With traditional web application development in an on-premise environment, there is generally a large number of associated constraints: infrastructure provisioning, limited access to development teams, support from the operations team, scaling resources based on traffic spike, continuous maintenance of infrastructure, and more. The development effort is dependent upon infrastructure procurement and availability of new technology, thus delaying the delivery of business features and functionalities.
Database systems can be broadly categorized as relational database management systems (RDBMS) and non-relational NoSQL databases. Based on your requirements and use case, you can leverage any of these technologies to build your system architecture. NoSQL databases are document stores or key-value stores and maintain a flexible schema which can change over time, compared to Relational databases which have rigid schemas. NoSQL data stores have gained popularity because of their ability to scale horizontally for meeting high-performance requirements.
This article reviews design principles which can help you in designing a scalable, performant and highly available data intensive architecture. It focuses on database scaling and discusses how cloud infrastructure can help you to support fluctuating workloads.
Problem Statement
In a traditional web application architecture, generally, there is a single point of failure at the database layer. What happens if the database goes down? How can you address the latency associated with multiple database trips? How can you scale your database when there is a spike in load?
In an on-premises environment, scaling is always a challenge. Making a correct estimation of the expected traffic and configuring hardware resources to match the spike in load is not easy. Generally, you need to go through multiple layers of approval for infrastructure purchases and provide strong reasoning and documentation to support the new infrastructure purchase. However, in a cloud environment, you can benefit from the capabilities available while architecting a data-intensive application. Developing cloud native applications enables you to scale your workload dynamically based on fluctuating performance requirements. In this article, you will learn about design principles which can help you in designing a scalable, cloud-native data intensive architecture.
Database Scaling – Horizontal vs. Vertical
One of the challenges while designing data-intensive applications is database scaling and the ability to meet the service level agreements (SLAs) under high load scenarios. Database calls are expensive, and the number of database trips you make to cater to user requests plays an important role in the overall application performance. The ability to dynamically scale in or out resources based on the workload is one of the core strength of cloud architecture. This also ensures that the resource usage is optimized resulting in controlling the cloud expenditure.
Vertical Scaling
You can scale your database vertically by allocating additional resources (CPU, memory, storage) which will give you immediate performance benefits and allow you to process more transactions. When you bump into scenarios where your database cannot handle the spike in user requests from the application, you can scale your database vertically to use a larger instance size to gain superior performance.
Scaling your database vertically is very easy to implement. In a cloud environment, it is straightforward to change your database instance size based on your requirements, since you are not hosting the infrastructure. From an application perspective, it will require minimal code changes and will be fast to implement.
I would recommend running performance tests for your application and find out the optimal database instance size, which matches the performance service level agreements defined by the business. Keep in mind that every time you decide to increase your database instance size, you will incur additional resource costs.
The probability of overprovisioning resources is generally high with vertical scaling. However, the top cloud providers like Azure and AWS have made this process of scaling up/down very simple. Customers need not wait for new hardware to be provisioned and can change the database instance size on the fly. They can scale up the database size if they see any performance issues, and can scale down when it’s not required.
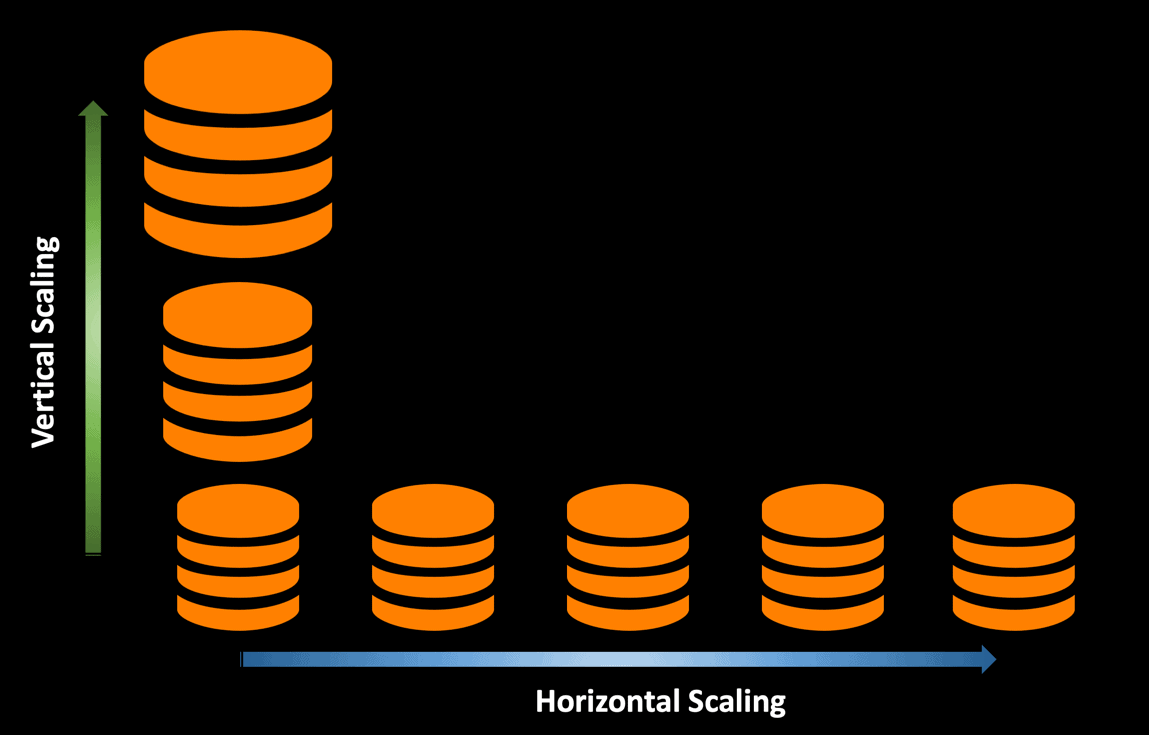
Horizontal Scaling
If you want to handle more user requests or process an increased workload which is beyond the capabilities of a single database instance, you can leverage the benefits of scaling out your database instances by implementing horizontal scaling.
There are a number of ways to scale your database horizontally –
- Adding read replicas to handle Read-Heavy workloads.
- Reading from the cache before hitting the primary DB to reduce database load.
- Sharding your database into multiple servers to improve both read and write performance.
In a cloud environment, you have the flexibility of scaling out your database based on the load. You won’t be stuck with a large database instance when the load decreases. You can always scale in and out based on the load. There is a cost associated with auto-scaling, however, it’s directly proportional to the traffic and workload your application receives.
While rightsizing the database instance size, you can run performance load tests to find the most optimal read-write performance metrics based on the business requirements and SLAs defined. However, having horizontal scaling in place will help you to dynamically scale based on the load spike and be good custodians from a cost perspective. If you have a steadily increasing workload, then scaling vertically makes sense. However, if you have a spiky nature of workload, scaling horizontally seems to be the preferred approach.
Database Read Replicas
A read replica is just a read-only copy of your database, and each replicated instance has the full set of data. Using read replicas is an excellent technique to offload the database read operation from the primary master instance and hence process more user requests. From an application perspective, the database queries can now be routed to the read replicas which results in enhanced performance.
The primary purpose of the read replicas is to provide scalability and support the read traffic and improve the performance of read-heavy workloads. Any update to the primary DB instance is automatically replicated to the associated read replicas. However, there can be scenarios where you might experience a replication lag, and hence should be aware of it.
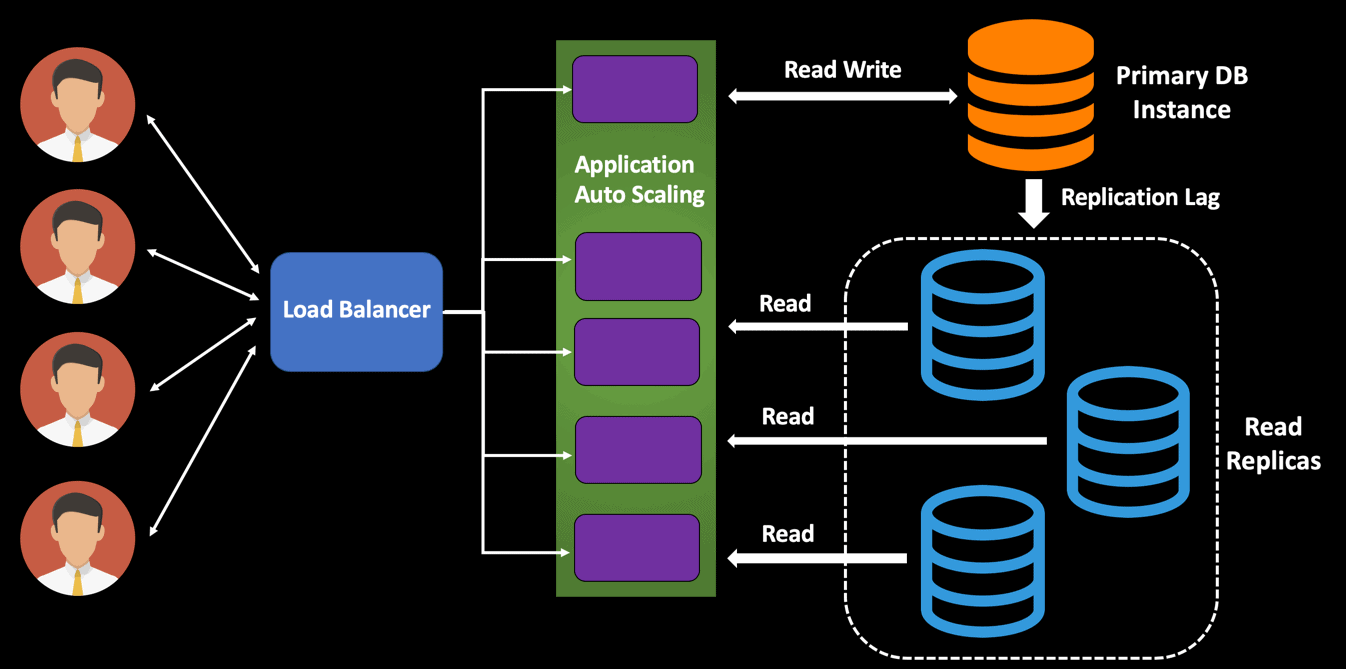
In the architecture shown in the above diagram, if one of the read replicas goes down, then the user traffic is routed to rest of the available read replicas. If the primary DB instance goes down, then one of the read replicas is promoted as the new primary DB instance and will accept both read and write traffic. You can configure a number of read replicas for your database and direct all the reads to those nodes. You will have a primary write node, and all the replicas are updated with any changes made to the primary. There will be a slight replication lag between the primary instance and the replica instances. In disaster scenarios, you have multiple reliable copies of your database in different regions. Hence it provides increased database availability.
The cloud infrastructure is built around geographical regions, where each region consists of multiple availability zones. With Multi-AZ deployments, any updates to the master database instance are synchronously replicated to another instance in a different availability zone. This allows customers to run their production workload with fault tolerance compared to data center failures.
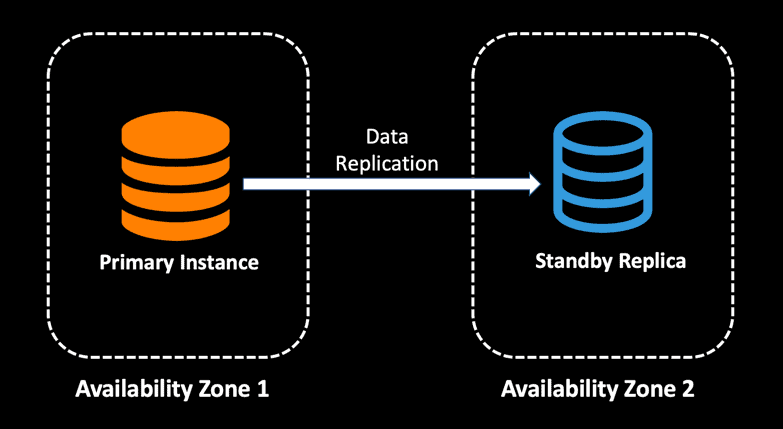
The primary purpose of Multi-AZ database deployments is high availability. You can combine read replicas with Multi-AZ deployments so that you can also have multiple reliable copies of your database in different availability zones to provide increased database availability. Since all the read replicas will be accessible to the application, the architecture below can additionally be used for read scaling.
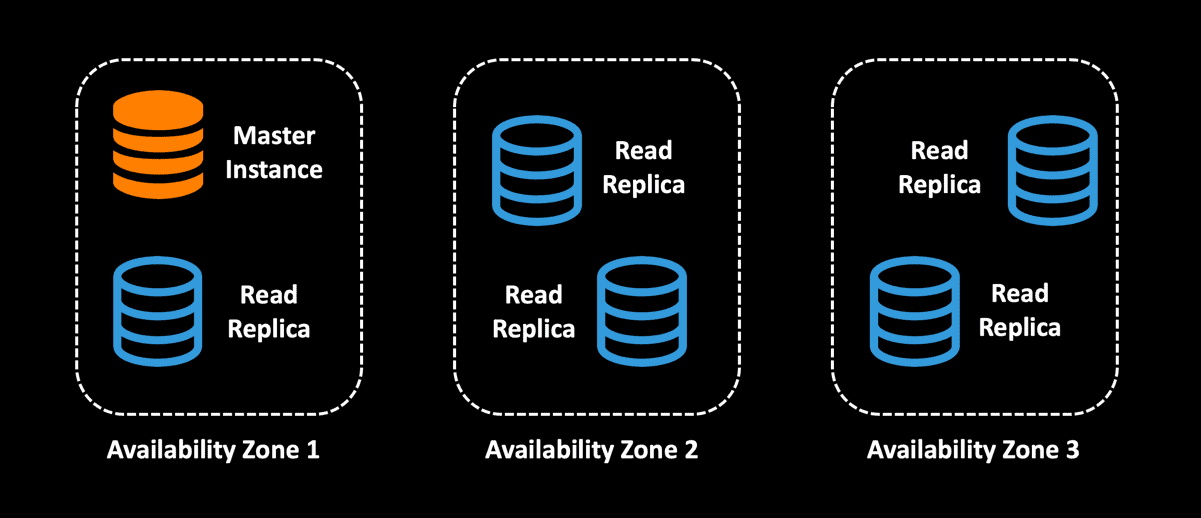
From a cost perspective, a read replica has the same price as the standard primary DB Instance. However, once you have an autoscaling policy defined for your read replicas, you can ensure that you are not paying for the additional read replicas when there is no load. Keep in mind that with read replicas, you can increase the read throughput of your application but not the write speed, since you are still writing only to the primary master DB instance.
Database Caching
While building distributed systems that require blazing fast performance, it is critical to improve the database performance to match the SLA requirements. An effective caching strategy can help to improve your application performance and reliability by reducing the overhead on the database while optimizing for cost. You can keep the frequently accessed data in an in-memory cache and save the roundtrip to database. To fetch the data from the database you need to execute a stored procedure or query involving multiple tables, which might be an expensive operation. Instead of making this database call every time, you can store the value in the cache, and the next time this data is required, you can return it with sub-millisecond latency.
In a microservice architecture, when you have several dependent services, a well-designed caching strategy can decrease the network cost and improve application performance. When a user makes a request, the cache is first checked for the data, and, if it is available, it is fetched from the cache itself. This saves the roundtrip to the database reducing any latency associated with the database call.
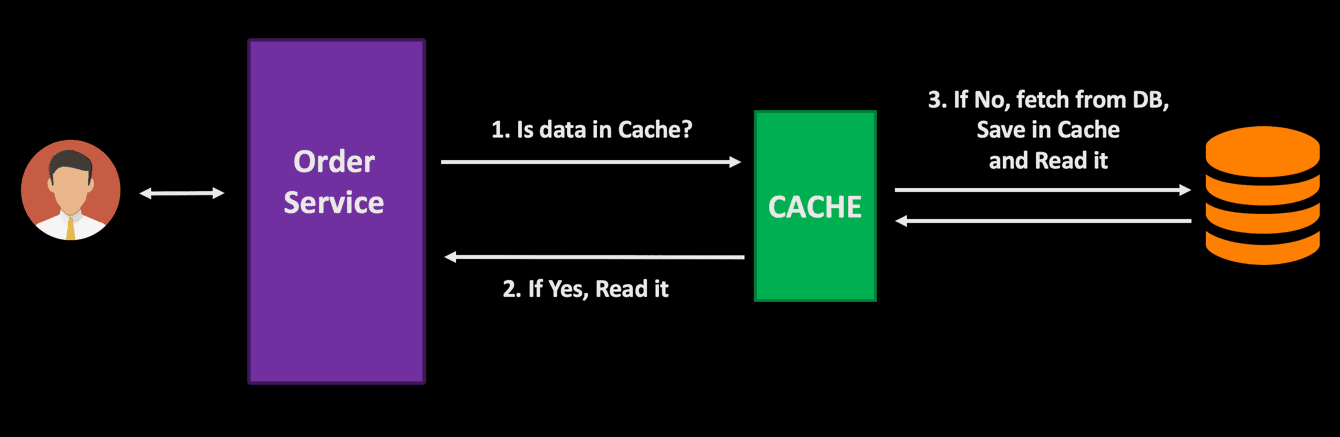
You can improve the performance of the database by using advanced query optimization techniques, but for frequently accessed data you can reduce the load on the database and improve response time by storing and fetching it from an in-memory cache. Based on the performance requirements and data access pattern, you can finalize your own caching strategy – what data to cache, how long to store in cache, etc.
Database Sharding
When your application receives a lot of traffic and continues to grow in size, at some point you would want to start thinking about ways to optimize the database performance. Sharding is a potential solution to this problem scenario where you can scale out even the write transactions to your database. Sharding can be defined as partitioning of data across servers to meet the high scalable needs of the modern-day distributed systems so that you can manage data volume efficiently. This improves both the read and write performance of the data store since each database is handling fewer volumes of data. You can visualize a shard as an individual database.
With sharding, data is split into a number of nodes based on a shard key. Each shard contains a subset of data, making it faster to manage data across all shards. Any queries executed are run in parallel across all shards. In simple words, sharding can be viewed as horizontal partitioning, where you distribute data across multiple data stores to achieve horizontal scalability.
A real-life use case scenario can be sharding a customer database based on customer ID so that you can isolate the processing of customers based on the business requirements.
Determining how to identify your shard key to distribute your data is critical, and you can go with a number of approaches:
- Shard your customer database with customer ID.
- Shard your customer database with an alphabetical filter on the customer last name.
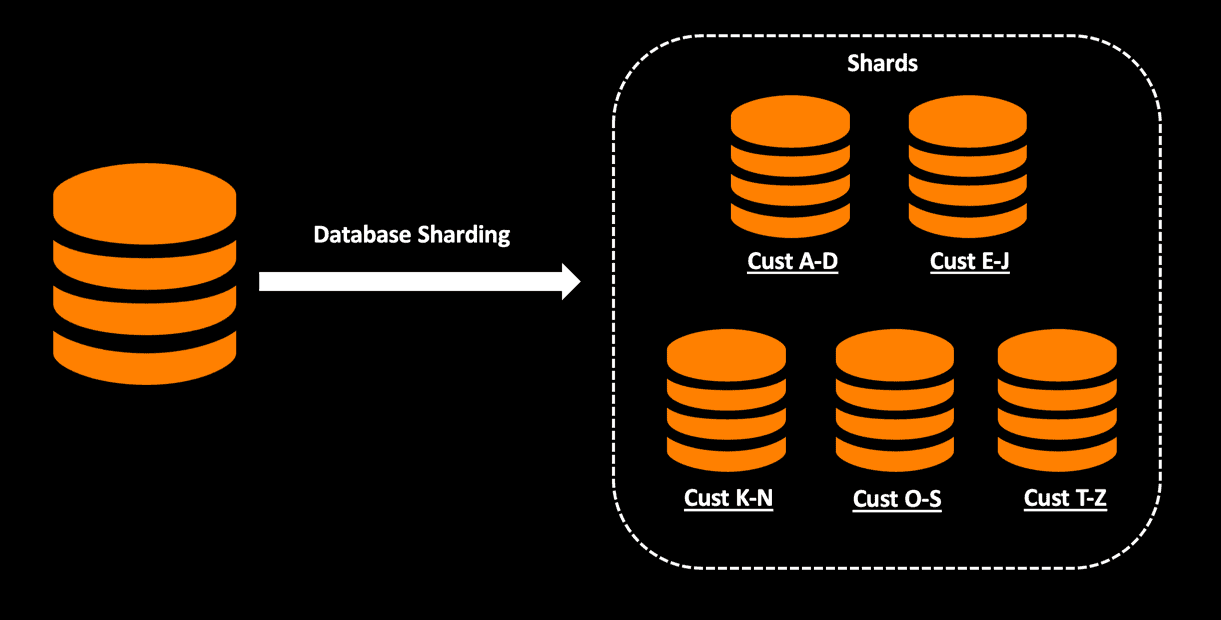
A drawback found the above range hashing strategy is that it causes an imbalance in the shard size. Partitioning the data based on customer ID or last name can result in unequal data volume in different shards. To address this problem, you can shard based on a hash strategy. You can use a hash match algorithm for hashing on an entity field. A router containing the mapping information can be used to distribute the request to the correct shard based on the hash key.
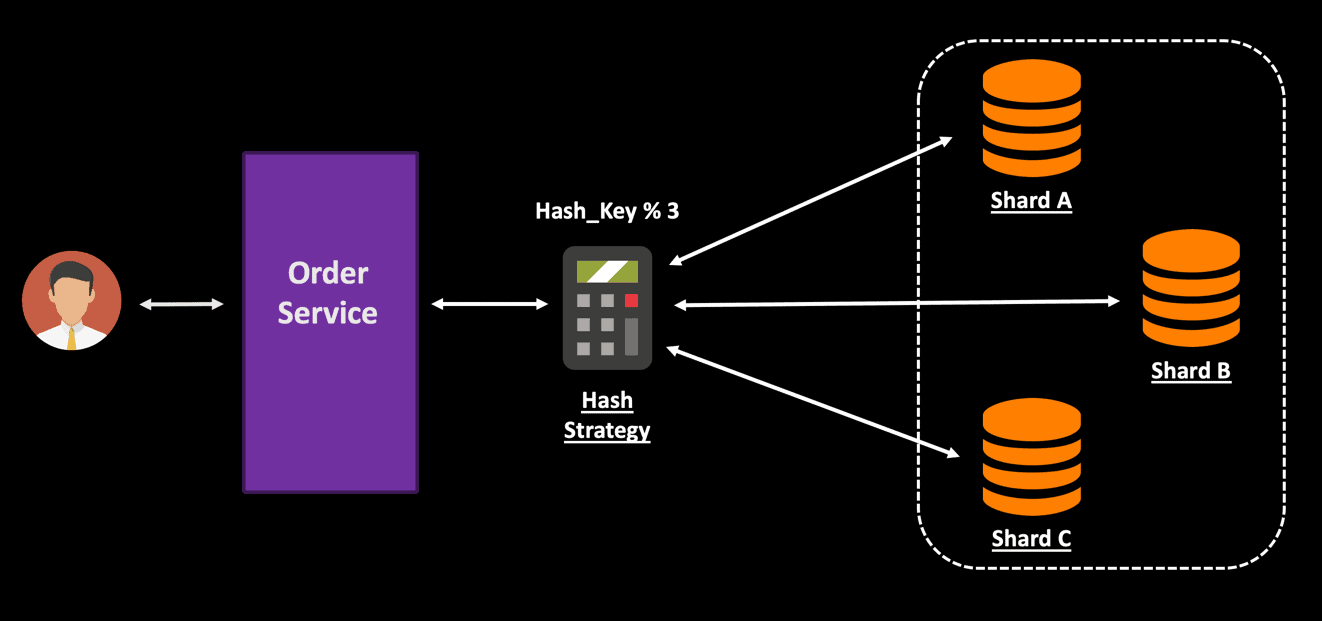
To implement sharding, you will need to make significant application level changes, and having an optimal sharding technique is critical. Sharding does bring in some complexity when you have some complex querying involving multiple shards. If it cannot leverage the shard key, then the query is executed against all the shards, and the response is gathered and sent back to the user. You should also ensure that you don’t have the shard allocation imbalance, and that data is evenly distributed among the existing shards.
Database Design in a Microservice Architecture
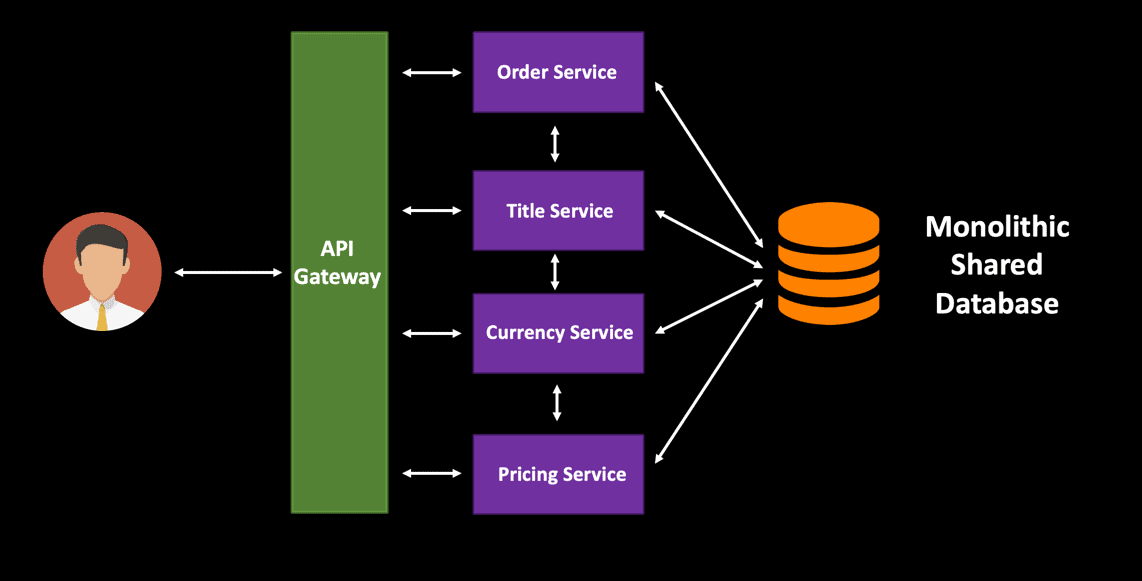
Handling database changes in a microservice architecture is challenging. When you are designing your cloud-native services, it is important to have each individual microservice have its own separate database. This will enable you to deploy and scale your microservices independently. In the diagram below, all four services will have different loads, and hence it makes sense to have separate data stores. This type of design can be termed as a decentralized data management architecture and is a very common pattern while developing highly scalable distributed systems.
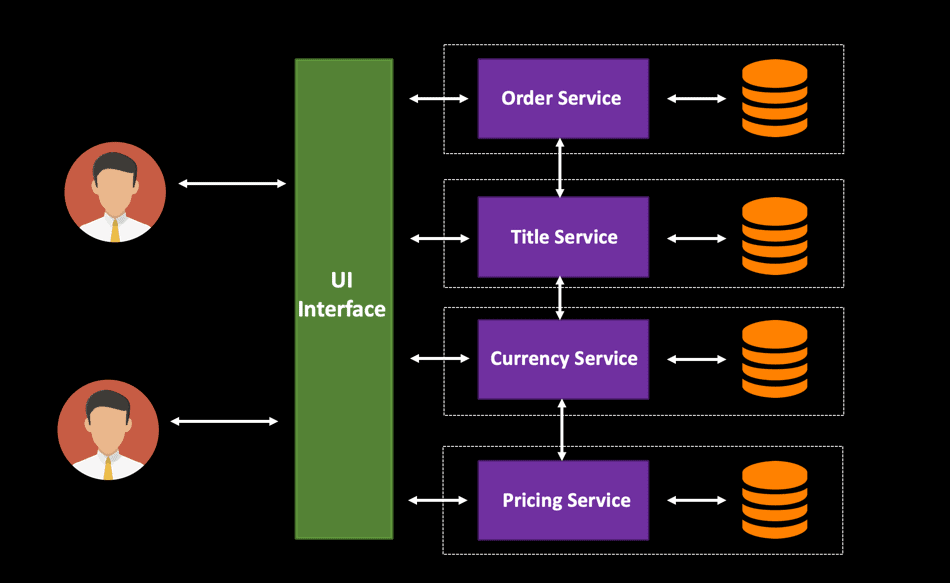
When these services have a single monolithic shared database, it is very difficult to scale the database based on the traffic spike. This design pattern is common with traditional applications where data is often shared between various components. However, the tight coupling between the services will be a hindrance to deploying service changes independently. The only option you have is to scale out the entire monolithic database – you cannot scale an individual component.
Summary
Scalability is an essential trait while designing cloud native applications. With all the technology advancements, it is imperative for business systems to be able to handle workload fluctuations without any performance degradation. No matter how well the applications are designed, if the databases are not scalable, then you are bound to bump into performance issues while processing user requests. Dynamic scaling of databases is required to be able to process the load within SLAs that are defined by the business.
When you are designing cloud-native applications, it is better to keep scalability in mind right from the beginning and should not be treated as an afterthought. Each use case is different. Depending upon your business use case, you can weigh in the pros and cons of horizontal and vertical scaling and make an informed decision on what might be the best fit for you. From my experience, vertical scaling is not the optimal solution for a cloud native application which continuously deals with a huge volume of data. With increasing load, you will need the ability to scale without being restricted. Horizontal scaling is my favorite because of its ability to dynamically auto-scale based on load with optimal performance. It is a more cost-effective solution to handle database scaling since you are not stuck with paying for the maximum load scenarios. You have the flexibility of scaling in and out based on the usage.

Load comments