If you are a conscientious database developer, you will be checking the execution plan of your queries to see if any optimization improvements are possible. You might expect an update of outdated statistics after loading a bunch of data into a table, but discover that with the query you are executing, the cached plan does not then update the statistics.
When you look into the Online Help of Microsoft SQL Server about statistics update, you will find the following statement: “The query optimizer checks for out-of-date statistics before compiling a query and before executing a cached query plan. Before compiling a query, the query optimizer uses the columns, tables, and indexed views in the query predicate to determine which statistics might be out-of-date. Before executing a cached query plan, the Database Engine verifies that the query plan references up-to-date statistics.” (https://msdn.microsoft.com/en-us/library/bb522682.aspx).
This article will describe the “intelligence” of the SQL Server query optimizer when it comes to the decision that it doesn’t actually need updated statistics to determine an appropriate plan for a query and so doesn’t update an out-of-date statistics object.
Why does SQL Server use statistics?
The query optimizer of Microsoft SQL Server is a cost-based optimizer. The calculation of costs depend on several facets of information. One of the most important of these is the information about the number of rows that are expected to be returned when the query is executed. This information is gleaned from what is called ‘statistics’. If statistics are not accurate enough, the query optimizer of Microsoft SQL Server may choose an inappropriate execution plan and if it overestimates the number of records, it will allocate too much memory for the execution.
The AUTO_UPDATE_STATISTICS option is a database setting. When this option is set, the query optimizer checks whether the statistics are outdated in a statistics object before basing a plan on it. Statistics are judged to be outdated when, roughly, the following condition is true:
- The index / statistic has more than 500 unique entries
- >= 500 + 20% of cardinality values have been changed
(https://support.microsoft.com/en-us/kb/195565)
Note
The demo scripts in this article will use undocumented trace flags. If you want to replay the demos please remember not to do the replay in a production environment. The following trace flags will be used within the scripts:
- TF 3604: The output of information will be rerouted to the client instead of the error log
SQL Server <= 2012
- TF 9204: statistics which end up being fully loaded and used[1]
- TF 9292: statistics objects which are considered ‘interesting’ by the query optimizer[2]
SQL Server 2014
- TF 2363 statistics being loaded
Test environment
The test environment is a Microsoft SQL Server 2012 EE (11.0.6020) and uses a table called dbo.Customer with app. 10,500 records. If you run the example with SQL Server 2014 make sure to use the appropriate TF in this case. The table uses two indexes. A unique clustered index is on the ID attribute and an additional non-unique non-clustered index is used for the attribute ZIP.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
-- Create the demo table IF OBJECT_ID(N'dbo.Customer', N'U') IS NOT NULL DROP TABLE dbo.Customer; GO CREATE TABLE dbo.Customer ( Id INT NOT NULL IDENTITY (1, 1), Name VARCHAR(100) NOT NULL, Street VARCHAR(100) NOT NULL, ZIP CHAR(5) NOT NULL, City VARCHAR(100) NOT NULL ); GO -- and fill it with ~10,000 records INSERT INTO dbo.Customer WITH (TABLOCK) (Name, Street, ZIP, CIty) SELECT 'Customer ' + CAST(message_id AS VARCHAR(10)), 'Street ' + CAST(severity AS VARCHAR(10)), severity * 1000, LEFT(text, 100) FROM sys.messages WHERE language_id = 1033; GO -- than we create two indexes for accurate statistics CREATE UNIQUE INDEX ix_Customer_ID ON dbo.Customer (Id); CREATE NONCLUSTERED INDEX ix_Customer_ZIP ON dbo.Customer (ZIP); GO -- what statistics will be used by different queries -- result of implemented statistics SELECT S.object_id, S.name, DDSP.last_updated, DDSP.rows, DDSP.modification_counter FROM sys.stats AS S CROSS APPLY sys.dm_db_stats_properties(S.object_id, S.stats_id) AS DDSP WHERE S.object_id = OBJECT_ID(N'dbo.Customer', N'U'); GO |

The image shows the two statistics objects with accurate values. The [modification_counter] indicates no actual changes to the cardinality values. The clustered index is a unique index but the nonclustered index is not. You’d then probably want to investigate the distribution of data within this latter non-clustered non-unique index. The following command must be executed in order to see the data in the histogram of the statistics:
|
1 2 3 |
-- show the distribution of data in the statistics DBCC SHOW_STATISTICS ('dbo.Customer', 'ix_Customer_ZIP') WITH HISTOGRAM; GO |
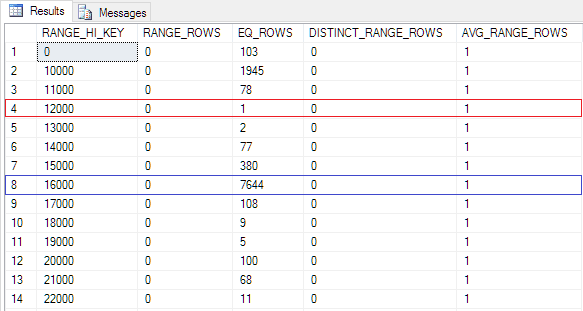
The distribution of the cardinal values is irregular. While the ZIP 12000 is represented with only one record the ZIP 16000 has a distribution of more than 7,500 records in the index. The number of rows returned by a query that uses this index will vary wildly depending on the value(s) of the ZIP requested in the WHERE clause. A parameterized query against the ZIP could therefore easily cause ‘parameter sniffing’ problems because but the ‘parameter sniffing’ issue might be better as the topic for another article.
Queries
When the table has been created and filled with data, the test queries can start. Two parameterized queries will be fired against the table using sp_executesql. Both queries will address different indexes. Both queries will use the “=” operator for the predicate for a highly selective result.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
-- TF for SQL Server 2012! DBCC TRACEON (3604, 9204, 9292); GO DECLARE @stmt NVARCHAR(1000) = N'SELECT * FROM dbo.Customer WHERE Id = @Id;'; DECLARE @parm NVARCHAR(100) = N'@Id INT'; EXEC sp_executesql @stmt, @parm, 10; GO DECLARE @stmt NVARCHAR(1000) = N'SELECT * FROM dbo.Customer WHERE ZIP = @ZIP;'; DECLARE @parm NVARCHAR(100) = N'@ZIP CHAR(5)'; EXEC sp_executesql @stmt, @parm, '18000'; GO DBCC TRACEOFF (3604, 9204, 9292); GO |
The first query used the index [ix_customer_id] for an INDEX SEEK and the second query used a performant INDEX SEEK on the index [ix_customer_zip] as is shown by the execution plans.
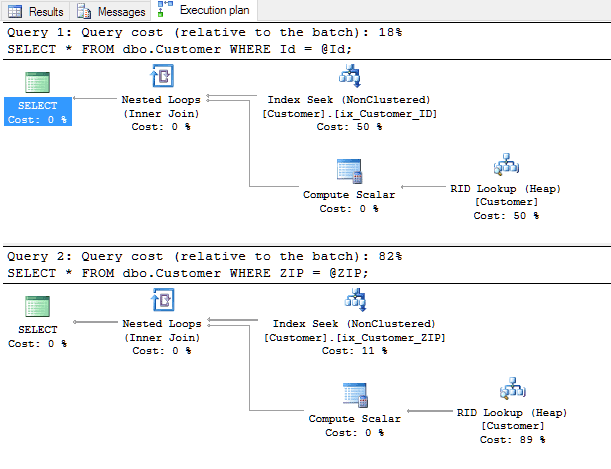 Unique Index
Unique Index
A query with an “=”-operator on a unique index will always result in an INDEX SEEK with a predictable result of ONE record. We can be confident of this prediction.
Non-Unique Index
The query on a specified ZIP can lead to a widely-varying number of records in the result set. This can lead to different execution plans depending on the prediction for this number. If there is a high cardinality the query optimizer will always choose an INDEX SEEK. If the amount of data is likely to be greater, an INDEX SCAN may be the result, because the overall plan would be likely to perform better.
In contrast to the usage of a unique index, a non-unique index for an uneven distribution provides more of a problem for the optimizer in devising a good execution strategy because the predicted number of records returned will be different for every single value of the predicate!
Changing data for outdated statistics
With 10,557 actual records in the statistics data, a minimum of 1,612 entries (INSERT, UPDATE, DELETE) have to be changed to mark the statistics as being outdated: 10.557 * 20% + 500. The upcoming code will insert 4,000 additional records into the table.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
-- additional 4,000 records will be inserted into the table -- to make the stats become outdated! INSERT INTO dbo.Customer WITH (TABLOCK) (Name, Street, ZIP, City) SELECT TOP 4000 'Customer ' + CAST(message_id AS VARCHAR(10)), 'Street ' + CAST(severity AS VARCHAR(10)), severity * 1000, LEFT(text, 100) FROM sys.messages WHERE language_id = 1033; GO |

The result shows that 4,000 records for each index have been modified. This counter value remains in the statistics until the query optimizer runs another query against the relevant index object and checks the number of changes that have occurred since the statistics were last updated. If the number of changes is higher than the threshold, the statistics will then be updated and the query plan based on the old values will become invalid. A new plan will be generated, based on the new statistic values. The Online Help of Microsoft SQL Server tells us that the statistics for both indexes will be refreshed when the queries will be executed again.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
DBCC TRACEON (3604, 9204, 9292); GO DECLARE @stmt NVARCHAR(1000) = N'SELECT * FROM dbo.Customer WHERE Id = @Id;'; DECLARE @parm NVARCHAR(100) = N'@Id INT'; EXEC sp_executesql @stmt, @parm, 10; GO DECLARE @stmt NVARCHAR(1000) = N'SELECT * FROM dbo.Customer WHERE ZIP = @ZIP;'; DECLARE @parm NVARCHAR(100) = N'@ZIP CHAR(5)'; EXEC sp_executesql @stmt, @parm, '18000'; GO DBCC TRACEOFF (3604, 9204, 9292); GO |
![]()
The result may be surprising. The first query didn’t force an update of the statistics; these have not been touched again by the query optimizer. The second query against the ZIP has forced an update of the underlying statistics. The statistics have been found as “interesting” and therefore checked. A closer look to the statistics object of the indexes shows the situation.
|
1 2 3 4 5 6 7 8 9 |
SELECT S.object_id, S.name, DDSP.last_updated, DDSP.rows, DDSP.modification_counter FROM sys.stats AS S CROSS APPLY sys.dm_db_stats_properties(S.object_id, S.stats_id) AS DDSP WHERE S.object_id = OBJECT_ID(N'dbo.Customer', N'U'); GO |

While the statistics for ix_Customer_ZIP have been updated and the new records are now part of the [rows] the outdated statistics for the unique index has not been touched.
What is the reason for that behavior?
Unique index
When a unique index is requested on its key attribute, it is not necessary for Microsoft SQL Server to obtain any statistics when the requested data are searched by an “=” operator. In this case Microsoft SQL Server will always “know/estimate” that only one record will be returned. If the operator for the predicate is forcing a range scan in the index the statistics need to be accurate because for one reason; the amount of data in between two predicates “may” vary! For the above example, the statistics would not have been required in order to execute the query because a compiled plan is already available in the plan cache. Microsoft SQL Server checks for a valid plan in the plan cache and will reuse it if it is available. A further check for statistics is not necessary because the plan with all its estimates is stable.
Non-Unique Index
For the second query against the ZIP-Code, the stability looks doubtful. The index does not guarantee unique values. The amount of data returned for each key value in the index may vary. The plan is ‘unstable’ in terms of the amount of data returned by the query using the plan with different values for a key attribute. If the plan is not stable, Microsoft SQL Server has to refresh the information about the statistics in order to determine whether a new plan is required. Therefore it checks the statistics before using the cached plan, finds that the threshold for auto-refresh of the statistics has been exceeded and so updates the underlying statistics.
Conclusion
Statistics are important and necessary for well-performing queries. Outdated statistics that no longer reflect the current distribution of data in the table are very often the reason for badly-performing queries because the query optimizer chooses the best plan based on the information in the statistics.
The query optimizer can recognize when a reload of updated statistics is required. If the predicate of a query runs against a unique key value of the index, the query processor is aware of it and does not load the statistics again. If the query is dealing with “unsafe” predicates which require INDEX SCANs, statistics have to be reloaded because the amount of records may change.
Load comments