
Jonathan Lewis' continuing series on the Oracle optimizer and how it transforms queries into execution plans:
- Transformations by the Oracle Optimizer
- The effects of NULL with NOT IN on Oracle transformations
- Oracle subquery caching and subquery pushing
- Oracle optimizer removing or coalescing subqueries
- Oracle optimizer Or Expansion Transformations
In my first article on transformations, I described how Oracle liked to minimize the number of query blocks that the optimizer had to handle. I presented the example of an IN subquery in the where clause that Oracle would rewrite as the equivalent EXISTS subquery before unnesting the subquery to produce a join. The join might be a semi-join or partial join but might include an in-line aggregate view, which might be further transformed by complex view merging. This article considers effects of NULL with NOT IN on Oracle transformations.
There are many more transformations that the optimizer can apply to subqueries, but before moving on to any of the more subtle and complicated transformations, it’s important to look at the effects of nulls and the impact they have when IN is changed to NOT IN.
To be or not to be
Or, to relate Hamlet’s question to subqueries and the optimizer: IN or NOT IN. Before pursuing the topic of subqueries any further, it’s important to keep in mind that there is an essential difference between IN subqueries and NOT IN subqueries. While NOT EXISTS is the opposite of EXISTS, NOT IN is not the exact opposite of IN and if you forget this you may end up rewriting a query in a way that produces the wrong results.
The problem is best explained with a basic definition followed by a simple example:
IN()is equivalent to equalsANY()NOT IN()is equivalent to not equal toALL()
Think about what happens if the result set of your subquery includes a NULL – to keep it simple you can start with a list of values rather than a subquery then consider the two expressions:
- 3 IN (1, 3, 5, null)
- 4 NOT IN (1, 3, 5, null)
The first expression expands to (3 = 1) or (3 = 3) or (3 = 5) or (3 = null).
The second expression expands to (4 != 1) and (4 != 3) and (4 != 5) and (4 != null)
Because the first expression is a list of disjuncts (OR’s) it evaluates to TRUE if any of the atomic expressions evaluates to TRUE; in fact, at runtime Oracle will stop checking as soon as it finds the first expression that evaluates to TRUE (i.e. 3 = 3).
Because the second expression is a list of conjuncts (ANDs), it evaluates to TRUE only if every atomic expression evaluates to TRUE. The first three expressions evaluate to TRUE, but the last expression in the list is 4 != null, which evaluates to UNKNOWN, so the compound expression evaluates to FALSE.
To the human eye, the value 4 is clearly not in the list, but the Oracle database (or any other relational database) doesn’t interpret NOT IN the way the human eye does.
This script will build the last example into a simple Oracle model:
|
1 2 3 4 5 6 7 8 9 10 |
create table t1 (n1 number); create table t2 (n2 number); insert into t1 values(4); insert into t2 values(1); insert into t2 values(3); insert into t2 values(5); insert into t2 values(null); commit; execute dbms_stats.gather_table_stats(user,'t1') execute dbms_stats.gather_table_stats(user,'t2') |
My table t1 holds a row with the value 4, and my table t2 does not. I’m going to start by querying t1 for all the values that are IN table t2, then for all the values that are NOT IN table t2 – here are the queries with results cut and pasted from an SQL*Plus session running 19.11:
|
1 2 3 4 5 6 |
SQL> select * from t1 where n1 in (select n2 from t2); no rows selected SQL> SQL> select * from t1 where n1 not in (select n2 from t2); no rows selected SQL> |
Whether you ask for IN or NOT IN, you get no rows – NOT IN is not the opposite of IN if the subquery can return nulls. You can confirm this point by executing two more statements:
|
1 2 3 4 5 6 7 8 |
SQL> delete from t2 where n2 is null; 1 row deleted. SQL> SQL> select * from t1 where n1 not in (select n2 from t2); N1 ---------- 4 1 row selected. |
When deleting the null row from t2, the not in version of our query returns the 4 row.
Execution plans
It’s very easy to forget about the impact of nulls and the benefits of declaring mandatory columns as not null. Nulls introduce all sorts of problems (to people and to the optimizer). Over the years, the optimizer has been enhanced to work around some of the performance problems they used to produce.
Side note: Oracle handles not null column declarations differently from “(column is not null)” check constraints, and a not null declaration may allow the optimizer to consider extra execution paths that it would not otherwise be allowed to use. You may find that a simple not null declaration makes a huge difference to performance.
When looking at the execution plan from the first example with the NOT IN subquery, you can see Oracle giving a little warning about the presence of nulls and the impact it might have on our processing:

The optimizer has chosen to use a hash anti-join. The significance of the ANTI is that the test fails if the search succeeds – the predicate for operation 1 must fail for every row in t2 before the t1 row can be reported. But there’s a further label to the hash join operation: NA, for null-aware, which shows that Oracle is taking some sort of defensive action during the hash join to avoid making mistakes with nulls.
This suggests another way of understanding what’s going on. You’ve seen that IN and NOT IN aren’t exactly opposites, and you saw in the previous article that non-correlated IN subqueries could be turned into correlated EXISTS subqueries. Add the null row back into t2 and see what the execution plan looks like if you assume (incorrectly) that you can rewrite our non-correlated NOT IN subquery as a correlated NOT EXISTS subquery:
|
1 2 3 4 5 |
SQL> select * from t1 where not exists (select null from t2 where t2.n2 = t1.n1); N1 ---------- 4 1 row selected. |
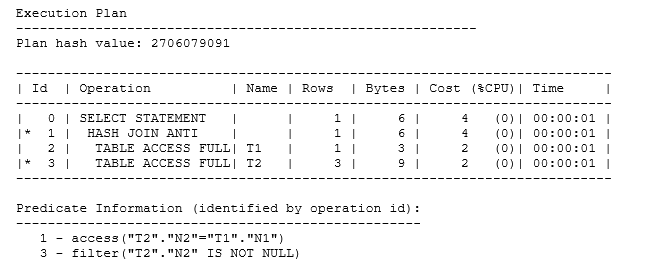
The result from NOT EXISTS disagrees with the result from NOT IN, and the plan doesn’t quite match the NOT IN plan. Operation 1 (hash join anti) is not labeled as Null-aware (NA), and there’s a predicate at operation 3 that stops any null(s) from t2 being passed up to the hash join operation. To sum up:
NOTEXISTSis the opposite ofEXISTS,- You can transform
INtoEXISTS - You cannot (in the presence of nulls) transform
NOTIN toNOTEXISTS NOTIN is not (in the presence of nulls) the opposite ofIN
You could get some idea of what is hidden behind the Null-Aware tag by keeping an eye open for any surprises in plans, predicates, or execution statistics.
For example, change the two tables to increase the volume of data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
create table t1 (n1, v1) as select case when rownum <= 200 then rownum end n1, lpad(rownum,100) v1 from all_objects where rownum <= 50000 ; create table t2 as select n1 n2, v1 v2 from t1; set serveroutput off select /*+ gather_plan_statistics leading(t1 t2) */ * from t1 where n1 not in (select n2 from t2) ; select * from table(dbms_xplan.display_cursor(format=>'rowstats last')); |
I’ve defined the two tables so that they both hold 50,000 rows, with only 200 rows with non-null values in each table. Here’s the execution plan I get from my query – reported from memory after executing it with rowsource execution stats enabled:
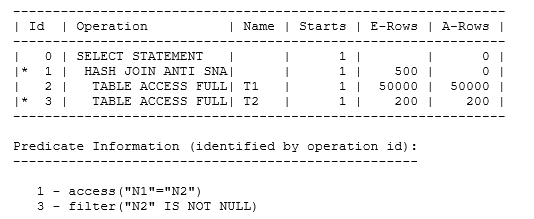
A key point to notice here is that the tablescan of t2 stopped after only 201 rows – and a couple more tests setting other rows to null show that the scan stops as soon as Oracle finds a null in t2. This makes sense of course, because as soon as Oracle finds a null in t2, the query can’t return any rows, so there’s no point in continuing.
In passing, I was a little surprised that the actual row count (A-rows) from t1 was 50,000: I had assumed before I did the test that Oracle would only build the hash table from the rows where t1.n1 was not null.
Alternative plans
After understanding Oracle’s handling of nulls and NOT IN, it’s worth taking a quick note of a couple of variations in the patterns you might see in execution plans. These variations exist because of the null-aware mechanisms as there are three possible variations with HASH JOIN ANTI operation. First, if the relevant column in the t2 (i.e. subquery) table has been defined as not null (or if you add a column is not null predicate to the subquery, you get a single null aware SNA) join:
|
1 2 |
select /*+ gather_plan_statistics leading(t1 t2) */ * from t1 where n1 not in (select n2 from t2 where n2 is not null) |

Then, if you have not null declarations or predicates for the relevant columns from both tables the join becomes a normal anti join:
|
1 2 |
select /*+ gather_plan_statistics leading(t1 t2) */ * from t1 where n1 is not null and n1 not in (select n2 from t2 where n2 is not null) |
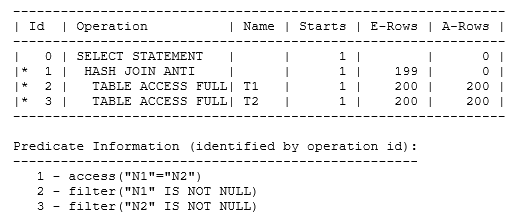
Notice how the A-Rows supplied to the hash join by the t1 tablescan is just the 200 where n1 is not null in this case.
Another case which looks quite counter-intuitive appears if the statistics, indexing, and not null conditions are right:
|
1 2 3 |
create index t2_i2 on t2(n2); select /*+ gather_plan_statistics */ * from t1 where n1 is not null and n1 not in (select n2 from t2) |
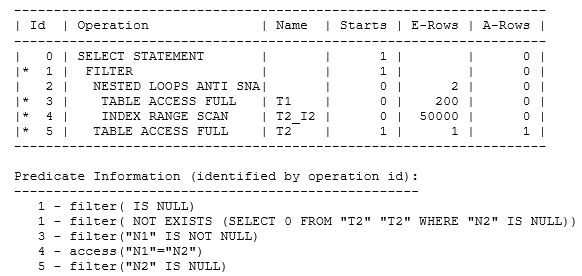
I’ve added a predicate to eliminate the null rows from t1 and created an index on the n2 column of t2, and that’s had the effect of making the optimizer think that a nested loop join would be appropriate – though it is an anti join, of course, and also single null aware. However, if you look at the shape of the plan, you can see that the optimizer has started with a filter at operation 1, for which the first child is the nested loop at operation 2, and the second child is a full tablescan of t2 at operation 5. Moreover, if you look at the Starts column in the plan, you’ll see that operation 5 has started once, but operation 2 has never been started. This is an example of something I’ve labeled the fixed subquery, and it’s an example of the rare case where the last child of a filter operation can be called first to decide whether or not the first child should execute at all.
In this case, operation 1 does convert the NOT IN subquery to a NOT EXISTS subquery (I’ve expanded the predicate at operation 1 by passing the query through explain plan to show this), but this will only give the right answer if there are no rows with nulls for n2 in table t2. So the run-time activity starts with the tablescan of t2 at operation 5 to check whether or not there are any rows with n2 = null, and as you can see Oracle has found the first null, stopped the tablescan, and then not executed the nested loop.
Finally, I’ll just point out that null-awareness is not restricted to anti-joins – you may also see (S)NA on semi-joins, though the term Oracle uses, in this case, is null accepting rather than null aware. (The feature appeared in 12.1, though I have published a note about a case that produced the wrong results until12.2). The SQL has to be a little more complex (and I’ve hinted the following example fairly heavily to produce the plan I wanted from the 50,000 row tables of the previous examples):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
select /*+ gather_plan_statistics leading(@sel$5da710d3 t1@sel$1 t2@sel$2) use_nl(@sel$5da710d3 t2@sel$2) index(@sel$5da710d3 t2@sel$2) */ * from t1 where n1 is null or exists (select null from t2 where n2 = n1) ; |
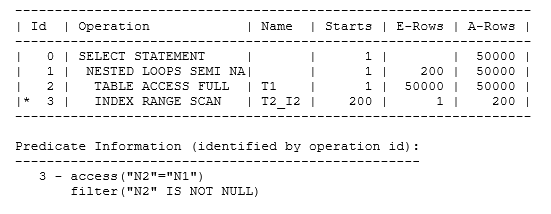
The effects of NULL on Oracle optimizer transformations
You have seen IN subqueries converted to EXISTS subqueries and learned that it is not automatically safe for Oracle (or the human programmer) to convert NOT IN subqueries to NOT EXISTS subqueries thanks to problems caused by nulls in the data. In recent versions of Oracle, the optimizer has been coded to work around some of the problems, but the side effects may produce plans that have to be less efficient than you might expect and plans that might have extra operations that seem to be redundant.
Join operations with the suffix NA (null-aware/accepting) or SNA (single null-aware/accepting) are clues that the plan has been adjusted to allow for columns that may hold nulls. Therefore, it could be worth checking whether it would be legal to add is not null predicates to specific queries, or even to add NOT NULL declarations to relevant columns.