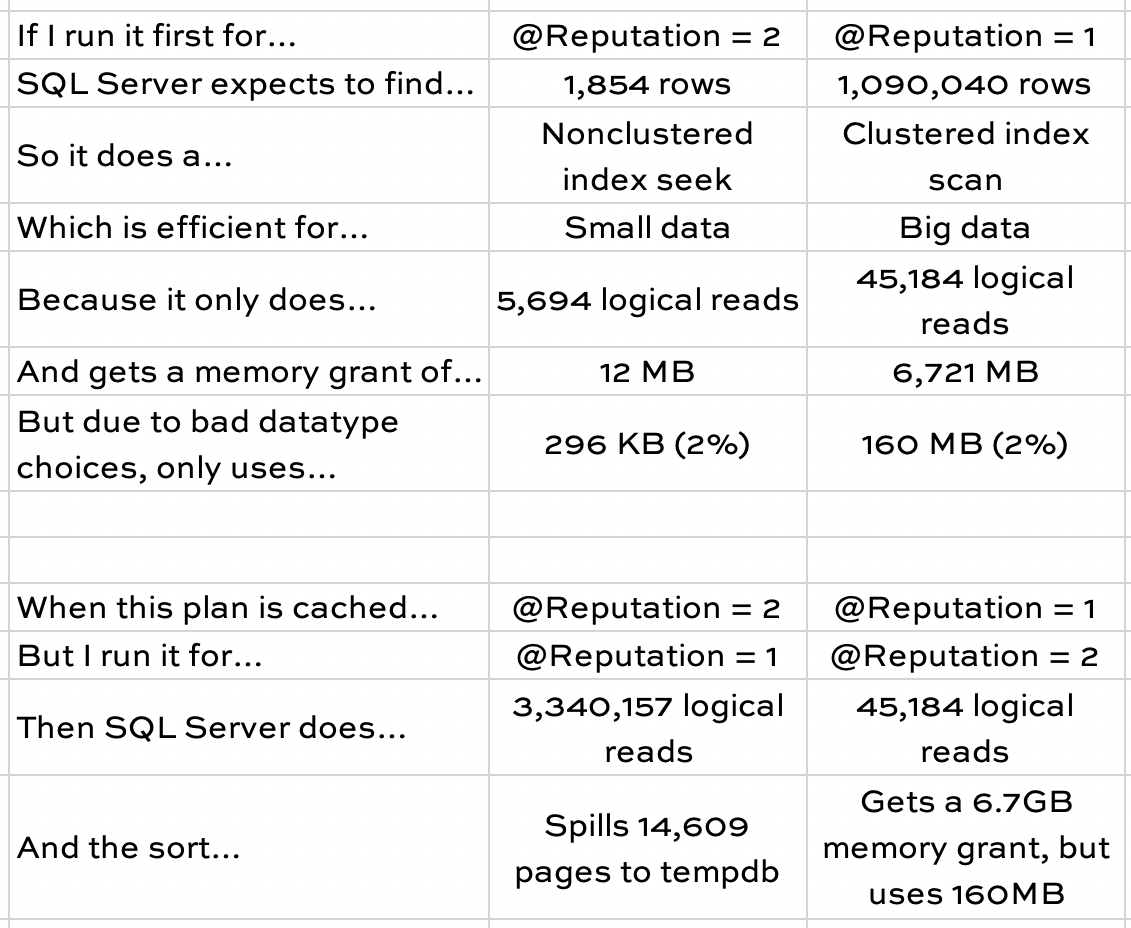
Neither the @Reputation = 1 or @Reputation = 2 plans are good for the other value. When SQL Server caches the scan plan, it runs into RESOURCE_SEMAPHORE issues due to unused large memory grants when other parameters run. When it caches the seek + key lookup, @Reputation = 1 performs poorly.
Note that this works the same way in SQL Server 2019, too, as long as your database is in 2017 compatibility level. (All of these screenshots & data were done on SQL Server 2019.)
This query presents three problems.
There’s no one right way to read the data. A nonclustered index seek + key lookup is fastest for small numbers of rows, but there’s a tipping point where a clustered index scan is more appropriate.
There’s no one right memory grant. The query uses between 296KB and and 160MB, a huge range. Even worse, because the data types are much larger than the average population actually uses – and because SQL Server doesn’t know that until runtime – the grant varies between 12MB and 6.7GB.
The index recommendation is flat out wrong. Clippy suggests that the user create an index on DisplayName, and then just include all of the columns on the table. If that’s created, it does solve the read problem, but we just doubled the size of our table, and it doesn’t fix the memory grant problem because we still have to sort 1,090,040 rows by DisplayName every time the query runs.
Until SQL Server 2019, the typical solution was to create an index on Reputation, DisplayName, and then living with the 10,000 key lookups (which really isn’t a big deal.) However, most people just can’t figure that solution out because Clippy’s missing index recommendation is on Reputation, and then just includes all the fields.
SQL Server 2019’s adaptive memory grants aim to solve one of them.
I wrote about adaptive memory grants a few months ago when the announcement first dropped, and the short story back then was that I liked it. In SQL Server 2019, when databases are in the 2019 compatibility level, the memory grant changes over time as the query runs.
I love this feature so much because it’s the kind of thing end users kind of expect that the database is doing already. When I demonstrate parameter sniffing to them, their usual response is, “Wait, what the hell do you mean that the database server doesn’t allocate different amounts of power to work with different parameters?” That’s an awkward moment. Adaptive memory grants help SQL Server catch up to user expectations.
In my work since then, I’ve gotten a little more nervous. I still like it, but…I’m getting nervous for the end user questions that are going to start coming in.
Your query’s memory grant is based on the LAST PERSON’S PARAMETERS, not yours.
I’ll demonstrate by running the proc a few times in a row, documenting its memory usage each time, showing how it adapts:
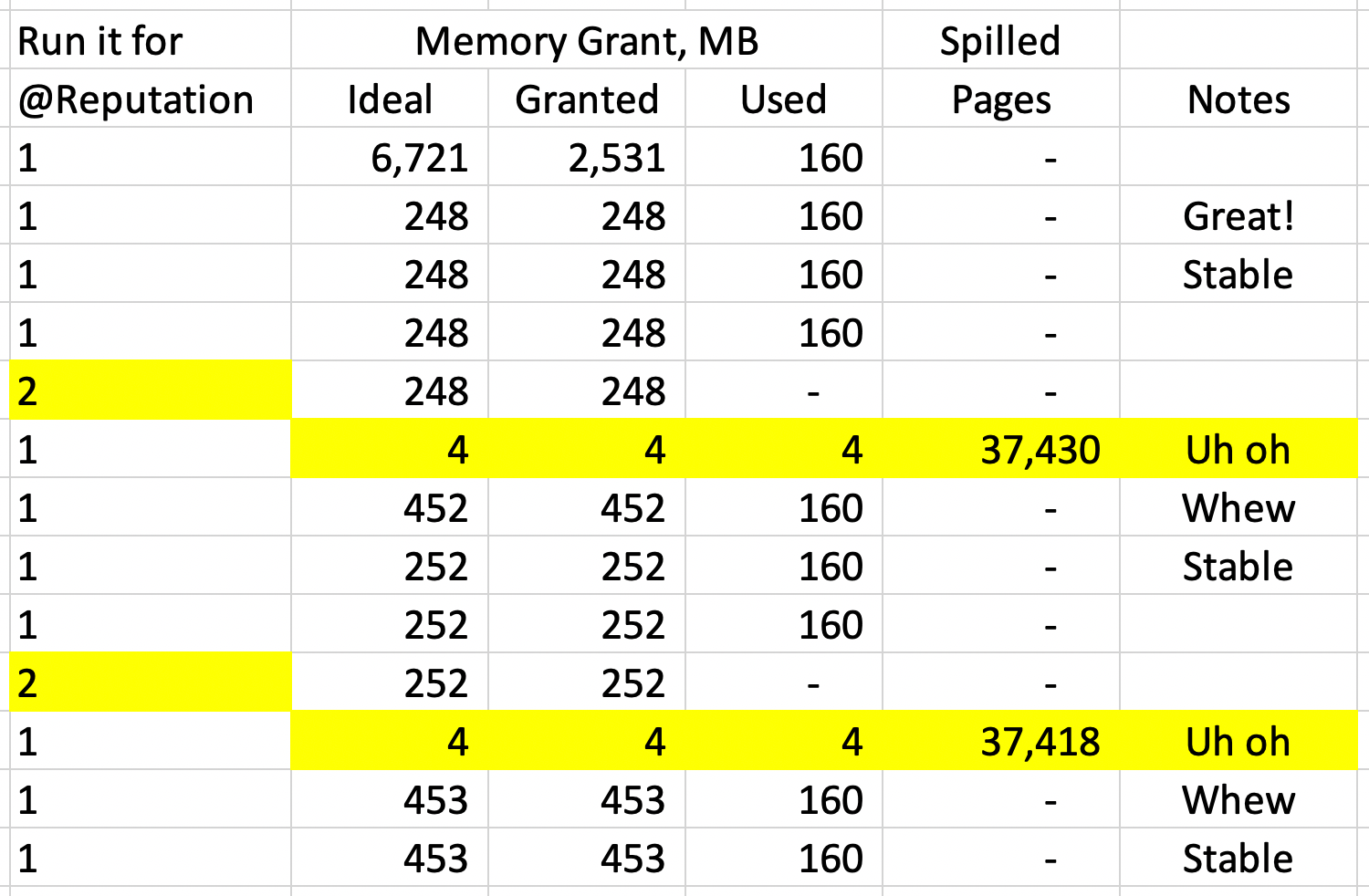
I’ll translate this into a support call:
- User: “Hi, I just ran the sales report and it was really slow.”
- Junior Admin: “What parameters did you use?”
- User: “I ran the national report for the last 3 years.”
- Junior Admin: “Oh yeah, you’re working with large time spans, it’s slow the first time you run it, but it’s really fast after that.”
- User: “What?”
- Junior Admin: “Yeah. I’m not sure why it seems to really pick up speed after the first time. But if you wait a while, it slows back down again. Maybe it has something to do with caching.”
Or maybe a more senior admin handles the call:
- User: “Hi, I just ran the sales report and it was really slow.”
- Senior Admin: “What parameters did the person before you use?”
- User: “What?”
- Senior Admin: “Yeah, see, your report speed is based on the parameters the last person used. SQL Server gives you the right amount of memory for their parameters.”
- User: “What?”
- Senior Admin: “If you want it to go fast, you have to run it a second time. The second time you run it, it’ll have the right amount of memory for what you asked for last time.”
- User: “What?”
- Senior Admin: “Unless someone else sneaks in and runs it at the same time. So yeah, your best performance will be if you run it twice when no one else is around.”
- User: “Okay.”
Or maybe it gets escalated all the way to our best staffer:
- User: “The other two admins don’t know why my query is slow. Can you run it and see what’s going on?”
- Señor Admin: “No.”
- User: “What?”
- Señor Admin: “Every time you run a query in SQL Server 2019, it can get a different memory grant based on the prior execution or lack thereof. If I run it for you now, it might be blazing fast, or unfairly slow.”
- User: “Was SQL Server 2017 like this?”
- Señor Admin: “Silence. Rather than looking at SQL Server’s behavior, we need to look at your query’s design and the supporting indexes. We need to look at the shape of the plan, understand why it’s getting that shape, and see what we can do to change your query to get a predictably better plan shape.”
- User: “That sounds like a lot of work. Can’t we just go back to 2017 compatibility mode where the grants were predictable?”
- Señor Admin: “I liked you a lot better before you went to SQLSaturday.”
Fortunately, Microsoft saw this coming, and adaptive memory grants give up when grants keep swinging around with no sign of relief, settling back on the original grant that they started with for the first compilation. However, the clock resets whenever you rebuild indexes, update statistics, or the plan gets dropped out of cache – which means that support call will get even worse. That poor admin is probably going to be right back to the old recommendation of, “Rebuild the index and then run the query again, and it’ll be super-fast” – all because it’s getting a plan customized for that incoming set of parameters.
 <sigh>
<sigh>
Like I said – I love this feature, but I’m getting nervous. I’m going to have to put some serious thought into the First Responder Kit scripts to make this easier to diagnose. In the next post, I’ll cover a new SQL Server feature that’s designed to help.
That’s why I built a whole series of classes around parameter sniffing. It looks so easy, but it gets so hard – and backfires so hard. The first class: Fundamentals of Parameter Sniffing. Conquer that, and you can move on to Mastering Parameter Sniffing.

18 Comments. Leave new
Good post Brent, as per usual, and a problem that definitely needs some attention. But I have been solving this one for a very long time now with a simple OPTION (RECOMPILE). I will jump through EXTRAORDINARY hoops to trade CPU ticks (compilation in this case) for just about anything else (avoiding diastrously-bad query plan reuse scenario here). Yes, compilations CAN become a bottleneck. But those are easy to identify when they occur and I have seen them just ONCE in my 25 years of SQL Server consulting and I have worked on systems with up to six figures of transactions per second.
The real issue here is data value skew. If you have that in your data – and most do – you simply MUST do some things differently or you can’t buy (or afford in the Cloud) a big enough server. I note that an IDENTICAL problem arises with what I call the “widely-varying input parameter” situation – think the @StartDate and @EndDate parameters that most report-style sprocs have. I have never seen a situation where it wasn’t appropriate to put OPTION (RECOMPILE) on those queries. You just cannot want to use the same query plan for one day as you would for ten years of date range.
My $0.02, and YMMV 🙂
Thanks, and I hear ya, but I tend to work in levels of concurrency where we can’t afford constant compiles. (Think thousands of batch requests per second.)
I should add too though – if it runs once per minute or less, and I can guarantee the code won’t run on the broken versions described in the video, then I totally use statement level recompile hints there.
Informative post *and* it made me lol.
BTW, is your blog post tomorrow going to be to use OPTION (RECOMPILE)? If so, sorry I stole your thunder!! 😀
May want to watch the video first. 😉 No, tomorrow definitely doesn’t involve that hint.
Great post! I loved de presentation and I learn a few things too.
Thanks!
Brent I love your dialogues…especially the escalation from the senior admin to senor admin…terrific!
Hahaha, thanks, Martin!
Such a funny guy! Good presentation skills are at least as important as the content. A presentation on parameter sniffing making me laugh more than once…go figure!
Tom – hahaha, thanks, sir.
Thank you Brent.
Hahaha – “I liked you a lot better before you went to SQLSaturday.”
As always, a great post, Brent and your humor should be patented.
My question is… is there any way to turn this “feature” off other than using a regressive compatibilty?
Jeff – hahaha, thanks sir. Yeah, thankfully they expose memory grant feedback along with the rest of the Intelligent Query Processing stuff as a database-scoped option. You can do an ALTER DATABASE to enable or disable it:
https://docs.microsoft.com/en-us/sql/t-sql/statements/alter-database-scoped-configuration-transact-sql?view=sql-server-ver15
Awesome… Thanks, Brent.
Ha! Señor Admin – new life goal 😉
Thanks, very interesting and entertaining ! 🙂