
When you’re working with T-SQL, you’ll often see SET NOCOUNT ON at the beginning of stored procedures and triggers.
What SET NCOUNT ON does is prevent the “1 row affected” messages from being returned for every operation.
I’ll demo it by writing a stored procedure in the Stack Overflow database to cast a vote:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
CREATE OR ALTER PROC dbo.usp_InsertVote @PostId INT, @UserId INT, @VoteTypeId INT AS BEGIN INSERT INTO dbo.Votes(PostId, UserId, VoteTypeId, CreationDate) VALUES (@PostId, @UserId, @VoteTypeId, GETDATE()); UPDATE dbo.Users SET LastAccessDate = GETDATE() WHERE Id = @UserId; END GO EXEC usp_InsertVote 1, 1, 1; |
When this stored procedure runs, it does two things: insert rows into Votes, and update rows in Users. When it finishes, it returns two messages in SSMS:

However, if I add SET NOCOUNT ON at the top of the stored procedure:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE OR ALTER PROC dbo.usp_InsertVote @PostId INT, @UserId INT, @VoteTypeId INT AS BEGIN SET NOCOUNT ON /* <---- This is new */ INSERT INTO dbo.Votes(PostId, UserId, VoteTypeId, CreationDate) VALUES (@PostId, @UserId, @VoteTypeId, GETDATE()); UPDATE dbo.Users SET LastAccessDate = GETDATE() WHERE Id = @UserId; END GO |
Then those messages go away, and SQL Server just reports that the query completed successfully:
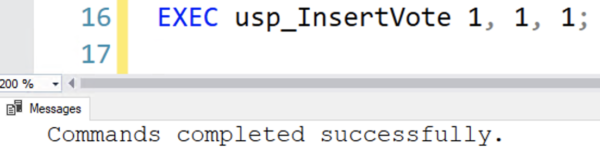
This means less data gets sent from SQL Server, across the network, over to the application.
How much less data? Well, honestly, not a lot. In most cases, this isn’t a heroic performance change because it doesn’t make a meaningful performance difference. However, if you have code that works in a loop, or modifies a lot of different tables, then it starts to matter more.
You might say to yourself, “Well, then, I only need to add it when I’m working in a loop, or when I’m modifying a lot of different tables.” However, you can’t always predict who’s going to call your code, and they might run YOUR code in a loop – and in that case, reducing the message overhead helps.
That’s why it’s a good practice to start every stored procedure with SET NOCOUNT ON. Get in the practice, and it’s one less thing you’ll have to worry about as your workload scales.

13 Comments. Leave new
Because I’ve seen/heard people claim it elsewhere, worth noting that “SET NOCONT ON” does NOT stop @@ROWCOUNT counting. Even though it’s so easy to test, some people genuinely seem to believe this.
Also, if there’s any chance that something like Tableau could be utilizing your stored procedure, you need to make sure to SET NOCONT ON otherwise the messages interfere with the application.
Dell’s Boomi is also handicapped the same way.
Also this happens with Pega BPM – some of our Pega specialists did not realize this!
its also good for developers that don’t know how to ignore messages in their return sets.
Totally agree, Question do you never set it off when the Proc finished?
No need, the setting only affects the statements within the stored procedure.
(smiles) Even if I do not use it – good to know. Might be on a test somewhere or an interview question 🙂
I’ve had cases where an old C program would stack inserts into a loop before sending it to SQL. But there was so many “1 row affected” to be returned by SQL Server that it would stop executing the inserts in the middle of the execution because of that.
It took the developers days to realize that that’s what was happening. Adding the “SET NOCOUN ON” fixed the problem. At the same time, we also decided it would be a good idea to execute the inserts every 4000 rows or so, just to avoid putting so much at the same time.
Of course, you would ask why they didn’t do a bulk insert or something like that. But it was a very old app and they could not rewrite it. At least we made it work 😉
Yep, agreed (as usual:), ths is part our name convention and best practice recommendation: https://github.com/ktaranov/sqlserver-kit/blob/master/SQL%20Server%20Name%20Convention%20and%20T-SQL%20Programming%20Style.md#nocount
BUT Brent you forgot add semicolons 🙂 https://github.com/ktaranov/sqlserver-kit/blob/master/SQL%20Server%20Name%20Convention%20and%20T-SQL%20Programming%20Style.md#semicolon
Right version is:
SET NOCOUNT ON;Also Do not use
SET NOCOUNT OFF;because it is default behavior.Some nice testing article with real overhead detetcted: http://sql-sasquatch.blogspot.com/2017/11/hey-whats-deal-with-nocount-and-t-sql.html
And it is Microsoft recommendation: https://docs.microsoft.com/en-us/sql/t-sql/statements/create-procedure-transact-sql?view=sql-server-ver15#best-practices
The default is also problematic in Python, when using pyodbc w/ a stored procedure
https://stackoverflow.com/questions/26132718/read-stored-procedure-select-results-into-pandas-dataframe
With 300 Saas based instances, this is an easy win for mass upgrades. It cuts down on network and with that many databases it just makes for too much information when a good error log provides so much more information.
Erland Sommarskog has a very long explanation as to why it should
NOT only be
SET NOCOUNT ON
but
SET XACT_ABORT, NOCOUNT ON
See https://www.sommarskog.se/error_handling/Part1.html#jumpXACT_ABORT
I think you would want to recommend that too, if you take the time to read the link.