The series so far:
- Storage 101: Welcome to the Wonderful World of Storage
- Storage 101: The Language of Storage
- Storage 101: Understanding the Hard-Disk Drive
- Storage 101: Understanding the NAND Flash Solid State Drive
- Storage 101: Data Center Storage Configurations
- Storage 101: Modern Storage Technologies
- Storage 101: Convergence and Composability
- Storage 101: Cloud Storage
- Storage 101: Data Security and Privacy
- Storage 101: The Future of Storage
- Storage 101: Monitoring storage metrics
- Storage 101: RAID
Throughout this series, I’ve discussed a range of storage-related topics, some of which I mentioned only briefly. One of those is cloud storage, which now plays a vital role in today’s data management strategies. Organizations of all types and sizes now employ cloud storage to varying degrees, either to supplement their on-premises systems or to handle the bulk of their data. Because cloud storage has become so pervasive, this article focuses exclusively on that topic, describing what it is, how it works, and its benefits and challenges.
Cloud storage refers to a system in which data storage is offered as a service by a cloud provider, usually as part of other cloud-based services. The provider stores the data in its own data centers or leases space in third-party data centers. The data centers might be confined to one geographic area or spread out across multiple regions.
With cloud storage, the provider oversees all back-end operations that go with maintaining the storage infrastructure and delivering storage services. A team of experts manages the hosting environments, protects them and their data, and handles administrative tasks such as updating systems, implementing data protections, and ensuring availability.
For now, I’m restricting the context to public cloud storage; I cover private cloud later in this article. In the public model, customers typically pay a monthly rate based on the amount of storage space they use and on selected options such as storage type, data ingress/egress, or performance level. Customers can add or remove capacity on demand, providing them with an extremely flexible data solution.
Cloud Storage Architecture
Cloud storage is delivered through a virtualized infrastructure that logically pools physical storage resources and presents them as services that are accessible through a centralized portal for easy allocation. Customers can also interact with the storage pool through a public API that facilitates data access and management. The storage pool can span multiple servers or even multiple locations, with the data itself distributed across drives. The combination of distributed data and the operation’s inherent redundancy delivers a high degree of fault tolerance and reliability.
Figure 1 provides a conceptual overview of the cloud storage architecture. The exact implementation varies by service provider, with new technologies continuously emerging and existing ones evolving. Even so, the figure should give you a sense of how the physical storage resources are abstracted into logical storage pools that can then be consumed as part of a data management strategy.
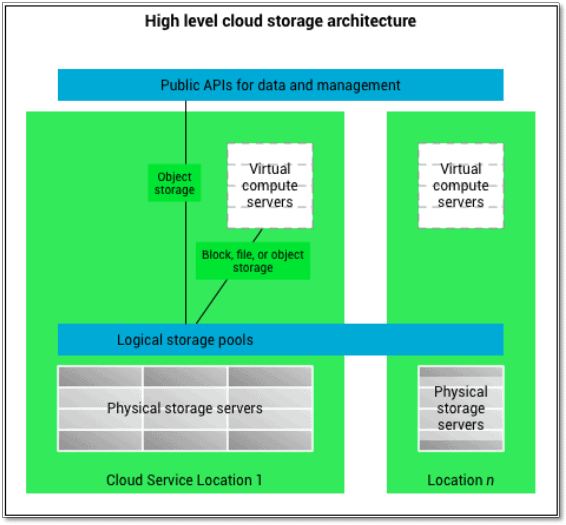
Figure 1. Cloud storage architecture (image by Leoinspace, licensed under Creative Commons Attribution-Share Alike 3.0 Unported)
Figure 1 also shows that a provider might support up to three storage types: object, block, and file. I explained each type in this first article in this series, but here’s a summary for your convenience:
- Object storage has its origins in the cloud and was developed to address the growing influx of unstructured data. In object storage, data is broken into self-contained, modular units (objects) that include identifiers and customizable metadata, which simplifies access and supports advanced analytics. Object storage does not perform as well as block storage, especially when it comes to writing data, which is why it’s a good fit for workloads that are not latency-sensitive, such as backups and archiving.
- Block storage breaks data into chunks (blocks) that include no metadata, unless you count the block’s unique identifier. Storage area networks (SANs) use block storage because it is fast and efficient, well-suited for workloads such as email servers, relational databases, and virtual desktop infrastructures. Block storage doesn’t scale as well as object storage, yet it’s still the go-to type for latency-sensitive workloads.
- File storage has the familiar hierarchical structure you find in such applications as Windows Explorer or macOS Finder. It’s the type of storage used by your everyday applications. Both direct-attached storage (DAS) and network-attached storage (NAS) commonly use file storage. It’s easy to work with and understand; however, it has strict scalability limitations and supports little metadata.
Some cloud storage providers might offer only one or two storage types, but most of today’s major players now offer all three, with object and block storage supporting the bulk of enterprise workloads.
The Tempting World of Cloud Storage
Many organizations turn to cloud storage because of its pay-for-use, consumption-based payment structure, which enables them to move from a capital expense (CapEx) model to an operating expense (OpEx) model. Not only does this eliminate the steep up-front costs that come with on-premises storage solutions, but it also avoids having to over-provision storage resources to accommodate fluctuating workloads or anticipated increases in data volumes.
With cloud storage, customers pay only for the storage they need when they need it. There might be base fees attached to the service, but these may be trivial compared to purchasing, housing, and maintaining a system on-premises. That said, cloud services costs can quickly add up, as I’ll explain in a bit.
Related to cost is the inherent elasticity of cloud storage. Customers can scale capacity up and down as their business requirements change without having to negotiate the hurdles and expenses that come with scaling on-premises systems. This elasticity also eliminates the type of over-provisioning that comes with on-premises solutions. Capacity in the cloud is almost unlimited, as long as you can afford to pay for it.
Cloud storage also has the advantage of 24×7 global availability from just about anywhere connectivity can be established, making it possible for business users and applications with an internet connection to access the data whenever they need it. They can even use protocols such as Web Distributed Authoring and Versioning (WebDAV) to map local drives to cloud storage, providing even more flexibility.
Another reason many organizations use cloud storage is that it’s incredibly user-friendly, whether you’re an administrator, developer, tester, or end-user. The centralized portal and API facilitate quick and efficient operations that make it simple to provision new storage, change existing configurations, collaborate with other users, and work with the data. Cloud storage accelerates and streamlines most of the day-to-day operations that come with on-premises storage.
Cloud storage also includes built-in data protections that address both data loss and security. As already mentioned, the built-in redundancy and distributed data lead to a high degree of fault tolerance. Cloud providers also take steps to protect against data loss and lack of availability in the event of hardware failure, natural disaster, or human error.
In addition, providers implement safeguards to ensure the data is protected from both internal and external threats, implementing such protections as monitoring, firewalls, encryption, intrusion detection, multi-factor authentication, and physical security. Most vendors recognize that their reputations are at stake and will take whatever steps necessary to avoid risking a data breach, often exceeding the protections implemented by many organizations.
The Dark Side of Cloud Storage
Despite the protections that cloud storage providers have in place, security remains one of the top reasons that organizations are hesitant to put their data out on the cloud, in no small part because of the number of big-name breaches to make the headlines. Even under the best circumstances, storing data in the cloud increases the attack surface area, with data crossing more networks, distributed to more locations, and replicated more frequently. The larger the attack surface area, the higher the chance that the data can be compromised.
Cloud providers, especially the big players, have big bullseyes painted on them, with international cybercriminals using the most sophisticated weaponry available to try to penetrate infrastructure defenses. In addition, providers must guard against internal threats, which might come in the form of espionage, rogue employees, or careless in-house practices.
Providers must also take into account privacy concerns and applicable compliance regulations. Customers have a lot at stake when it comes to protecting personal data. Compromised data can result in lawsuits, stiff penalties, and tarnished reputations from which a company might never recover. Although cloud providers have taken steps to address privacy concerns and conform to applicable regulations, many organizations still believe the risks are too great to trust their sensitive data to the cloud.
Even if organizations are comfortable with the protections that a provider offers, they must still take into account the cost of storing data in the cloud. On the surface, the CapEx model might appear an affordable alternative to on-premises storage, but a long-range analysis that calculates the true total cost of ownership (TCO) often paints a much different picture, when taking into account ongoing subscription fees, additional charges for extra capacity and performance, data transfer fees, charges for high-speed network connections, and other factors. And unlike equipment you own, you have no assets to sell once you’re done with the service.
At the same time, cloud storage also means losing control over the data. Organizations can access, update, and move their data as necessary, but they don’t get to determine when security patches are applied or maintenance windows scheduled, nor can they control how systems are optimized or when newer technologies might be implemented. The provider regulates just about every aspect of every operation related to the platform.
In addition, organizations that access their data through the Internet are at the mercy of the ebbs and flows of the endless traffic streams. To improve connectivity, they might deploy dedicated private WANs (increasing costs). However, even if they bump up the bandwidth, applications running on-premises and getting their data from the cloud can still encounter significant latency issues. Customers might find that they need to move their applications to the same cloud platform, increasing costs and adding to the risks of vendor lock-in.
Another concern with cloud storage is whether an organization can depend on the provider to remain in the cloud storage business for the foreseeable future. The company might go bankrupt, get eaten up by a by another company, change its business strategy, experience a disaster, or disappear for any number of other reasons. Not only does this put your day-to-day operations at risk, but it might also prevent you from being able to access your data.
Private and Hybrid Cloud Storage
Although many organizations have concerns about cloud storage, they like the service-based delivery model that the cloud affords, which is why some deploy private or hybrid clouds. A private cloud is a dedicated platform that offers storage and compute resources as services, similar to a public cloud. The components that make up a private cloud infrastructure might be housed on-premises or in a colocation facility, and in either case, the organization has complete control over the components.
A private cloud offers some of the same flexibility, scalability, efficiency, and ease-of-use as a public cloud, although not nearly to the same degree, especially when it comes to flexibility and scalability. Even so, the private could be a useful solution for organizations that want more control over their storage or that have strict security and compliance requirements, which is often the case for organizations such as government agencies, financial institutions, or healthcare companies.
Despite the benefits of a private cloud, implementing and maintaining the infrastructure can be a complex and costly undertaking, and organizations must be well prepared to take on such a project. Not only does this require careful planning and budgeting, but it might also mean bringing on personnel with the necessary expertise. As an alternative, some companies go with consumption-based storage, which takes a pay-as-you-go approach to delivering managed, on-premises services.
In some cases, an organization will want to deploy a private cloud but still use public cloud services for some of its storage. One option is to maintain separate operations, with the public and private clouds treated as individual efforts. However, this can increase management complexities and contribute to data siloes.
Another approach is the hybrid cloud, in which private and public cloud storage are coordinated by an orchestration layer that integrates operations across multiple platforms. With an effective hybrid cloud solution in place, an organization can maintain strict control over its sensitive data, while maximizing the advantages of both private and public cloud platforms.
There is, of course, a lot more to private and hybrid cloud systems than what I’ve covered here, as is the case with most storage-related concepts, but this should give you a sense of some of the options available for implementing cloud storage.
Making the Most of Cloud Storage
Initially, cloud storage was seen as a vehicle for reducing CapEx for smaller organizations, allowing them to store their data on a public cloud platform, without the paying for storage they did not need. Now organizations of all sizes and types are leveraging cloud storage, taking advantage of the different deployment options to support a wide range of workloads, such as disaster recovery, file archiving, DevOps development processes, seasonal fluctuations, Internet of Things (IoT) analytics, or any number of other possible use cases.
But as I mentioned earlier, cloud storage also comes with several challenges. For example, there are security and privacy concerns as well as issues related to vendor lock-in and customer control. One concern I didn’t discuss is whether the cloud will be able to handle the anticipated increase in data volumes over the next few years. But that’s a discussion I’ll leave for another time.

{kind=link}
Load comments